1.提升方法AdaBoost算法
AdaBoost是一种迭代算法,核心思想是针对同一个训练数据集训练不同的分类器(若分类器),然后把这些弱分类器集合起来,构成一个更强的分类器(强分类器)
Adaboost是英文"Adaptive Boosting"(自适应增强)的缩写,它的自适应在于:前一个基本分类器被错误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数才确定最终的强分类器。
对于AdaBoost,我们要搞清楚两点:
1. 每一次迭代的弱学习h(x;am)有何不一样,如何学习?
AdaBoost改变了训练数据的权值,也就是样本的概率分布,其思想是将关注点放在被错误分类的样本上,减小上一轮被正确分类为的样本权值,提高那些被错误分类的样本权值。然后,再根据所采用的一些基本机器学习算法进行学习,比如逻辑回归。
2. 弱分类器权值βm如何确定?
AdaBoost采用加权多数表决的方法,加大分类误差率小的分类器的权重,减小分类误差率大的弱分类器的权重。(正确率高,分的好的弱分类器在强分类器中有较大的发言权)
对于提升方法,有两个问题需要回答:
- 每一轮如何改变训练数据的权值或概率分布?
- 如何将弱分类器组合成一个强分类器?
AdaBoost的做法:
- 提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。
- 加权多数表决的方法,加大分类误差率小的弱分类器的权值,使其在表决中起较大作用,减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用。
不改变所给的训练数据,而不断改变训练数据权值的分布,使得训练数据在基本分类器的学习中起不同的作用,这就是AdaBoost的一个特点。总的来说,AdaBoost算法的步骤为:更新训练数据权值->在此权值上训练弱分类器(策略为最小化分类误差率)->计算分类误差率(误分类样本的权值之和)->计算分类器系数(要用到上一步的分类误差率)->更新训练权值->构建基本分类器的线性组合,一直循环,直到基本分类器的线性组合没有误分类点。
算法流程:
1.先通过对N个训练样本的学习得到第一个弱分类器
2.将分错的样本和其他的新数据一起构成一个新的N个训练样本,通过对这个样本的学习得到第二个弱分类器
3.将1和2都分错的样本加上其他的新样本构成另一个新的N个训练样本,通过对这样本的学习得到第三个弱分类器
4.最终经过提升的强分类器。即某个数据被分为哪一类要由各分类器权值决定
Adaboost 步骤概览
① 初始化训练样本的权值分布,每个训练样本的权值应该相等(如果一共有N个样本,则每个样本的权值为1/N)
② 依次构造训练集并训练弱分类器。如果一个样本被准确分类,那么它的权值在下一个训练集中就会降低;相反,如果它被分类错误,那么它在下个训练集中的权值就会提高。权值更新过后的训练集会用于训练下一个分类器。
③ 将训练好的弱分类器集成为一个强分类器,误差率小的弱分类器会在最终的强分类器里占据更大的权重,否则较小。

2.AdaBoost算法解释
Boosting算法要涉及到两个部分:加法模型和前向分布算法。加法模型就是说强分类器是由一系列弱分类器线性相加而成。一般组合形式如下:
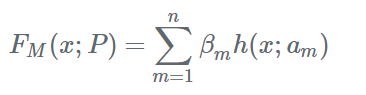
其中,h(x;am)就是一个个的弱分类器,am是弱分类器学习到的最优参数,βm就是弱学习在强分类器中所占比重,P是所有am和βm的组合。这些弱分类器线性相加组成强分类器。
前向分步就是说在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的。也就是可以写成这样的形式:
Fm(x)=Fm−1(x)+βmhm(x;am)
AdaBoost就是损失函数为指数损失的Boosting算法。
3.AdaBoost算法优点:
1.精度很高的分离器
2.提供的是框架,可以使用各种方法构建弱分类器
3.简单,不需要做特征筛选
4.不用担心过拟合
实际应用:
1.用于二分类或多分类
2.特征选择
3.分类人物的baseline
4.提升树
提升树是以决策树为基函数的提升方法。对分类问题决策树是二叉分类树,对回归问题决策树是二叉回归树
Adaboost人脸检测技术
Haar特征
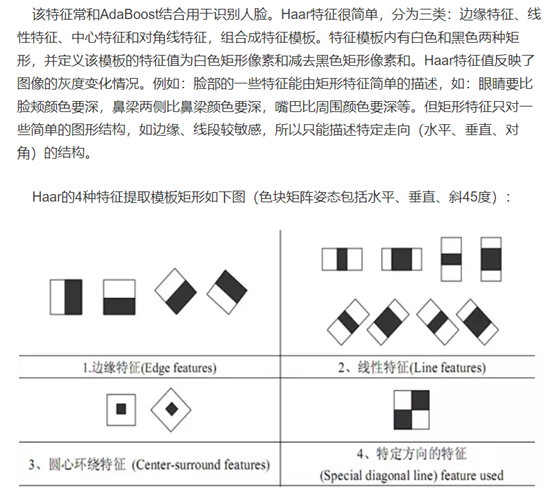
对于一个给定的24X24的窗口,根据不同的位置,以及不同的缩放,可以产生超过160,000个特征。

选取弱分类器
一个弱分类器,实际上就是在这160,000+的特征中选取一个特征,用这个特征能够区分出人脸or非人脸,且错误率最低。
现在有人脸样本2000张,非人脸样本4000张,这些样本都经过了归一化,大小都是24X24的图像。那么,对于160,000+中的任一特征fi,我们计算该特征在这2000人脸样本、4000非人脸样本上的值,这样就得到6000个特征值。将这些特征值排序,然后选取一个最佳的特征值,在该特征值下,对于特征fi来说,样本的加权错误率最低。选择160,000+个特征中,错误率最低的特征,用来判断人脸,这就是一个弱分类器,同时用此分类器对样本进行分类,并更新样本的权重。
haar小波矩阵类似于卷积
遍历一张人脸图像,得到一个特征图,一个feature map 对应于一个弱分类器
对每一个特征f,训练一个弱分类器
在检测窗口遍历完一次图像后,处理重叠的检测到的人脸区域,进行合并等操作。
一个haar特征对应一个弱分类器,弱特征组合成强特征,弱分类器组合成强分类器。


