Kafka是一个分布式流处理平台。
流处理平台的三大特性:
1、可以发布和订阅流式的记录。
2、可以存储流记录,有较好的容错性。
3、可以在流式记录产生时就进行处理。
Kafka适合的应用场景:
1、构建实时数据管道,可以在系统和应用程序之间可靠的获取数据。
2、构建实时流式应用程序,对这些流数据进行转换或者影响。
Kafka 的概念:
1、Kafka作为一个集群,运行在一台或者多台服务器上。
2、Kafka通过topic对数据的流数据进行分类。
3、每条记录中包含一个key,一个value,一个时间戳。
Kafka的四大核心API
1、The Producer API 允许一个应用程序发布一串流式的数据到一个或者多个Kafka topic
2、The Consumer API 允许应用程序订阅一个或多个topic ,并且对发布给它们的流式数据进行处理。
3、The Streames API 允许一个应用程序作为一个流处理器,消费一个或者多个topic产生的输入流,然后生产一个输出流到一个或多个topic中去,在输入和输出流中有效的进行转换。
4、The Connector API 允许构建并运行可重用的生产者或者消费者,将Kafka topic 连接到已存在的应用程序或者数据库系统,比如,连接到一个关系型数据库,捕捉表的所有变更内容。
在kafka中,客户端和服务器使用一个简单、高性能、支持多语言的TCP协议,此协议版本化,并向下兼容老版本,
Topics 和 日志
Kafka的核心概念:提供一串流式的记录-topic
topic 就是数据主题,是数据记录发布的地方,可以用来区分业务系统,Kafka中的Topics总是多订阅模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
对于每一个topic,kafka集群都会维持一个分区日志,如下所示:
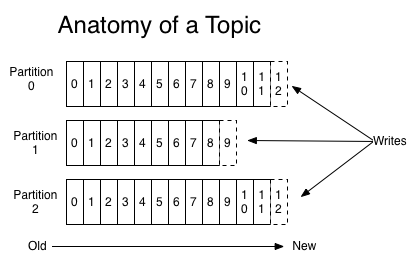
每个分区都是有序且顺序不可变的记录集,并且不断追加到结构化的commit log 文件,分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset ,offset 用来唯一的标识分区中的每一条记录。
kafka 集群保留所有发布的记录-无论它们是否已被消费--并通过一个可配置参数--保留期限来控制,举个粟子,如果保留策略为两天,一个记录发布后两天内可以随时消费,两天过后这条记录会被抛弃,并释放磁盘空间。kafka的性能和数据大小无关。
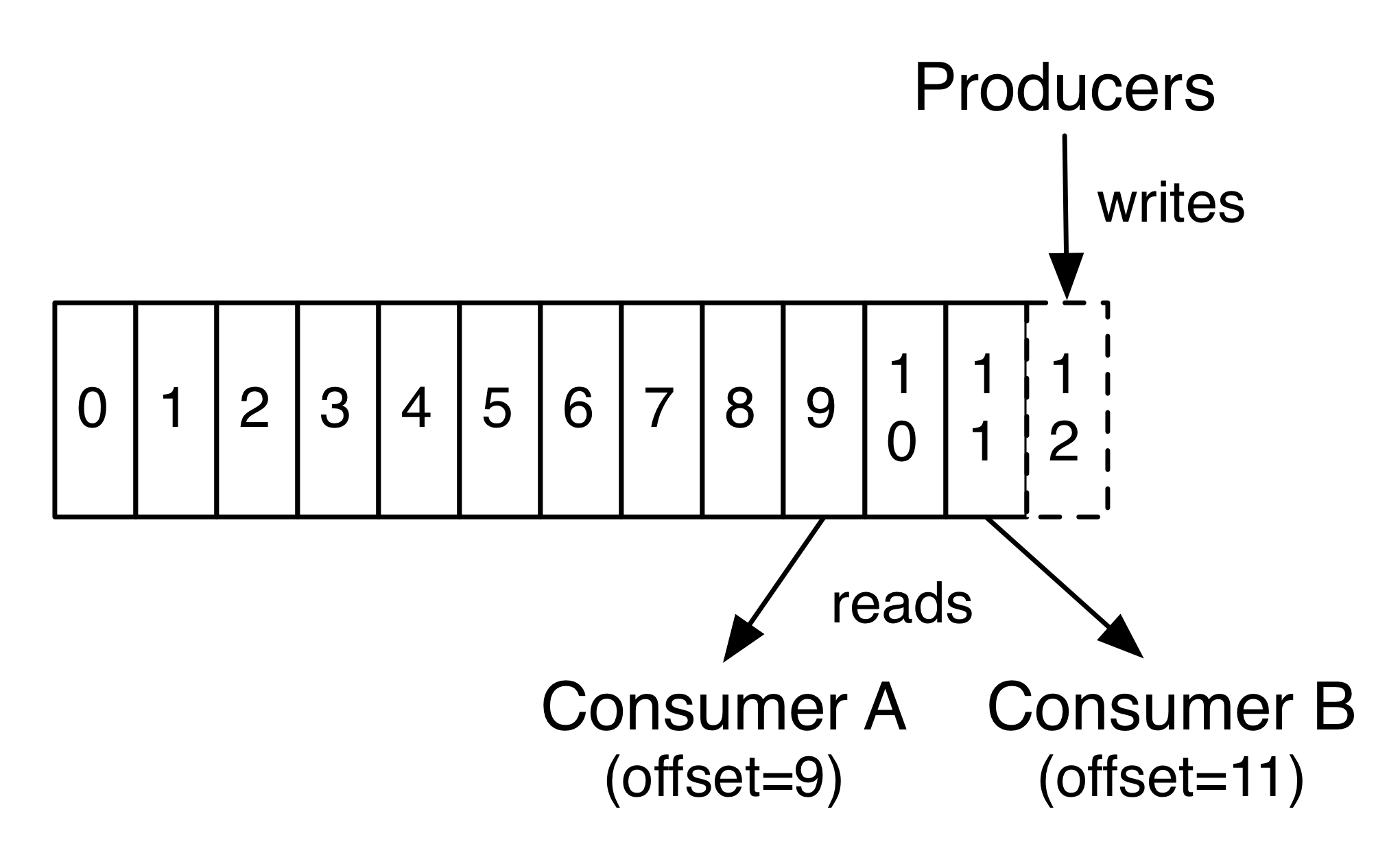
偏移量 :offset
每一个消费者中唯一保存的元数据是offset(偏移量),偏移量由消费者所控制:
通常在读取记录后,消费者会以线性的方式增加偏移量, 实际上,由于这个位置由消费者控制,所以消费者可以采用任何顺序来消费记录。
例如,一个消费者可以重置到一个旧的偏移量,从而重新处理过去的数据;也可以跳过最近的记录,从"现在"开始消费。
细节说明Kafka 消费者是非常廉价的—消费者的增加和减少,对集群或者其他消费者没有多大的影响。
你可以使用命令行工具,对一些topic内容执行 tail操作,并不会影响已存在的消费者消费数据。
日志中的分区: partition
用途:
1、当日志大小超过了单台服务器的限制,允许日志进行扩展,每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。
2、可以作为并行的单元集—关于这一点,更多细节如下
分布式
日志的分区partition (分布)在Kafka集群的服务器上。每个服务器在处理数据和请求时,共享这些分区。每一个分区都会在已配置的服务器上进行备份,确保容错性。
每个分区都有一台 server 作为 “leader”,零台或者多台server作为 follwers 。leader server 处理一切对 partition (分区)的读写请求,而follwers只需被动的同步leader上的数据。当leader宕机了,followers 中的一台服务器会自动成为新的 leader。每台 server 都会成为某些分区的 leader 和某些分区的 follower,因此集群的负载是平衡的。
生产者
生产者可以将数据发布到所选择的topic(主题)中。生产者负责将记录分配到topic的哪一个 partition(分区)中。可以使用循环的方式来简单地实现负载均衡,也可以根据某些语义分区函数(例如:记录中的key)来完成。下面会介绍更多关于分区的使用。
消费者
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
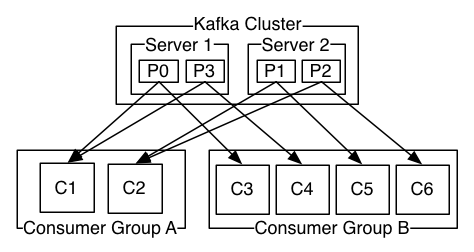
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个"逻辑订阅者"。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。