非线性方程
我们为什么要使用激励函数? 用简单的语句来概括. 就是因为, 现实并没有我们想象的那么美好, 它是残酷多变的.
开个玩笑, 不过激励函数也就是为了解决我们日常生活中 不能用线性方程所概括的问题. 好了,我知道你的问题来了.
什么是线性方程 (linear function)?
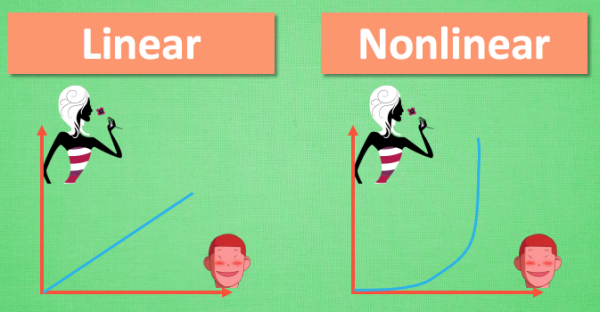
我们可以把整个网络简化成这样一个式子. Y = Wx, W 就是我们要求的参数, y 是预测值, x 是输入值.
用这个式子, 我们很容易就能描述刚刚的那个线性问题, 因为 W 求出来可以是一个固定的数. 不过这似乎
并不能让这条直线变得扭起来 , 激励函数见状, 拔刀相助, 站出来说道: “让我来掰弯它!”.
激励函数
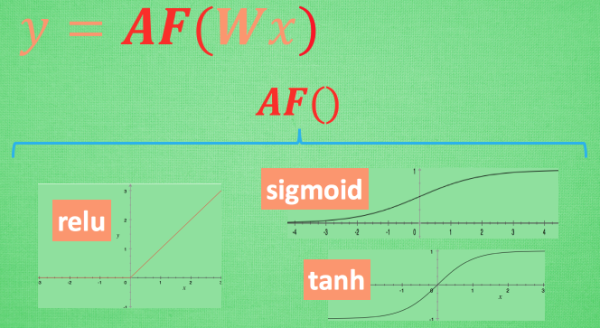
这里的 AF 就是指的激励函数. 激励函数拿出自己最擅长的”掰弯利器”, 套在了原函数上 用力一扭,
原来的 Wx 结果就被扭弯了.
其实这个 AF, 掰弯利器, 也不是什么触不可及的东西. 它其实就是另外一个非线性函数. 比如说relu,
sigmoid, tanh. 将这些掰弯利器嵌套在原有的结果之上, 强行把原有的线性结果给扭曲了. 使得输出
结果 y 也有了非线性的特征. 举个例子, 比如我使用了 relu 这个掰弯利器, 如果此时 Wx 的结果是1,
y 还将是1, 不过 Wx 为-1的时候, y 不再是-1, 而会是0.
你甚至可以创造自己的激励函数来处理自己的问题, 不过要确保的是这些激励函数必须是可以微分的,
因为在 backpropagation 误差反向传递的时候, 只有这些可微分的激励函数才能把误差传递回去.
常用选择
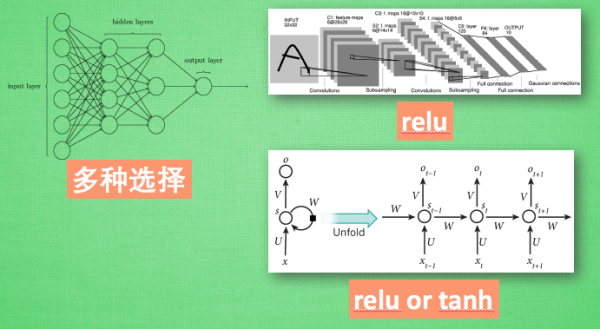
想要恰当使用这些激励函数, 还是有窍门的. 比如当你的神经网络层只有两三层, 不是很多的时候, 对于
隐藏层, 使用任意的激励函数, 随便掰弯是可以的, 不会有特别大的影响. 不过, 当你使用特别多层的神经
网络, 在掰弯的时候, 玩玩不得随意选择利器. 因为这会涉及到梯度爆炸, 梯度消失的问题. 因为时间的关
系, 我们可能会在以后来具体谈谈这个问题.
最后我们说说, 在具体的例子中, 我们默认首选的激励函数是哪些. 在少量层结构中, 我们可以尝试很多
种不同的激励函数. 在卷积神经网络 Convolutional neural networks 的卷积层中, 推荐的激励函数是 relu.
在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu .