20172328《程序设计与数据结构》实验二:树
- 课程:《软件结构与数据结构》
- 班级: 1723
- 姓名: 李馨雨
- 学号:20172328
- 实验教师:王志强老师
- 实验日期:2018年11月5日-2018年11月12日
- 必修选修: 必修
一、实验要求内容
- 实验1:实现二叉树
- 参考教材p212,完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
用JUnit或自己编写驱动类对自己实现的LinkedBinaryTree进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息 - 实验2:中序先序序列构造二叉树
- 基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如给出中序HDIBEMJNAFCKGL和后序ABDHIEJMNCFGKL,构造出附图中的树,用JUnit或自己编写驱动类对自己实现的功能进行测试,提交测试代码运行截图,要全屏,包含自己的学号信息
- 实验3:决策树
- 自己设计并实现一颗决策树,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
- 实验4:表达式树
- 输入中缀表达式,使用树将中缀表达式转换为后缀表达式,并输出后缀表达式和计算结果(如果没有用树,则为0分),提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
- 实验5:二叉查找树
- 完成PP11.3,提交测试代码运行截图,要全屏,包含自己的学号信息,课下把代码推送到代码托管平台
- 实验6 : 红黑树分析
- 参考本博客:点击进入对Java中的红黑树(TreeMap,HashMap)进行源码分析,并在实验报告中体现分析结果。
二、实验过程及结果
-
实验1:实现二叉树的解决过程及结果

-
实验2:中序先序序列构造二叉树的解决过程及结果

-
实验3:决策树的解决过程及结果
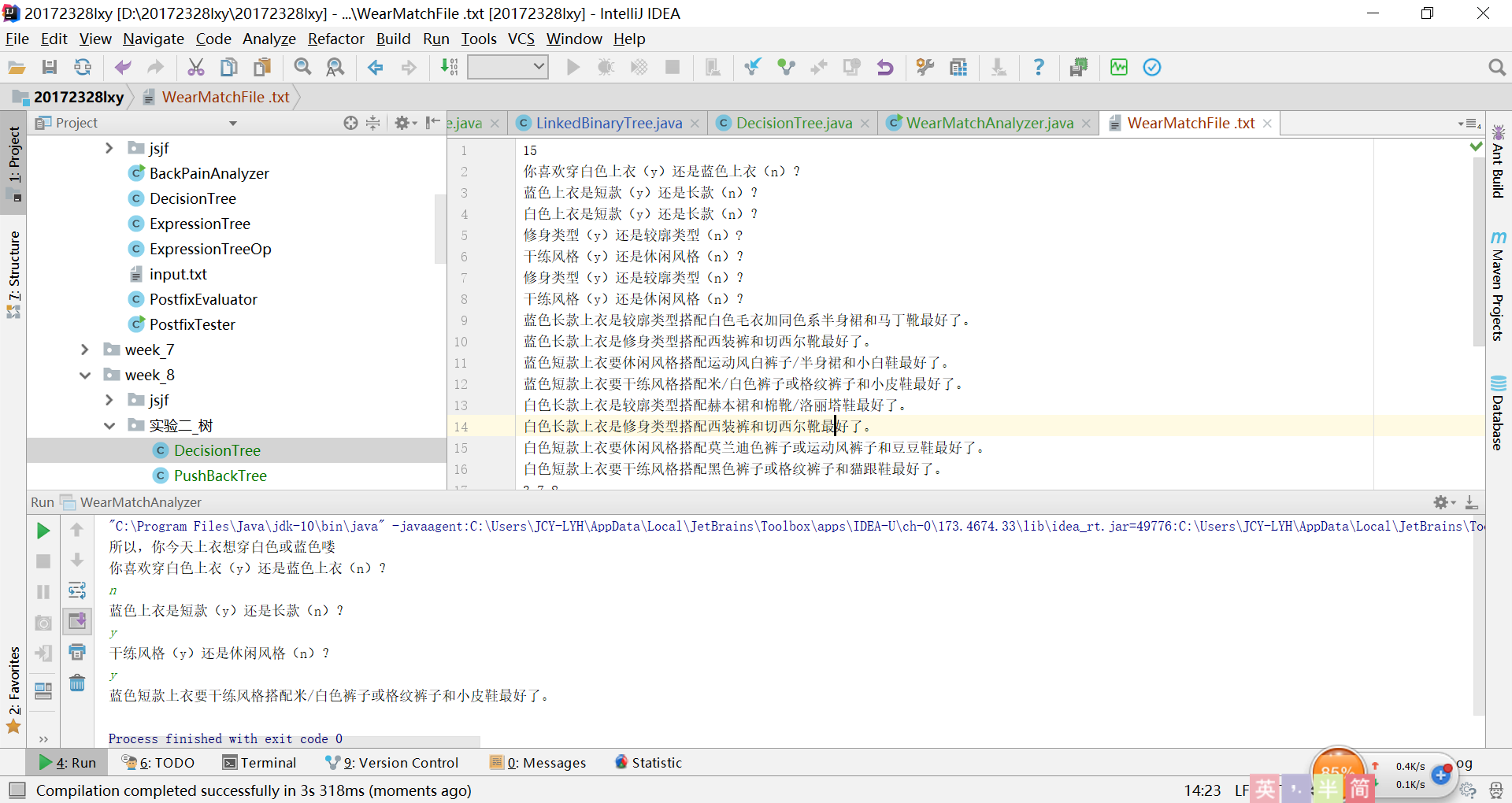
-
实验4:表达式树的解决过程及结果
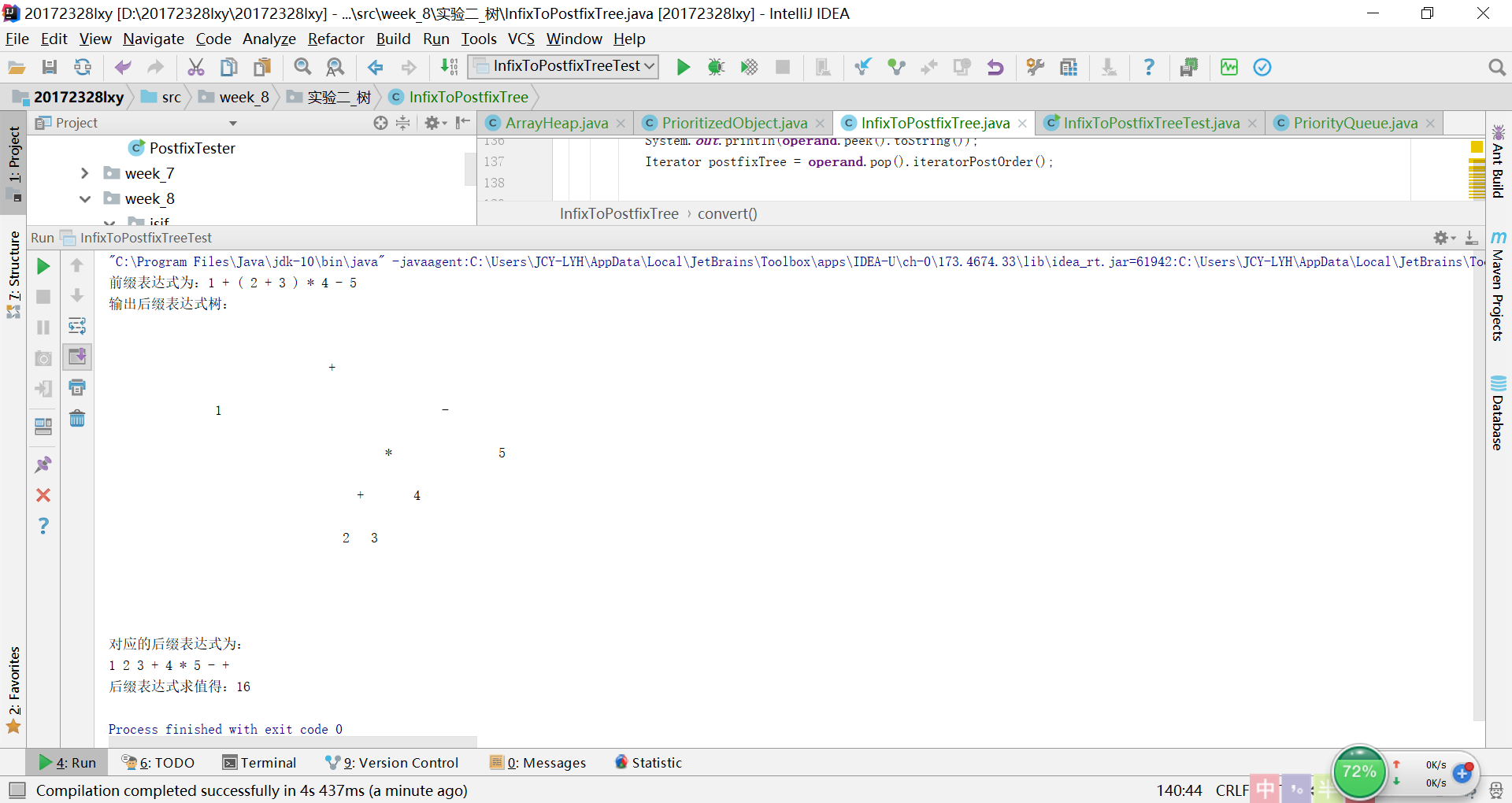
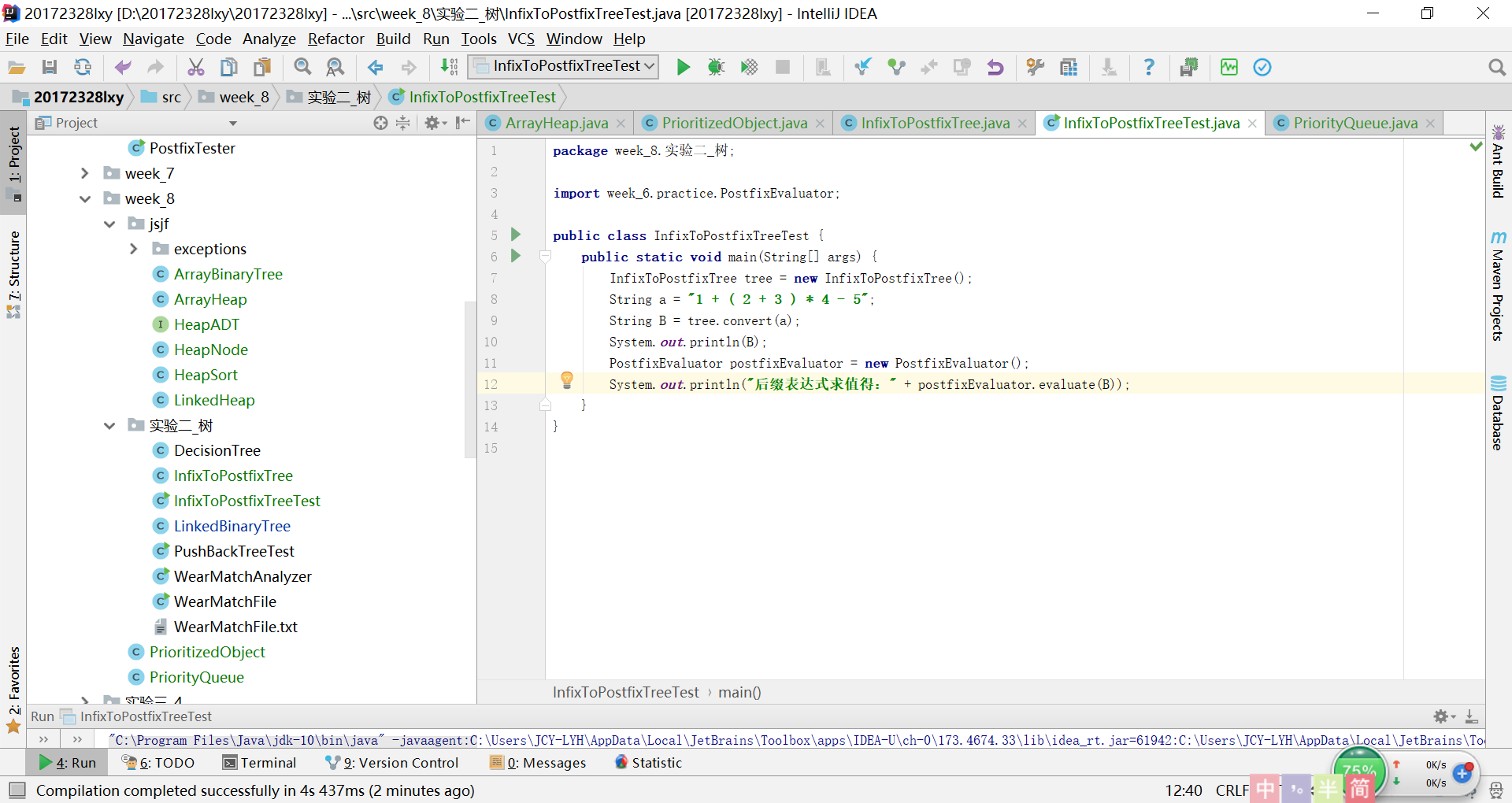
-
实验5:二叉查找树的解决过程及结果
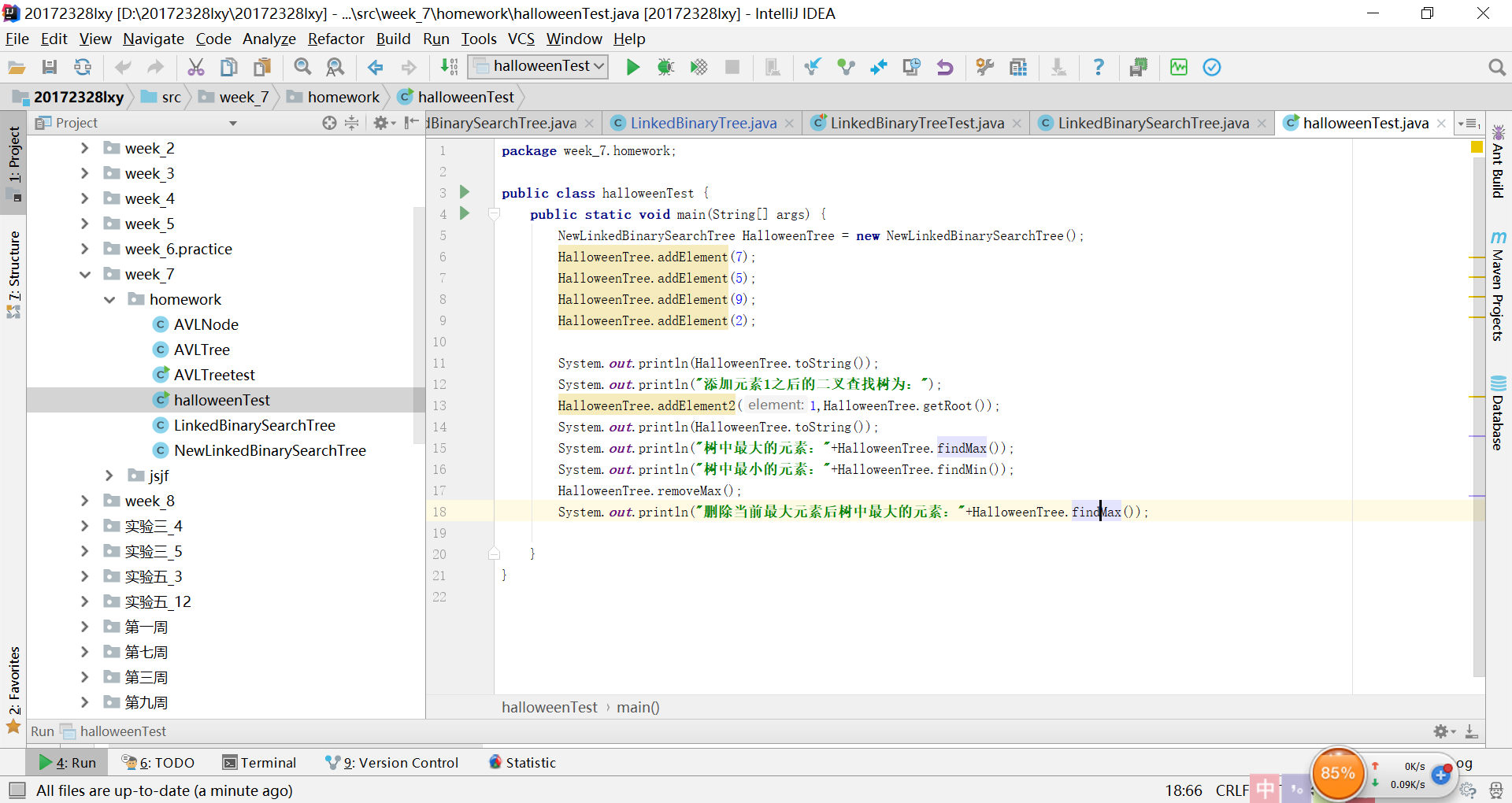
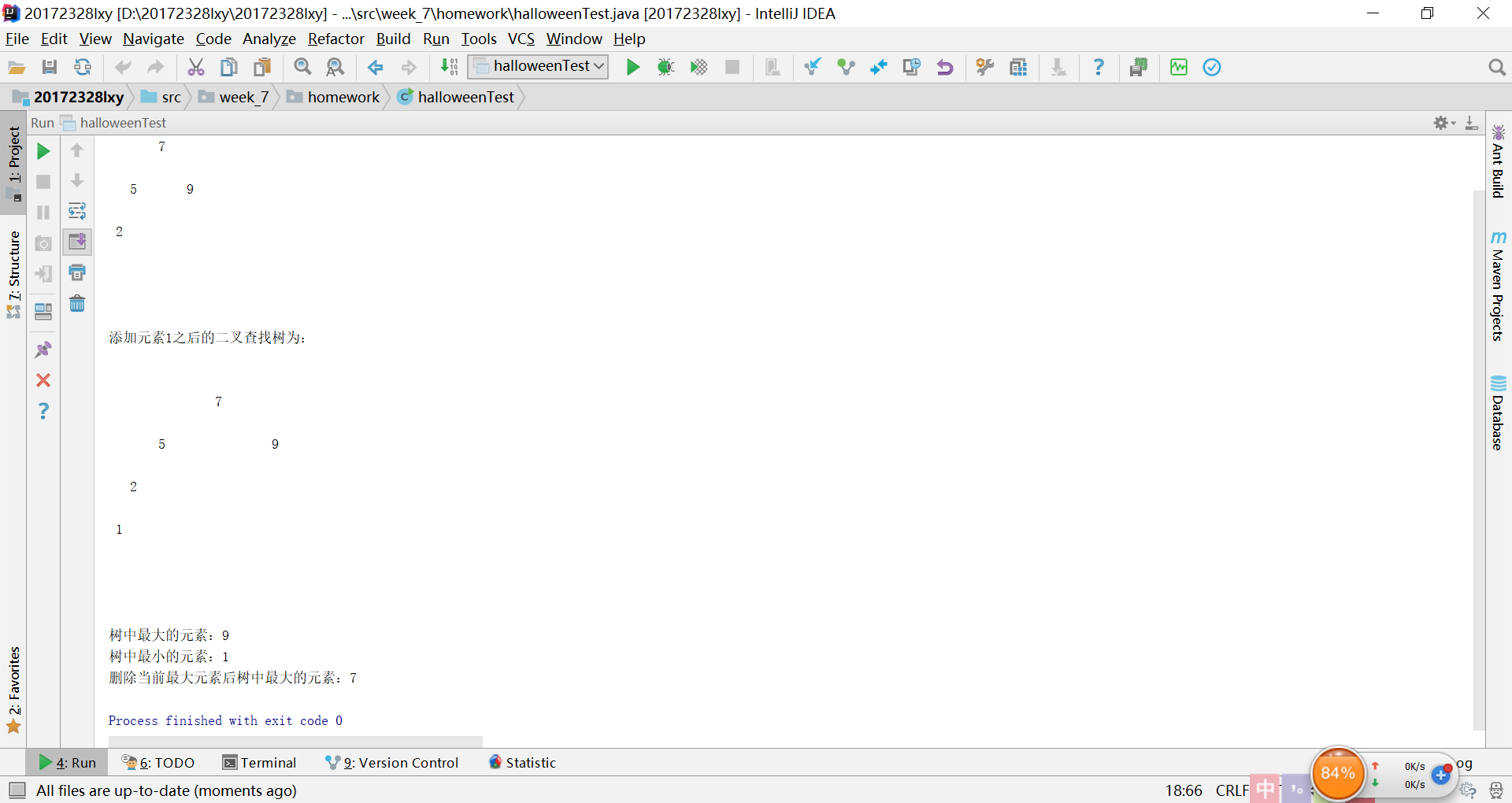
-
实验6 : 红黑树分析的解决过程及结果
写在前面:刚找到TreeMap和HashMap的源码,其实是有些慌张不知所措的,静下心来看一看,发现其实是对很多方法的注释很长,所以两个源码都是很长。
-
首先,我们先要去了解Map是啥?Key是啥?而Value又是啥?
-
在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value。这就是平时说的键值对Key - value。
-
HashMap和TreeMap最本质的区别:
- HashMap通过hashcode方法对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap,因为HashMap中元素的排列顺序是不固定的。
-
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。HashMap继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。HashMap的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。在HashMap中通过get()来获取value,通过put()来插入value,ContainsKey()则用来检验对象是否已经存在。可以看出,和ArrayList的操作相比,HashMap除了通过key索引其内容之外,别的方面差异并不大。
-
TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。TreeMap继承于AbstractMap,所以它是一个Map,即一个key-value集合。TreeMap实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。TreeMap实现了Cloneable接口,意味着它能被克隆。TreeMap实现了java.io.Serializable接口,意味着它支持序列化。TreeMap基于红黑树(Red-Blacktree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。 -
HashMap的源码分析
-
HashMap的构造函数
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)
- 关于HashMap构造函数的理解:
- HashMap遵循集合框架的约束,提供了一个参数为空的构造函数与有一个参数且参数类型为Map的构造函数。除此之外,还提供了两个构造函数,用于设置HashMap的容量(capacity)与平衡因子(loadFactor)。
- 从代码上可以看到,容量与平衡因子都有个默认值,并且容量有个最大值
- 默认的平衡因子为0.75,这是权衡了时间复杂度与空间复杂度之后的最好取值(JDK说是最好的),过高的因子会降低存储空间但是查找(lookup,包括HashMap中的put与get方法)的时间就会增加。
- HashMap的继承关系
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
- 关于HashMap继承和实现的理解:
- 标记接口Cloneable,用于表明HashMap对象会重写java.lang.Object#clone()方法,HashMap实现的是浅拷贝(shallow copy)。
- 标记接口Serializable,用于表明HashMap对象可以被序列化
- HashMap是一种基于哈希表(hash table)实现的map,哈希表(也叫关联数组)一种通用的数据结构,大多数的现代语言都原生支持,其概念也比较简单:key经过hash函数作用后得到一个槽(buckets或slots)的索引(index),槽中保存着我们想要获取的值.
- HashMap的一些重要对象和方法
- HashMap中存放的是HashMap.Entry对象,它继承自Map.Entry,其比较重要的是构造函数。Entry实现了单向链表的功能,用next成员变量来级连起来。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
// setter, getter, equals, toString 方法省略
public final int hashCode() {
//用key的hash值与上value的hash值作为Entry的hash值
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
- HashMap内部维护了一个为数组类型的Entry变量table,用来保存添加进来的Entry对象。其实这是解决冲突的一个方式:链地址法(开散列法)
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
- get操作
public V get(Object key) {
//单独处理key为null的情况
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
if (size == 0) {
return null;
}
//key为null的Entry用于放在table[0]中,但是在table[0]冲突链中的Entry的key不一定为null
//所以需要遍历冲突链,查找key是否存在
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
//首先定位到索引在table中的位置
//然后遍历冲突链,查找key是否存在
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
- put操作(含update操作)
private void inflateTable(int toSize) {
//辅助函数,用于填充HashMap到指定的capacity
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
//threshold为resize的阈值,超过后HashMap会进行resize,内容的entry会进行rehash
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
//这里的循环是关键
//当新增的key所对应的索引i,对应table[i]中已经有值时,进入循环体
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//判断是否存在本次插入的key,如果存在用本次的value替换之前oldValue,相当于update操作
//并返回之前的oldValue
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//如果本次新增key之前不存在于HashMap中,modCount加1,说明结构改变了
modCount++;
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
//如果增加一个元素会后,HashMap的大小超过阈值,需要resize
if ((size >= threshold) && (null != table[bucketIndex])) {
//增加的幅度是之前的1倍
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
//首先得到该索引处的冲突链Entries,有可能为null,不为null
Entry<K,V> e = table[bucketIndex];
//然后把新的Entry添加到冲突链的开头,也就是说,后插入的反而在前面(第一次还真没看明白)
//需要注意的是table[bucketIndex]本身并不存储节点信息,
//它就相当于是单向链表的头指针,数据都存放在冲突链中。
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
//下面看看HashMap是如何进行resize,庐山真面目就要揭晓了
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果已经达到最大容量,那么就直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
//initHashSeedAsNeeded(newCapacity)的返回值决定了是否需要重新计算Entry的hash值
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
//遍历当前的table,将里面的元素添加到新的newTable中
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
//最后这两句用了与put放过相同的技巧
//将后插入的反而在前面
newTable[i] = e;
e = next;
}
}
}
/**
* Initialize the hashing mask value. We defer initialization until we
* really need it.
*/
final boolean initHashSeedAsNeeded(int capacity) {
boolean currentAltHashing = hashSeed != 0;
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
//这里说明了,在hashSeed不为0或满足useAltHash时,会重算Entry的hash值
//至于useAltHashing的作用可以参考下面的链接
// http://stackoverflow.com/questions/29918624/what-is-the-use-of-holder-class-in-hashmap
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
- remove操作
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
//可以看到删除的key如果存在,就返回其所对应的value
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
//这里用了两个Entry对象,相当于两个指针,为的是防治冲突链发生断裂的情况
//这里的思路就是一般的单向链表的删除思路
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
//当table[i]中存在冲突链时,开始遍历里面的元素
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e) //当冲突链只有一个Entry时
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
- TreeMap的源码分析
- TreeMap的构造函数
// 默认构造函数。使用该构造函数,TreeMap中的元素按照自然排序进行排列。
TreeMap()
// 创建的TreeMap包含Map
TreeMap(Map<? extends K, ? extends V> copyFrom)
// 指定Tree的比较器
TreeMap(Comparator<? super K> comparator)
// 创建的TreeSet包含copyFrom
TreeMap(SortedMap<K, ? extends V> copyFrom)
- TreeMap的继承关系
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
- 关于TreeMap继承和实现的理解:
- TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
- TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
- root是红黑数的根节点。它是Entry类型,Entry是红黑数的结点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry结点根据key进行排序,Entry节点包含的内容为value。
- 红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。size是红黑数中结点的个数。
- TreeMap的一些重要方法:
- 是否包含key结点:
public boolean containsKey(Object key) {
return getEntry(key) != null;
}
- 是否包含某个值:
public boolean containsValue(Object value) {
for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e))
if (valEquals(value, e.value))
return true;
return false;
}
- 返回某一TreeMap上的value值
public V get(Object key) {
Entry<K,V> p = getEntry(key);
return (p==null ? null : p.value);
}
- 将某一个特定的Map存入TreeMap并进行自动排序
public void putAll(Map<? extends K, ? extends V> map) {
int mapSize = map.size();
if (size==0 && mapSize!=0 && map instanceof SortedMap) {
Comparator<?> c = ((SortedMap<?,?>)map).comparator();
if (c == comparator || (c != null && c.equals(comparator))) {
++modCount;
try {
buildFromSorted(mapSize, map.entrySet().iterator(),
null, null);
} catch (java.io.IOException | ClassNotFoundException cannotHappen) {
}
return;
}
}
super.putAll(map);
}
- 返回某一个结点
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
- 然后TreeMap中就是NavigableMap API 的方法,SubMaps、public Methods、View classes、Red-black mechanics了。
三、实验过程中遇到的问题和解决过程
-
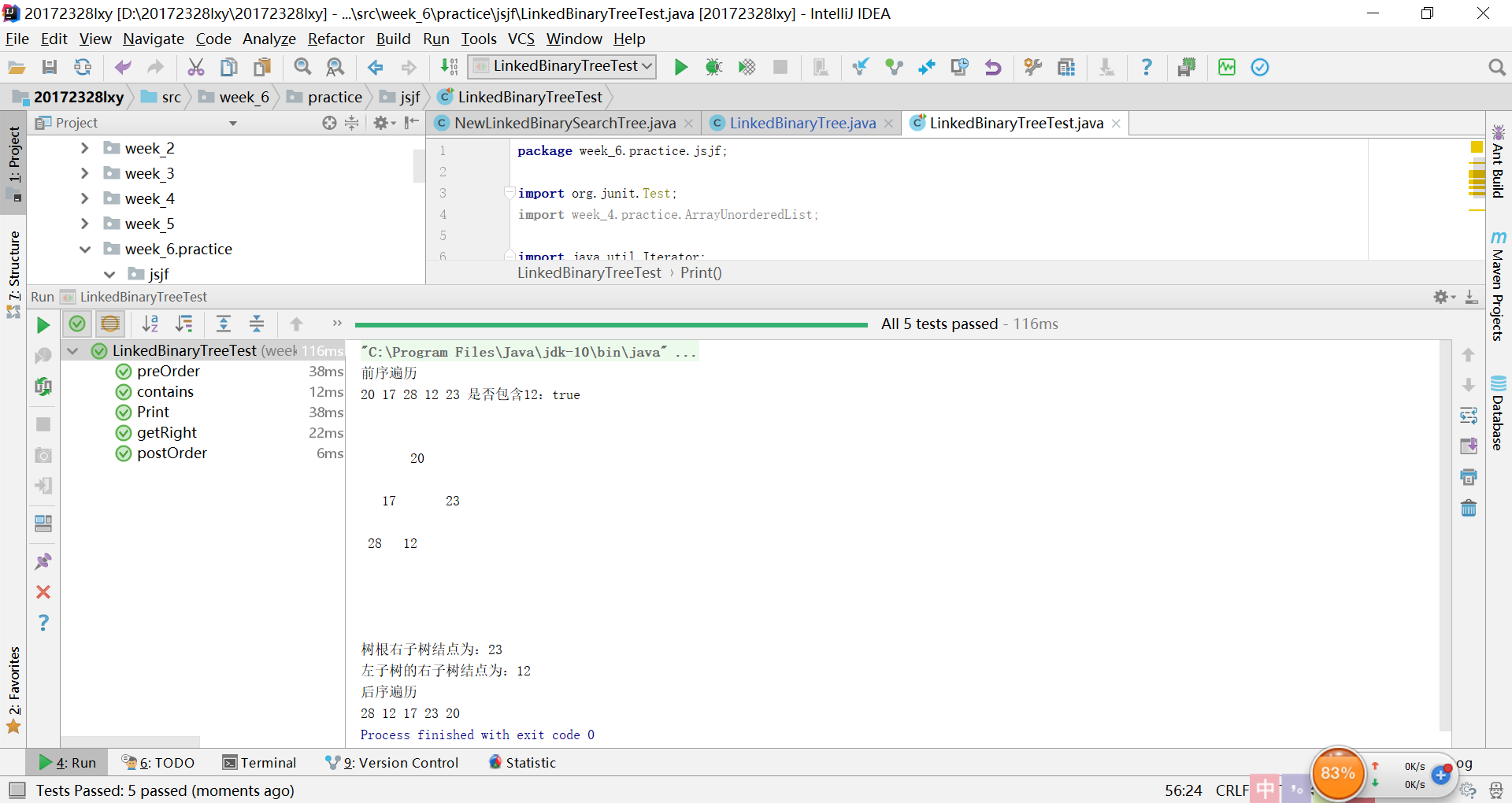
问题1:首先是在做实验1的时候自己不能完整的输出一个数,只能输出包含树根(有三个数)的二叉树,连接在左孩子上的左子树无法正常输出。
-
问题1的解决:通过询问王文彬同学,他教我理解了我代码中存在的问题,其实是因为我构造了两个子树,但却没有连接在一起形成一个完整的树,修改后将左子树
left加入整个树的构造中就可以了。
-
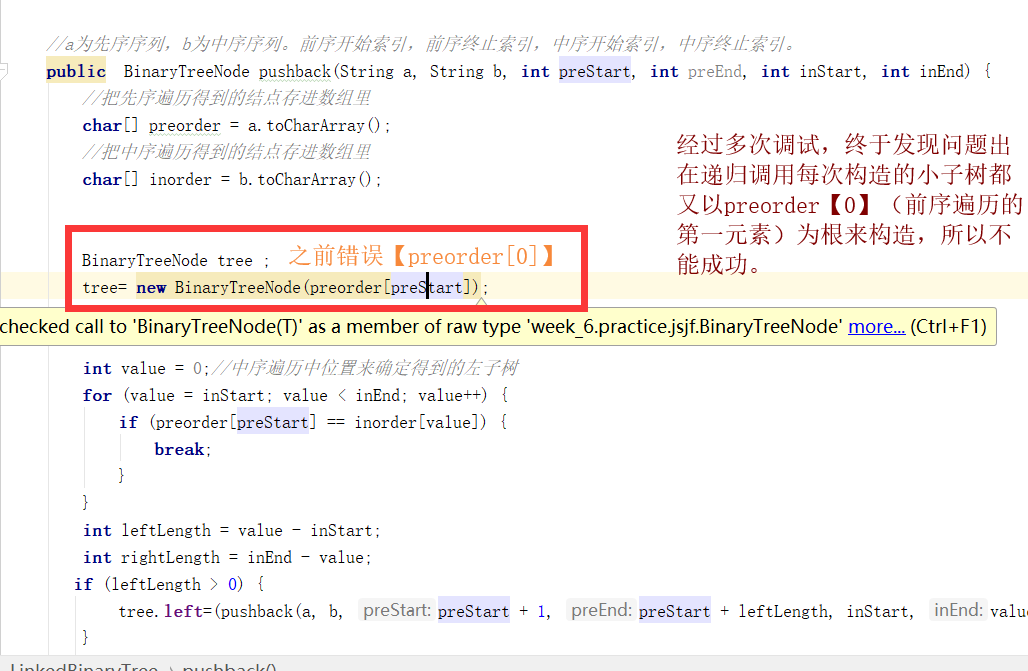
问题2:在实验二我理解完前序输出和中序输出的奥妙之后,终于在苦苦的编码战斗中写完了程序时,测试一下,结果却很适合给学长学姐们国考加油!

-
解决过程:看图说话
-
问题3:在实验三中我的决策树被我独具匠心的写成了一个穿搭教程。但是但是在做的时候还是出现了BUG,当时我记成了Y是通向左子树、N是通向右子树,所以我出现了前言不接后语的问题,当时因为记反了但自己又不知道找了好久的问题。还有就是我当时多加了两个回答语句体,在读文件的时候我把新链接的子树顺序放到了最后,结果出现了问题跳跃,不能衔接。
-
通过认真的多次研究修改,终于我的决策树完美出道了。


- 问题4和问题4的解决:在做实验4的时候没有思路,看了郭恺同学的代码理解了一些,是建立了两个栈,两个栈中存储的数据类型分别是String和树类型,Sring类型来解决操作符,树类型的来解决操作数。
其他(感悟、思考等)
我觉得很多东西理解和代码实现不是一回事,理解了我也不知道如何精确下手,但是在编写的时候我又能更深刻的理解好多遍。虽然过程及其“撕心裂肺”,但是还是要多多受虐,才能在下次受虐的时候减轻疼痛。