- 词频统计预处理
- 下载一首英文的歌词或文章
- 将所有,.?!’:等分隔符全部替换为空格
- 将所有大写转换为小写
- 生成单词列表
- 生成词频统计
- 排序
- 排除语法型词汇,代词、冠词、连词
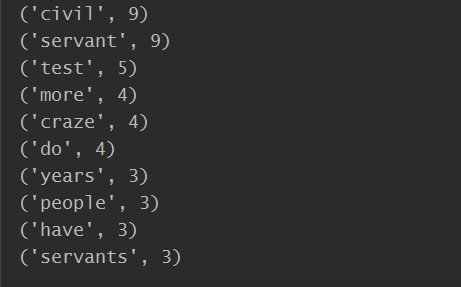
- 输出词频最大TOP10
# -*- coding : UTF-8 -*- # -*- author : Kamchuen -*- article = ''' In recent years, there are more and more people who have participated in the test for national civil servants. Millions of students choose civil servant as their most ideal occupation after graduation. And among them, the high-educated, like masters and doctors, take quite a large percentage. The craze in civil servant test has attracted widespread attention. The following reasons can account for this kind of craze. Above all, nowadays college students face great employment pressure. Civil servant, as one of the most stable professions in today’s China, becomes their preferable choice. Moreover, in recent years, the welfare and salary of civil servants have been improved greatly, which undoubtedly attracts many people. Besides, the high social position of civil servants is an important factor drawing many people to take part in the civil servant test. In my opinion, this craze in civil servant test will continue in the following years. However, from the long run, it doesn’t do good to the development of the nation. If most high quality talents gather in the government departments, it might lead to a waste of resources. Therefore, both the individuals and the government should have a more objective recognition of the civil servant test craze.''' symbol = [',','.','!','?','’',':','$','%'] words = ['a','in','of','the','to','at','it','on','and','so','his','that', 'not','was','my','were','we','he','an','as','is','for','mr','us'] new_art = article for i in range(len(symbol)): new_art = new_art.replace(symbol[i],'') #把文章的标点符号替换 new_art = new_art.lower() #改成小写 art_list = new_art.split() #以空格将字符串分成单词列表 dic = dict(zip()) for i in art_list: dic[i] = new_art.count(i) #用字典记录单词和其出现次数 for i in words: if(dic.get(i)!=None): #如果为冠词之类的无意义的词,将其舍弃 dic.pop(i) new_dic = sorted(dic.items(),key=lambda x:x[1],reverse = True) ''' dic.items()——将字典转为元组 key后面跟一个函数lambda,是一个匿名函数 lambda x:x[1]相当于 def f(x): return x[1] x[0]表示键key,x[1]表示值value 这里是使用值(单词出现次数)进行降序排序 reverse = True表示降序 ''' for i in range(10): print(new_dic[i]) #取出现频率最高的10个单词
效果截图: