第 4 章 Kafka API 实战
4.1 环境准备
1)启动 zk 和 kafka 集群,在 kafka 集群中打开一个消费者
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic first
2)导入 pom 依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.11.0.0</version>
</dependency>
</dependencies>
4.2 Kafka 生产者 Java API
4.2.1 创建生产者(过时的 API)
package com.atguigu.kafka; import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; public class OldProducer { @SuppressWarnings("deprecation") public static void main(String[] args) { Properties properties = new Properties(); properties.put("metadata.broker.list", "hadoop102:9092"); properties.put("request.required.acks", "1"); properties.put("serializer.class", "kafka.serializer.StringEncoder"); Producer<Integer, String> producer = new Producer<Integer,String>(new ProducerConfig(properties)); KeyedMessage<Integer, String> message = new KeyedMessage<Integer, String>("first", "hello world"); producer.send(message ); } }
4.2.2 创建生产者(新 API)
package com.atguigu.kafka; import java.util.Properties; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord;
public class NewProducer {
public static void main(String[] args) {
Properties props = new Properties(); // Kafka 服务端的主机名和端口号 props.put("bootstrap.servers", "hadoop103:9092"); // 等待所有副本节点的应答 props.put("acks", "all"); // 消息发送最大尝试次数 props.put("retries", 0); // 一批消息处理大小 props.put("batch.size", 16384); // 请求延时 props.put("linger.ms", 1); // 发送缓存区内存大小 props.put("buffer.memory", 33554432); // key 序列化 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value 序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 50; i++) { producer.send(new ProducerRecord<String, String>("first", Integer.toString(i), "hello world-" + i)); } producer.close(); } }
4.2.3 创建生产者带回调函数(新 API)
[lxl@hadoop102 kafka]$ bin/kafka-topics.sh --zookeeper hadoop102:2181 --create --topic second --partitions 3 --replication-factor 2 Created topic "second".
[lxl@hadoop102 kafka]$ bin/kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic second
package com.atlxl.producer; import org.apache.kafka.clients.Metadata; import org.apache.kafka.clients.producer.*; import java.util.Properties; public class CustomerProducer { public static void main(String[] args) { //配置信息 Properties props = new Properties(); // Kafka 服务端的主机名和端口号 props.put("bootstrap.servers", "hadoop102:9092"); // 等待所有副本节点的应答 props.put("acks", "all"); // 消息发送最大尝试次数(应答级别 ) props.put("retries", 0); // 一批消息处理大小 props.put("batch.size", 16384); // 请求延时 props.put("linger.ms", 1); // 发送缓存区内存大小 props.put("buffer.memory", 33554432); // key 序列化 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value 序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); KafkaProducer<String, String> producer = new KafkaProducer(props); for (int i = 0; i < 10; i++) { producer.send(new ProducerRecord<String, String>("second", String.valueOf(i)), new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { System.out.println(recordMetadata.partition() + "--" + recordMetadata.offset()); }else { System.out.println("发送失败!"); } } }); } //关闭资源 producer.close(); } }
执行结果:
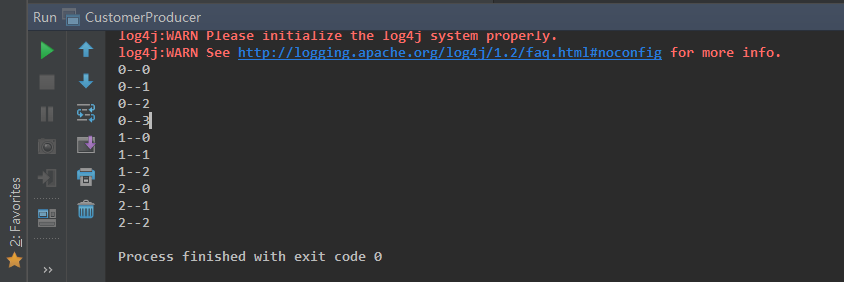
0--0 0--1 0--2 0--3 1--0 1--1 1--2 2--0 2--1 2--2
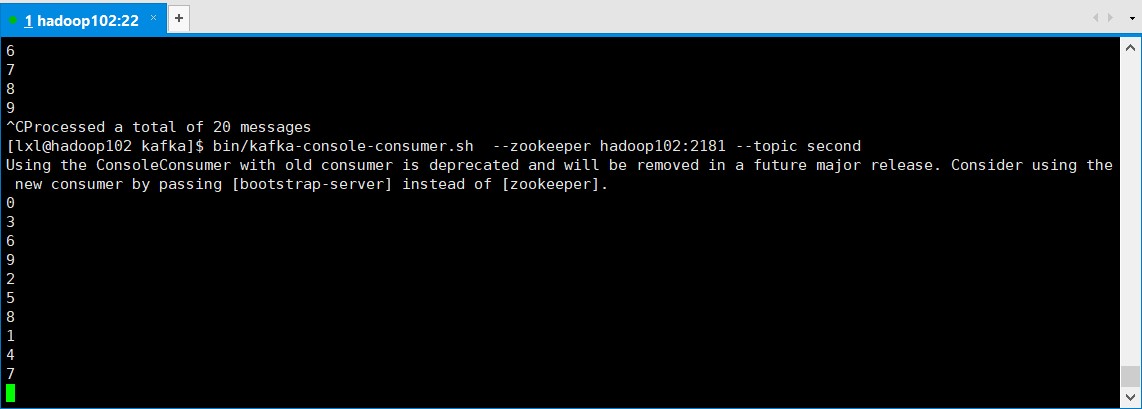
0 3 6 9 2 5 8 1 4 7
4.2.4 自定义分区生产者
0)需求:将所有数据存储到 topic 的第 0 号分区上
1)定义一个类实现 Partitioner 接口,重写里面的方法(过时 API)
package com.atguigu.kafka; import java.util.Map; import kafka.producer.Partitioner;
public class CustomPartitioner implements Partitioner { public CustomPartitioner() { super(); } @Override public int partition(Object key, int numPartitions) { // 控制分区 return 0; } }
2)自定义分区(新 API)
package com.atguigu.kafka; import java.util.Map; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster;
public class CustomPartitioner implements Partitioner { @Override public void configure(Map<String, ?> configs) { } @Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { // 控制分区 return 0; }
@Override public void close() {
} }
3)在代码中调用
package com.atguigu.kafka; import java.util.Properties; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord;
public class PartitionerProducer { public static void main(String[] args) {
Properties props = new Properties(); // Kafka 服务端的主机名和端口号 props.put("bootstrap.servers", "hadoop103:9092"); // 等待所有副本节点的应答 props.put("acks", "all"); // 消息发送最大尝试次数 props.put("retries", 0); // 一批消息处理大小 props.put("batch.size", 16384); // 增加服务端请求延时 props.put("linger.ms", 1); // 发送缓存区内存大小 props.put("buffer.memory", 33554432); // key 序列化 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value 序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 自定义分区 props.put("partitioner.class", "com.atguigu.kafka.CustomPartitioner");
Producer<String, String> producer = new KafkaProducer<>(props); producer.send(new ProducerRecord<String, String>("first", "1", "atguigu"));
producer.close(); } }
4)测试
(1)在 hadoop102 上监控/opt/module/kafka/logs/目录下 first 主题 3 个分区的 log 日志动
态变化情况
[atguigu@hadoop102 first-0]$ tail -f 00000000000000000000.log [atguigu@hadoop102 first-1]$ tail -f 00000000000000000000.log [atguigu@hadoop102 first-2]$ tail -f 00000000000000000000.log
(2)发现数据都存储到指定的分区了。
测试:
package com.atlxl.producer; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import java.util.Map; public class CustomerPartitioner implements Partitioner { public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { // 控制分区 return 0; } public void close() { } public void configure(Map<String, ?> map) { } }
package com.atlxl.producer; import org.apache.kafka.clients.Metadata; import org.apache.kafka.clients.producer.*; import java.util.Properties; public class CustomerProducer { public static void main(String[] args) { //配置信息 Properties props = new Properties(); // Kafka 服务端的主机名和端口号 props.put("bootstrap.servers", "hadoop102:9092"); // 等待所有副本节点的应答 props.put("acks", "all"); // 消息发送最大尝试次数(应答级别 ) props.put("retries", 0); // 一批消息处理大小 props.put("batch.size", 16384); // 请求延时 props.put("linger.ms", 1); // 发送缓存区内存大小 props.put("buffer.memory", 33554432); // key 序列化 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // value 序列化 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("partitioner.class", "com.atlxl.producer.CustomerPartitioner"); KafkaProducer<String, String> producer = new KafkaProducer(props); for (int i = 0; i < 10; i++) { producer.send(new ProducerRecord<String, String>("second", String.valueOf(i)), new Callback() { public void onCompletion(RecordMetadata recordMetadata, Exception e) { if (e == null) { System.out.println(recordMetadata.partition() + "--" + recordMetadata.offset()); }else { System.out.println("发送失败!"); } } }); } //关闭资源 producer.close(); } }
结果:

0--4 0--5 0--6 0--7 0--8 0--9 0--10 0--11 0--12 0--13
4.3 Kafka 消费者 Java API
4.3.1 高级 API
0)在控制台创建发送者
1)创建消费者(过时 API)
package com.atguigu.kafka.consume; import kafka.consumer.Consumer; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; public class sfsfs { } import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; public class CustomConsumer { @SuppressWarnings("deprecation") public static void main(String[] args) { Properties properties = new Properties(); properties.put("zookeeper.connect", "hadoop102:2181"); properties.put("group.id", "g1"); properties.put("zookeeper.session.timeout.ms", "500"); properties.put("zookeeper.sync.time.ms", "250"); properties.put("auto.commit.interval.ms", "1000"); // 创建消费者连接器 ConsumerConnector consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(properties)); HashMap<String, Integer> topicCount = new HashMap<>(); topicCount.put("first", 1); Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCount); KafkaStream<byte[], byte[]> stream = consumerMap.get("first").get(0); ConsumerIterator<byte[], byte[]> it = stream.iterator(); while (it.hasNext()) { System.out.println(new String(it.next().message())); } } }
2)官方提供案例(自动维护消费情况)(新 API)
package com.atguigu.kafka.consume; import java.util.Arrays; import java.util.Properties; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; public class CustomNewConsumer { public static void main(String[] args) { Properties props = new Properties(); // 定义 kakfa 服务的地址,不需要将所有 broker 指定上 props.put("bootstrap.servers", "hadoop102:9092"); // 制定 consumer group props.put("group.id", "test"); // 是否自动确认 offset props.put("enable.auto.commit", "true"); // 自动确认 offset 的时间间隔 props.put("auto.commit.interval.ms", "1000"); // key 的序列化类 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // value 的序列化类 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // 定义 consumer KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // 消费者订阅的 topic, 可同时订阅多个 consumer.subscribe(Arrays.asList("first", "second", "third")); while (true) { // 读取数据,读取超时时间为 100ms ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } } }
练习:
package com.atlxl.consumer; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays; import java.util.Properties; public class CustomerConsumer { public static void main(String[] args) { //配置信息 Properties props = new Properties(); //kafka集群 props.put("bootstrap.servers", "hadoop102:9092"); //消费者组id props.put("group.id", "test"); //设置自动提交offset props.put("enable.auto.commit", "false"); //提交延时 props.put("auto.commit.interval.ms", "1000"); //KV的反序列化 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //创建消费者对象 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); //指定Topic consumer.subscribe(Arrays.asList("second", "first", "third")); while (true) { //获取数据 ConsumerRecords<String, String> consumerRecords = consumer.poll(100); for (ConsumerRecord<String, String> record : consumerRecords) { System.out.println(record.topic() + "--" + record.partition() + "--" + record.value()); } } } }
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic second bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
4.3.2 低级 API
实现使用低级 API 读取指定 topic,指定 partition,指定 offset 的数据。
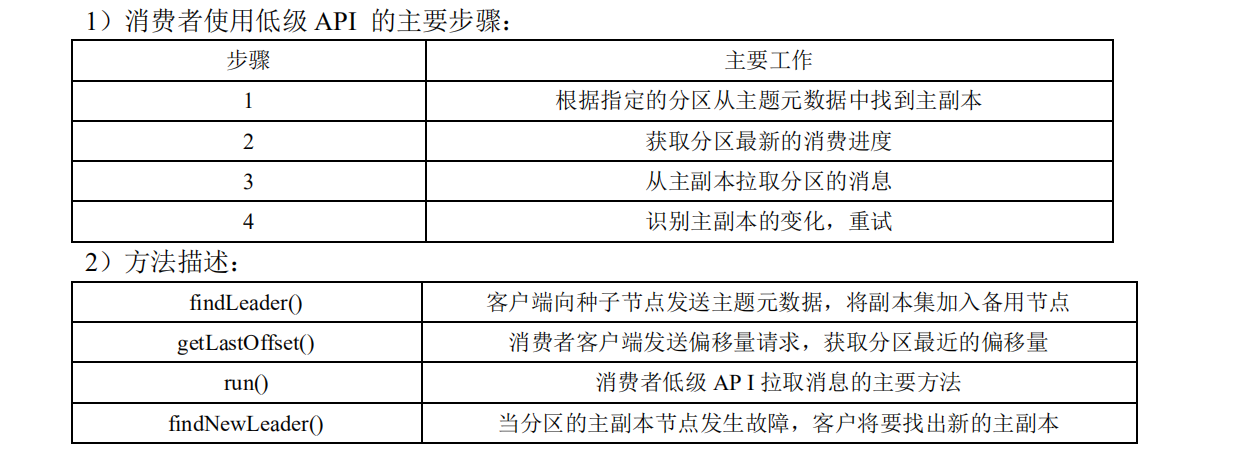
3)代码:
package com.atguigu; import java.nio.ByteBuffer; import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map; import kafka.api.FetchRequest; import kafka.api.FetchRequestBuilder; import kafka.api.PartitionOffsetRequestInfo; import kafka.cluster.BrokerEndPoint; import kafka.common.ErrorMapping; import kafka.common.TopicAndPartition; import kafka.javaapi.FetchResponse; import kafka.javaapi.OffsetResponse; import kafka.javaapi.PartitionMetadata; import kafka.javaapi.TopicMetadata; import kafka.javaapi.TopicMetadataRequest; import kafka.javaapi.consumer.SimpleConsumer; import kafka.message.MessageAndOffset; public class SimpleExample { private List<String> m_replicaBrokers = new ArrayList<>(); public SimpleExample() { m_replicaBrokers = new ArrayList<>(); } public static void main(String args[]) { SimpleExample example = new SimpleExample(); // 最大读取消息数量 long maxReads = Long.parseLong("3"); // 要订阅的 topic String topic = "test1"; // 要查找的分区 int partition = Integer.parseInt("0"); // broker 节点的 ip List<String> seeds = new ArrayList<>(); seeds.add("192.168.9.102"); seeds.add("192.168.9.103"); seeds.add("192.168.9.104"); // 端口 int port = Integer.parseInt("9092"); try { example.run(maxReads, topic, partition, seeds, port); } catch (Exception e) { System.out.println("Oops:" + e); e.printStackTrace(); } } public void run(long a_maxReads, String a_topic, int a_partition, List<String> a_seedBrokers, int a_port) throws Exception { // 获取指定 Topic partition 的元数据 PartitionMetadata metadata = findLeader(a_seedBrokers, a_port, a_topic, a_partition); if (metadata == null) { System.out.println("Can't find metadata for Topic and Partition. Exiting"); return; } if (metadata.leader() == null) { System.out.println("Can't find Leader for Topic and Partition. Exiting"); return; } String leadBroker = metadata.leader().host(); String clientName = "Client_" + a_topic + "_" + a_partition; SimpleConsumer consumer = new SimpleConsumer(leadBroker, a_port, 100000, 64 * 1024, clientName); long readOffset = getLastOffset(consumer, a_topic, a_partition, kafka.api.OffsetRequest.EarliestTime(), clientName); int numErrors = 0; while (a_maxReads > 0) { if (consumer == null) { consumer = new SimpleConsumer(leadBroker, a_port, 100000, 64 * 1024, clientName); } FetchRequest req = new FetchRequestBuilder().clientId(clientName).addFetch(a_topic, a_partition, readOffset, 100000).build(); FetchResponse fetchResponse = consumer.fetch(req); if (fetchResponse.hasError()) { numErrors++; // Something went wrong! short code = fetchResponse.errorCode(a_topic, a_partition); System.out.println("Error fetching data from the Broker:" + leadBroker + " Reason: " + code); if (numErrors > 5) break; if (code == ErrorMapping.OffsetOutOfRangeCode()) { // We asked for an invalid offset. For simple case ask for // the last element to reset readOffset = getLastOffset(consumer, a_topic, a_partition, kafka.api.OffsetRequest.LatestTime(), clientName); continue; } consumer.close(); consumer = null; leadBroker = findNewLeader(leadBroker, a_topic, a_partition, a_port); continue; } numErrors = 0; long numRead = 0; for (MessageAndOffset messageAndOffset : fetchResponse.messageSet(a_topic, a_partition)) { long currentOffset = messageAndOffset.offset(); if (currentOffset < readOffset) { System.out.println("Found an old offset: " + currentOffset + " Expecting: " + readOffset); continue; } readOffset = messageAndOffset.nextOffset(); ByteBuffer payload = messageAndOffset.message().payload(); byte[] bytes = new byte[payload.limit()]; payload.get(bytes); System.out.println(String.valueOf(messageAndOffset.offset()) + ": " + new String(bytes, "UTF-8")); numRead++; a_maxReads--; } if (numRead == 0) { try { Thread.sleep(1000); } catch (InterruptedException ie) { } } } if (consumer != null) consumer.close(); } public static long getLastOffset(SimpleConsumer consumer, String topic, int partition, long whichTime, String clientName) { TopicAndPartition topicAndPartition = new TopicAndPartition(topic, partition); Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<TopicAndPartition, PartitionOffsetRequestInfo>(); requestInfo.put(topicAndPartition, new PartitionOffsetRequestInfo(whichTime, 1)); kafka.javaapi.OffsetRequest request = new kafka.javaapi.OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName); OffsetResponse response = consumer.getOffsetsBefore(request); if (response.hasError()) { System.out.println("Error fetching data Offset Data the Broker. Reason: " + response.errorCode(topic, partition)); return 0; } long[] offsets = response.offsets(topic, partition); return offsets[0]; } private String findNewLeader(String a_oldLeader, String a_topic, int a_partition, int a_port) throws Exception { for (int i = 0; i < 3; i++) { boolean goToSleep = false; PartitionMetadata metadata = findLeader(m_replicaBrokers, a_port, a_topic, a_partition); if (metadata == null) { goToSleep = true; } else if (metadata.leader() == null) { goToSleep = true; } else if (a_oldLeader.equalsIgnoreCase(metadata.leader().host()) && i == 0) { // first time through if the leader hasn't changed give // ZooKeeper a second to recover // second time, assume the broker did recover before failover, // or it was a non-Broker issue // goToSleep = true; } else { return metadata.leader().host(); } if (goToSleep) { Thread.sleep(1000); } } System.out.println("Unable to find new leader after Broker failure. Exiting"); throw new Exception("Unable to find new leader after Broker failure. Exiting"); } private PartitionMetadata findLeader(List<String> a_seedBrokers, int a_port, String a_topic, int a_partition) { PartitionMetadata returnMetaData = null; loop: for (String seed : a_seedBrokers) { SimpleConsumer consumer = null; try { consumer = new SimpleConsumer(seed, a_port, 100000, 64 * 1024, "leaderLookup"); List<String> topics = Collections.singletonList(a_topic); TopicMetadataRequest req = new TopicMetadataRequest(topics); kafka.javaapi.TopicMetadataResponse resp = consumer.send(req); List<TopicMetadata> metaData = resp.topicsMetadata(); for (TopicMetadata item : metaData) { for (PartitionMetadata part : item.partitionsMetadata()) { if (part.partitionId() == a_partition) { returnMetaData = part; break loop; } } } } catch (Exception e) { System.out.println("Error communicating with Broker [" + seed + "] to find Leader for [" + a_topic + ", " + a_partition + "] Reason: " + e); } finally { if (consumer != null) consumer.close(); } } if (returnMetaData != null) { m_replicaBrokers.clear(); for (BrokerEndPoint replica : returnMetaData.replicas()) { m_replicaBrokers.add(replica.host()); } } return returnMetaData; } }
练习代码:
package com.atlxl.consumer; /* 根据指定的Topic,Partition,offset来获取数据 */ import kafka.api.FetchRequestBuilder; import kafka.cluster.BrokerEndPoint; import kafka.javaapi.*; import kafka.javaapi.consumer.SimpleConsumer; import kafka.javaapi.message.ByteBufferMessageSet; import kafka.message.MessageAndOffset; import java.nio.ByteBuffer; import java.util.ArrayList; import java.util.Collections; import java.util.List; public class LowerConsumer { public static void main(String[] args) { //定义相关参数 ArrayList<String> brokers = new ArrayList<>();//kafka集群 brokers.add("hadoop102"); brokers.add("hadoop103"); brokers.add("hadoop104"); //端口号 int port = 9092; //主题 String topic = "second"; //分区 int partition = 0; //offset long offset = 2; LowerConsumer lowerConsumer = new LowerConsumer(); lowerConsumer.getData(brokers,port,topic,partition,offset); } //找分区leader private BrokerEndPoint findLeader(List<String> brokers, int port, String topic, int partition) { for (String broker : brokers) { //创建获取分区leader的消费对象 SimpleConsumer getLeader = new SimpleConsumer(broker, port, 100, 1024 * 4, "getLeader"); //创建一个主题元数据请求 TopicMetadataRequest topicMetadataRequest = new TopicMetadataRequest(Collections.singletonList(topic)); //获取主题元数据返回值 TopicMetadataResponse metadataResponse = getLeader.send(topicMetadataRequest); //解析元数据返回值 List<TopicMetadata> topicsMetadata = metadataResponse.topicsMetadata(); //遍历主题元数据 for (TopicMetadata topicMetadatum : topicsMetadata) { //获取多个分区的元数据信息 List<PartitionMetadata> partitionsMetadata = topicMetadatum.partitionsMetadata(); //遍历分区元数据 for (PartitionMetadata partitionMetadatum : partitionsMetadata) { if (partition == partitionMetadatum.partitionId()){ return partitionMetadatum.leader(); } } } } return null; } //获取数据 private void getData(List<String> brokers, int port, String topic, int partition, long offset) { //获取分区leader BrokerEndPoint leader = findLeader(brokers, port, topic, partition); if (leader == null) { return; } //获取数据的消费者对象 String leaderHost = leader.host(); SimpleConsumer getData = new SimpleConsumer(leaderHost, port, 1000, 1024 * 4, "getData"); //创建获取数据的对象 kafka.api.FetchRequest fetchRequest = new FetchRequestBuilder().addFetch(topic, partition, offset, 100000).build(); //获取数据返回值 FetchResponse fetchResponse = getData.fetch(fetchRequest); //解析返回值 ByteBufferMessageSet messageAndOffsets = fetchResponse.messageSet(topic, partition); //遍历并打印 for (MessageAndOffset messageAndOffset : messageAndOffsets) { long offset1 = messageAndOffset.offset(); ByteBuffer payload = messageAndOffset.message().payload(); byte[] bytes = new byte[payload.limit()]; payload.get(bytes); System.out.println(offset1 + "--" + new String(bytes)); } } }
扩展
[lxl@hadoop102 kafka]$ vi config/consumer.properties
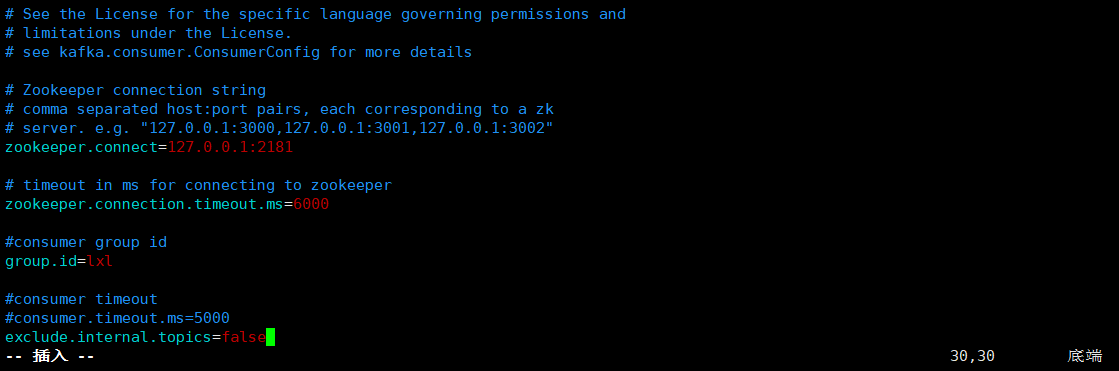
[lxl@hadoop102 config]$ xsync consumer.properties
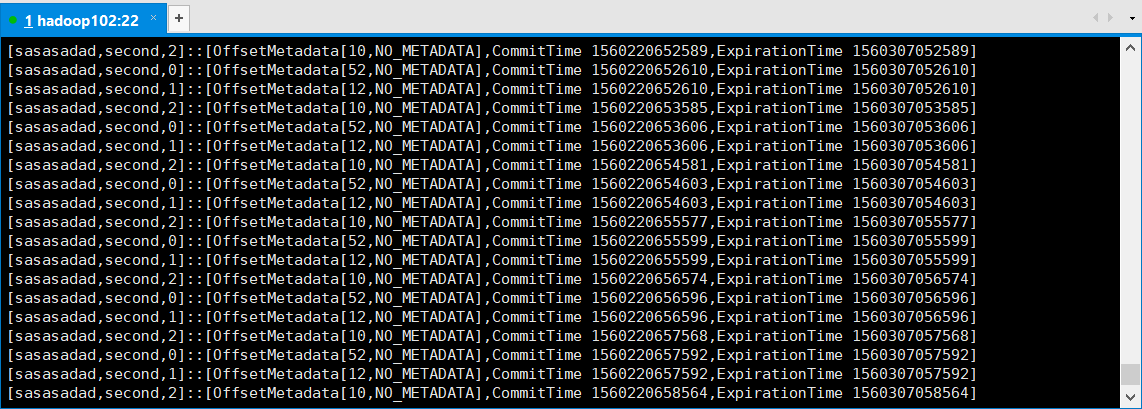
[lxl@hadoop102 config]$ bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager$OffsetsMessageFormatter" --consumer.config config/consumer.properties