目录:
1.time和datetime模块
2. random模块
3. OS模块(是与操作系统交互的一个接口)
4. sys模块(sys模块是与python解释器交互的一个接口)
5.序列化模块
6.hashlib模块
7.configparser
8.logging (记录日志的模块)
9.collections模块(使用counter进行记数统计)
模块:
计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在 Python 中,一个.py 文件就称之为一个模块(Module)。
模块分类:
内置模块 python安装时自带的
扩展模块 别人写好的,安装之后可以直接使用
itchat模块(和微信相关), beautifulsoap(爬虫模块), selenium(网页自动化测试工具)
django tornado(框架)
自定义模块 自己写的模块
使用模块好处:
提高了代码的可维护性。
当一个模块编写完毕,就可以被其他地方引用。
使用模块可以避免函数名和变量名冲突。
1.time和datetime模块
time模块
python中,通常由以下三种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移,运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String):如‘2018-4-24'
- 结构化的时间(struct_time):元祖形式。struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time # 时间戳: print(time.time()) # 1520503969.847386 # 字符串格式化时间(两种结果一样): print(time.strftime('%x,%X')) # 04/24/18,16:09:53 print(time.strftime('%c')) # Tue Apr 24 16:11:12 2018 print(time.strftime('%Y-%M-%d,%H:%M:%S')) # 2018-14-24,16:14:08 print(time.strftime('%Y-%m-%d %X')) # 2018-03-08 18:12:49 print(time.strftime('%Y-%m-%d %H:%M:%S')) # 结构化时间: print(time.localtime()) # 本地时区的struct_time print(time.gmtime()) # UTC时区的struct_time
其中计算机认识的时间只能是'时间戳'格式,而程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间'
几种时间格式之间的转换:
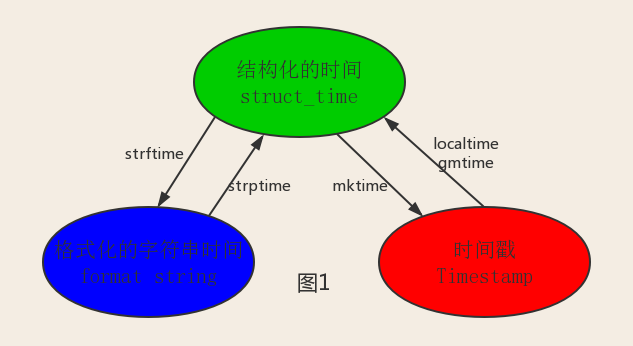
具体用法:
import time # 时间戳转化为结构化时间 # time.gmtime(时间戳) # UTC时间 # time.localtime(时间戳) # 当地时间 ret = time.localtime(2000000000) print(ret) # time.struct_time(tm_year=2033, tm_mon=5, tm_mday=18, tm_hour=11, tm_min=33, tm_sec=20, tm_wday=2, tm_yday=138, tm_isdst=0) # 结构化时间转化为格式化时间 print(time.strftime('%Y-%m-%d %H:%M:%S', ret)) # 2033-05-18 11:33:20 # 把一个结构化时间转化为格式化时间 print(time.strftime("%Y-%m-%d %X", time.localtime())) # 把一个格式化时间字符串转化为struct_time print(time.strptime('2018-04-24 17:37:06', '%Y-%m-%d %X'))
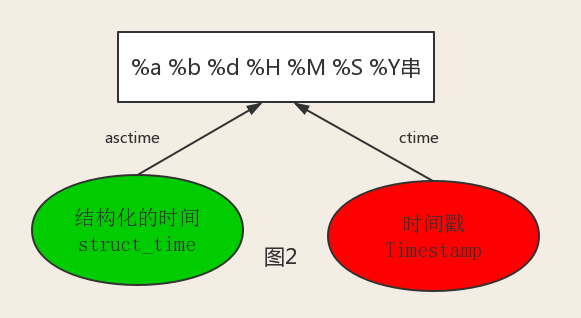
# 结构化时间 --> %a %b %d %H:%M:%S %Y串
# ctime,把一个时间戳转化为time.asctime()的形式 # 如果参数未给或者为None的时候,将会默认time.time()为参数 a = time.ctime(2000000000) print(a) # Wed May 18 11:33:20 2033 print(time.ctime(time.time())) # Tue Apr 24 17:41:56 2018 # asctime,把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。 # 如果没有参数,则默认将time.localtime()作为参数传入。 print(time.asctime()) # Tue Apr 24 17:41:56 2018
python中时间日期格式化符号:
1 %y 两位数的年份表示(00-99)
2 %Y 四位数的年份表示(000-9999)
3 %m 月份(01-12)
4 %d 月内中的一天(0-31)
5 %H 24小时制小时数(0-23)
6 %I 12小时制小时数(01-12)
7 %M 分钟数(00=59)
8 %S 秒(00-59)
9 %a 本地简化星期名称
10 %A 本地完整星期名称
11 %b 本地简化的月份名称
12 %B 本地完整的月份名称
13 %c 本地相应的日期表示和时间表示
14 %j 年内的一天(001-366)
15 %p 本地A.M.或P.M.的等价符
16 %U 一年中的星期数(00-53)星期天为星期的开始
17 %w 星期(0-6),星期天为星期的开始
18 %W 一年中的星期数(00-53)星期一为星期的开始
19 %x 本地相应的日期表示
20 %X 本地相应的时间表示
21 %Z 当前时区的名称
datetime模块:
import datetime print(datetime.datetime.now()) # 2018-03-08 21:04:15.544213
# y-m-d h:M:S 2018-04-24 17:00:00
# 计算从当前时间开始 比起y-m-d h:M:S过去了多少年 多少月 多少天 多少h,多少m,多少s


import time def pass_time(times): pass_time = time.strptime(times, '%Y-%m-%d %X') # 结构化时间 pass_time_stamp = time.mktime(pass_time) # 时间戳 time_stamp = time.time()-pass_time_stamp # 已经过去的时间戳 pass_times = time.localtime(time_stamp) # 结构化时间 now = zip(tuple(pass_times),tuple(time.localtime(0))) now1 = [(i[0]-i[1]) for i in now] # 数字型列表,对应年,月--- return '从当前时间开始,距离%s过去了%s年%s月%s日%s时%s分%s秒' %(times,now1[0],now1[1],now1[2],now1[3],now1[4],now1[5]) print(pass_time('2018-04-24 17:00:00'))
2. random模块
1 import random 2 # ---------------------------- 3 # 1.随机小数,发红包可用 4 print(random.random()) #0到1之间的随机小数 5 print(random.uniform(1,3)) #大于1且小于3的随机小数 6 7 # ---------------------------- 8 # 2.随机整数,验证码可用 9 print(random.randint(1,5)) #大于1且小于等于5之间的整数 10 print(random.randrange(1,10,2)) #大于等于1且小于3之间的整数(且是所有的奇数) 11 12 # ---------------------------- 13 # 3.随机选择一个返回,抽奖 14 print(random.choice([1,'23',[4,5]])) 15 # ---------------------------- 16 # 4.随机选择返回多个,一次抽取多个 17 print(random.sample([1,'23',[4,5]],2)) #列表元素任意两个组合输出,后缀为输出个数 18 # ---------------------------- 19 20 21 # ---------------------------- 22 # 5.打乱列表顺序,洗牌 23 item=[1,5,2,3,4] 24 random.shuffle(item) #打乱次序 25 print(item)
利用随机数随机生成6位验证码:
import random def ver_code(num): strs = '' lis1 = [chr(i) for i in range(65, 91)] lis2 = [str(i) for i in range(10)] ver1 = random.sample(lis1+lis2,num) for i in ver1: strs += i return strs print(ver_code(6))
def id_code(num): # num 字母在每一位被取到的概率相同 ret = '' for i in range(num): number = str(random.randint(0,9)) alph_num = random.randint(97,122) # A65 a97 +25 alph_num2 = random.randint(65,90) # A65 a97 +25 alph = chr(alph_num) alph2 = chr(alph_num2) choice = random.choice([alph,alph2]) choice = random.choice([number,choice]) ret += choice return ret print(id_code(6))
利用随机数实现一个发红包的编程
import random inp_money = float(input('红包金额:')) inp_count = int(input('红包个数:')) def red_packet(money, count): li = [] money = int(money*100) money_site = random.sample(range(1, money), count-1) money_site.extend([0, money]) money_site = sorted(money_site) for i in range(count): li.append(round((money_site[i+1]-money_site[i])*0.01, 2)) return li # 上面的定义li列表、for循环以及return 可以简写成下面一行。 # return [round((sorted(money_site)[i + 1] - sorted(money_site)[i]) * 0.01, 2) for i in range(count)] ret = red_packet(inp_money, inp_count) print(ret)
利用随机数随机生成4位验证码,并带模糊效果
from PIL import Image, ImageDraw, ImageFont, ImageFilter
import random
# 随机字母:
def rndChar():
return chr(random.randint(48, 57))
# 随机颜色1:
def rndColor():
return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))
# 随机颜色2:
def rndColor2():
return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))
# 240 x 60:
width = 60 * 4
height = 60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象:
font = ImageFont.truetype('ariblk.ttf', 40)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):
for y in range(height):
draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):
draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save('code.jpg', 'jpeg')
3. OS模块(是与操作系统交互的一个接口)
# 有的文件可能转义可能会出现问题,一般要在双引号前加r,取消转义,或者用双斜杠表示
# 和当前执行的python文件工作目录相关的工作路径
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
# 和文件夹相关
os.makedirs('dirname1/dirname2') 可生成多层递归目录,即文件夹下创建子文件夹,不会覆盖原文件夹
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录,即文件夹;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和文件夹,包括隐藏文件,并以列表方式打印
# 和文件相关
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
# 和操作系统差异相关
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
# 和执行系统命令相关
os.system("bash command") 运行shell命令,直接显示,但是显示的看不懂
os.popen("bash command).read() 运行shell命令,获取执行结果,可看懂,如os.popen('dir').read()
os.environ 获取系统环境变量
# 路径相关系列
os.path.abspath(path) 返回path规范化的绝对路径,即从哪个盘开始全部显示出来
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小,文件夹的大小不准确,只显示最大值4096字节,文件准确
ret = os.path.join('F:每天视频以及笔记','day5视频') print(ret) ---F:每天视频以及笔记day5视频 # 组合成一个完整路径
考虑如何计算文件夹中所有文件大小?示例路径:F:每天视频以及笔记python11期day01
import os def ram(file_name): sum = 0 for file in os.listdir(file_name): path = os.path.join(file_name, file) # 组合成一个完整路径 if os.path.isfile(path): # 路径下是文件 sum += os.path.getsize(path) else: sum += ram(path) return sum print(ram('F:每天视频以及笔记python11期day01'))
import os def get_size(path): l = [path] sum_size = 0 while l: path = l.pop() # l = ['D:python11day2','D:python11day3'...] for item in os.listdir(path): #path = 'D:python11' path2 = os.path.join(path, item) # path2 = 'D:python11day2' if os.path.isfile(path2): sum_size += os.path.getsize(path2) # sum = 文件的大小 + 0 else: l.append(path2) return sum_size print(get_size('D:python11'))
# 复制文件的函数在os模块中并不存在,因为复制文件并非由操作系统提供的系统调用。但是我们可以调用shuti模块中的copyfile()实现,该模块相当于os模块的一个补充。
# 说明,第一种方式采用了递归,虽然结果上也实现了,但是它相对来说比较耗内存。而第二种方式利用堆和栈的方式来说更加的友好
4. sys模块(sys模块是与python解释器交互的一个接口)
1 sys.argv 命令行参数是一个List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称
5.序列化模块
序列化:
把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化目的
- 持续化某种状态。在断电或者关机之前可以将当前内存中所有的数据保存下来,下次程序运行时可以从当前保存的文件内容继续执行。
- 跨平台数据交互。
序列化有三个模块json和pickle,shelve
json 所有编程语言都通用的序列化格式,但是它支持的数据类型非常有限(只支持数字,字符串,序列,字典等,不支持元祖)
pickle 只能在python语言的程序之间传递数据使用,它支持python中所有数据类型
shelve 在py3之后才有,python专有的序列化模块,只针对文件。它只提供一个open方法,并且只能用字典形式访问内容
json
Json模块提供了四个功能:dumps、loads,这两个只在内存中操作数据,主要在网络传输中使用,和多个数据类型与文件打交道
dump、load ,这两个是直接将对象序列化之后写入文件,它依赖于一个文件句柄
import json dic={'k1':'v1','k2':'v2','k3':'v3'} str_dic = json.dumps(dic) #将字典转换成字符串,转换后的字典中的元素是由双引号表示的 print(str_dic,type(str_dic))#{"k1": "v1", "k2": "v2", "k3": "v3"} <class 'str'> dic2 = json.loads(str_dic)#将一个字符串转换成字典类型 print(dic2,type(dic2))#{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'>
import json dic={'k1':'v1','k2':'v2','k3':'v3'} f = open('a.txt','w',encoding='utf-8') json.dump(dic,f,ensure_ascii=False) # 先接收要序列化的对象 再接受文件句柄 f.close() f = open('a.txt','r',encoding='utf-8') ret = json.load(f) print(type(ret),ret)
# json在写入多次dump的时候,不能对应执行多次load来去除数据,pickle可以
# json如果要写入多个元素,应先将元素dumps序列化,再f.write(序列化+‘ ’)写入文件。读的时候先按行读取,再使用loads将读出来的字符串转换成相应数据类型。
pickle(可以把python中的任意数据类型序列化)
在硬盘上存储文件有很多种方法,文本文件只是其中一种,如果想存储列表或者对象之类的内容,可以把对象转换成字符串的形式写入文本文件,但是如果要从文件中回复对象,则这个就复杂化了。而python提供的pickle恰好能做到这一点:
# 通过pickle存储python原生对象:
import pickle
D = {'a': 1, 'b': 2}
F = open('datafile.pkl', 'wb')
pickle.dump(D, F) # pickle.dump()可以把任意对象序列化成一个bytes,然后就可以把bytes写入文件
F.close()
# 取回字典,再用pickle模块中load函数进行一次重建
F = open('datafile.pkl', 'rb')
E = pickle.load(F)
F.close()
import pickle
file = 'wish.data'
lis = ['apple', 'banban']
f = open(file, 'wb')
pickle.dump(lis, f)
f.close()
del lis
f = open(file, 'rb')
storedlis = pickle.load(f)
print(storedlis) # 又得到了列表
关于序列化自定义类的对象:
class A:
def __init__(self,name,age):
self.name=name
self.age=age
a = A('luffy',18)
# import json
# json.dumps(a) # 报错,说明json无法存储实例化对象
import pickle
ret = pickle.dumps(a)
print(ret) # 打印出来的是一串字节
obj = pickle.loads(ret)
print(obj) # 打印出对象地址
print(obj.__dict__) # {'name': 'luffy', 'age': 18}
在load的时候,必须拥有被load数据类型对应的类在内存里面
shelve(用法专讲链接https://www.tielemao.com/764.html)
python专有的序列化模块,只针对文件,只提供了一个open方法,且是用key来访问的,使用起来和字典类似。
import shelve
f = shelve.open('a.txt')
f['key'] = {'int': 10, 'float': 9.5, 'string': 'Sample data'}
f['ds'] = '范围分为we分我发'
f.close()
# 直接对文件句柄进行操作,就可以存储文件,而且程序会给我们自动创建三个后缀为dir,bak,dat的文件,其中以bat结尾的文件存储的就是b字节数据类型的数据
f1 = shelve.open('a.txt')
a = f1['ds'] # 用key直接取出存储的内容,如果key不存在则会报错
f1.close()
print(a)
# 设置只读模式
f2 = shelve.open('a.txt', flag='r')
f2['key']['float'] = 3.14 # 修改结构中得值,不可以
f2['space'] = 'dwd' # 覆盖原来的结构,可以
f1.close()
f3 = shelve.open('a.txt')
b = f3['key']['float'] # 对结构的值作修改,但是失败了
f3.close()
print(b) # 9.5
6.hashlib模块
摘要算法,也称哈希算法,它能将字符串转成数字,不同的字符串转成的数字一定不同,通常用16进制表示。无论在哪台机器上,在什么时候计算,对相同的字符串结果总是一样的
任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。因此两个不同的数据通过某个摘要算法也可能得到相同的摘要,这种情况被称为碰撞
用处:
密文验证的时候加密
文件的一致性校验
# md5算法:业界通用算法
# sha算法:安全系数更高,它有很多种(sha1,sha2,sha3等),后面数字越大,安全系数越高,且得到的数字结果越长,计算时间越长。它的用法和md5相同,只需把md5换成sha1即可。
密文验证的时候加密:
# hashhlib基本用法
import hashlib
m = hashlib.md5() # 创建了一个md5算法对象
m.update('aptx4869'.encode('utf-8')) # 必须将字符串转换成utf-8格式
print(m.hexdigest()) # 固定格式
# 6d1ce7aa0a1d988dc96a2abcd187b45a
import hashlib
m = hashlib.md5()
m.update('apt'.encode('utf-8')) # 对源码进行拆分加密,得到的结果与整体加密一致
m.update('x4869'.encode('utf-8'))
print(m.hexdigest())
# 6d1ce7aa0a1d988dc96a2abcd187b45a
# 一段字符串直接进行摘要和分成几段摘要的结果是相同的
# 如果数字过于简单,就可以根据密文进行暴力破解获得源码,安全性不是太好,因此可以采用加盐的方式加密
# 加盐:在源码的基础上提前加一层静态码‘aptx4869’进行二次加密
m3 = hashlib.md5('aptx4869'.encode('utf-8'))
m3.update('123456'.encode('utf-8'))
print(m3.hexdigest())
# 21a36cc3275d352d92ee741b5425c330
# 这种方式较第一种比较安全性有所提高
# 动态加盐: 对于用户登录,可以通过相应的用户登录名进行一次加密,用密码二次加密,密码随着用户账户的变化而变化
username = 'Learning'
password = 'aptx4869'
m4 = hashlib.md5(username.encode('utf-8'))
m4.update(password .encode('utf-8'))
print(m4.hexdigest())
# b9112f155c08b48bba0e595236facc40
# 这种方式安全性大大的有所提高,登陆过程建议使用
文件的一致性校验:(用来验证文件内容是否被篡改)
# 该函数一次性全部交验,如果文件较大,则耗时较大
import hashlib
def check(filename):
md5obj = hashlib.md5()
with open(filename,'rb') as f:
content = f.read()
md5obj.update(content)
return md5obj.hexdigest()
# 该函数对于较大的文件,一次性以一定的字节数读取验证来验证一致性
def check(filename):
md5obj = hashlib.md5()
with open(filename,'rb') as f:
while True:
content = f.read(1024)
if content:
md5obj.update(content)
else: # 如果文件为空
break
return md5obj.hexdigest()
ret1 = check('file1.txt')
ret2 = check('file2.txt')
print(ret1)
print(ret2)
那么问题来了,如何验证两个文件的一致性呢?
import hashlib def compare(filename1,filename2): md5sum = [] for file in [filename1,filename2]: md5 = hashlib.md5() with open(file,'rb') as f: while True: content = f.read(1024) if content: md5.update(content) else:break md5sum.append(md5.hexdigest()) if md5sum[0] == md5sum[1]:return True else :return False print(compare('f1','f2'))
import hashlib def loc(filname1, filname2): def check(filename): md5obj = hashlib.md5() with open(filename,'rb') as f: while True: content = f.read(5) if content: md5obj.update(content) else: # 非空 break return md5obj.hexdigest() if check(filname1) == check(filname2): return True else: return False print(loc('a.txt', 'a1.txt'))
7.configparser
在配置文件里必须有分组(节),分组的组名可以随便起 ,可以包含一个或多个组,可以叫DEFAULT,它都具有特殊的意义(默认的是全局变量)
# 创建ini文件
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'luffy':'香蕉人',
'zero':'三把刀',
'sanzhi':'秋刀鱼'}
config['name'] = {'rojie':'onepiece',
'BB':'c',
'dd':'N'}
# config['www.onepiece.online'] = {'我就试试集合行不行'} # 报错,只能是字典形式
config['www.onepiece.online'] = {'我就试试集合行不行':'不行啊'}
with open('one.ini', 'w') as f:
config.write(f)
写入后内容形式(这里我是直接用电脑自带的文本阅读器打开的,默认是gbk格式,用其他阅读器非gbk会产生乱码):
[DEFAULT]
zero = 三把刀
sanzhi = 秋刀鱼
luffy = 香蕉人
[name]
dd = N
bb = c
rojie = onepiece
[www.onepiece.online]
我就试试集合行不行 = 不行啊
增删改操作
# 增删改操作
import configparser
config=configparser.ConfigParser()
config.read('one.ini')
# 删除节'name'
config.remove_section('name')
# 删除节下的某个value值
config.remove_option('www.onepiece.online','我就试试集合行不行')
# 判断是否存在某个标题
print(config.has_section('name'))
# 判断标题section1下是否有user
print(config.has_option('www.onepiece.online','我就试试集合行不行'))
# 添加一个标题
config.add_section('EGG')
#在标题EGG下添加name=egon,age=18的配置
config.set('EGG','name','egon')
config.set('EGG','age','18')
总结:
# section 可以直接操作他的对象来获取所有的节信息
# option 可以通过找到的节来查看所有的项
8.logging (记录日志的模块)
不会帮你自动添加日志的内容,只能根据程序员写的代码完成功能
可以通过一个参数去控制全局的日志输出情况
可以帮助开发者同时向文件和屏幕输出内容
logging模块提供5中日志级别,从低到高一次:debug info warning error critical
默认是从warning模式开始显示
日志级别 CRITICAL = 50 #FATAL = CRITICAL ERROR = 40 WARNING = 30 #WARN = WARNING INFO = 20 DEBUG = 10
默认级别为warning,它会默认打印在终端上
简单用法:basicconfig
# 默认情况下 只显示警告(warning)及警告级别以上信息 import logging logging.basicConfig(level=logging.DEBUG,format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',datefmt='%a, %d %b %y %H:%M:%S',filename = 'userinfo.log') logging.debug('debug message') # debug 调试模式 级别最低 logging.info('info message') # info 显示正常信息 logging.warning('warning message') # warning 显示警告信息 logging.error('error message') # error 显示错误信息 logging.critical('critical message') # critical 显示严重错误信息 ---WARNING:root:warning message ---ERROR:root:error message ---CRITICAL:root:critical message ---WARNING:root:warning message
logging.basicconfig()函数可配参数:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。 filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。 format:指定handler使用的日志显示格式。 datefmt:指定日期时间格式。 level:设置rootlogger(后边会讲解具体概念)的日志级别 stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 #格式 %(name)s:Logger的名字,并非用户名,详细查看 %(levelno)s:数字形式的日志级别 %(levelname)s:文本形式的日志级别 %(pathname)s:调用日志输出函数的模块的完整路径名,可能没有 %(filename)s:调用日志输出函数的模块的文件名 %(module)s:调用日志输出函数的模块名 %(funcName)s:调用日志输出函数的函数名 %(lineno)d:调用日志输出函数的语句所在的代码行 %(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示 %(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数 %(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 %(thread)d:线程ID。可能没有 %(threadName)s:线程名。可能没有 %(process)d:进程ID。可能没有 %(message)s:用户输出的消息
logging模块组件:
# Logger 产生日志对象
# Handler 接收日志然后控制打印到不同地方:
# FileHandler用来打印到文件中,
# StreamHandler用来打印到终端
# Filter 过滤日志对象
# Formatter 指定日志显示格式
logger对象配置:
import logging logger = logging.getLogger() # Logger用于产生日志,实例化一个logger对象 # Handler对象:接收logger传来的日志,并控制输出 fh = logging.FileHandler('test.log',encoding='utf-8') # 实例化一个文件句柄,并打印到文件 ch = logging.StreamHandler() # 打印到终端,没有这步则只在文件中打印,在终端不显示,终端就是电脑输出界面 fmt = logging.Formatter('%(asctime)s-%(name)s-%(levelname)s-%(message)s') # 定制化显示格式 fh.setFormatter(fmt) ch.setFormatter(fmt) # 为Handler对象绑定格式 logger.addHandler(fh) logger.addHandler(ch) # 和logger关联的只有文件句柄 logger.setLevel(logging.WARNING) # 对象警告级别,从该级别以上开始警报 # 这里我是直接给对象设置的该级别,意味着文件和终端都是同一级别,这里可以 # 对文件和终端分别设置不同的级别 logger.debug('debug message') # debug 调试模式 级别最低 logger.info('info message') # info 显示正常信息 logger.warning('warning message') # warning 显示警告信息 logger.error('error message') # error 显示错误信息 logger.critical('critical message')
9.collections模块
内置数据类型基础上,collections模块还提供了几个额外数据类型:
counter:计数器
deque:双端排列,可以快速从另外一侧追加对象
namedtuple:生成可以使用名字来访问元素内容的tuple
orderdict:有序字典
defaultdict:带有默认值的字典
namedtuple:
from collections import namedtuple point = namedtuple('point', ['x','y','z']) p = point(1,4,9) print(p.x) # 1 print(p.z) # 9 # 用来计算长方体体积 square = namedtuple('length',('x','y','z')) v = square(5,2,8) volume = v.x *v.y * v.z print(volume) # 80
deque:
它是为了实现插入和删除操作的双向列表,适用于队列和栈
from collections import deque lis = deque(['a','c','b']) lis.append(3) lis.appendleft(5) print(lis) # deque([5, 'a', 'c', 'b', 3]) # 这里直接用list()可以转换成列表形式
Counter:
它的作用是用来跟踪值出现的次数,属于一个无序的容器类型,以字典的键值对形式存储
基本用法:
from collections import Counter c = Counter('abcdeabcdabcaba') print(dict(c)) # {'e': 1, 'b': 4, 'd': 2, 'a': 5, 'c': 3} print(c['a']) # 5 print(c['b']) #4
计数器的更新,包含增加(update)和减少(subtract)两种
from collections import Counter # update c = Counter('smile') c.update('lie') print(c['e']) # 2 d = Counter('beautiful') f = Counter('bee') d.update(f) print(d['e']) # 3 # subtract c = Counter('smile') c.subtract('lie') print(c['e']) # 0 d = Counter('beautiful') f = Counter('bee') d.subtract(f) print(d['e']) # -1
键的修改和删除(del)
from collections import Counter c = Counter("abcdcba") c['a'] = 0 print(dict(c)) # {'d': 1, 'a': 0, 'c': 2, 'b': 2} del c['b'] print(dict(c)) # {'a': 0, 'c': 2, 'd': 1}
算数和集合操作
+、-、&、|操作也可以用于Counter。其中&和|操作分别返回两个Counter对象各元素的最小值和最大值。需要注意的是,得到的Counter对象将删除小于1的元素。
c = Counter(a=8, b=1) d = Counter(a=5, b=2) print(dict(c+d)) # {'a': 13, 'b': 3} print(dict(c-d)) # {'a': 3} 注意,它只保留正数计数的元素 print(dict(c&d)) # {'a': 5, 'b': 1} 求交集,min(c[x], d[x]) print(dict(c|d)) # {'b': 2, 'a': 8} 求并集,max(c[x], d[x])
Counter类常用操作
sum(c.values()) # 所有计数的总数 c.clear() # 重置Counter对象,注意不是删除,最终返回None list(c) # 将c中的键转为列表 set(c) # 将c中的键转为set dict(c) # 将c中的键值对转为字典 c.items() # 转为(elem, cnt)格式的列表 Counter(dict(list_of_pairs)) # 从(elem, cnt)格式的列表转换为Counter类对象 c.most_common()[:-n:-1] # 取出计数最少的n个元素 c += Counter() # 移除0和负值
# 统计一篇英文文章内每个单词出现频率,并返回出现频率最高的前10个单词及其出现次数
# 对['a','2',2,4,5,'2','b',4,7,'a',5,'d','a','z']该列表的数据进行计数统计
# 方法链接:http://www.cnblogs.com/LearningOnline/articles/8975806.html
Orderedict
保持key的顺序
from collections import OrderedDict d = dict([('a', 3), ('b', 5), ('c', 3)]) print(d) # {'b': 5, 'c': 3, 'a': 3} d = OrderedDict([('a', 3), ('b', 5), ('c', 3)]) print(d) # OrderedDict([('a', 3), ('b', 5), ('c', 3)]) # 给这个样子感觉作用不大啊,用dict转型过来顺序又变了
对一个字典进行有序排序:
from collections import OrderedDict ordered_dict = OrderedDict() dic = { 4:'xxx', 1:'xxx', 2:'xxx', } for key in sorted(dic): ordered_dict[key] = dic[key] print(ordered_dict)
defaultdict(默认字典,是给字典中的value值设置默认值)
它最大的好处在于永远不会在你使用key获取值的时候报错
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
from collections import defaultdict values = [11, 22, 33,44,55,66,77,88,99,90] my_dict = defaultdict(list) for value in values: if value>66: my_dict['k1'].append(value) else: my_dict['k2'].append(value) print(dict(my_dict))