/** * */ package com.lxl.hadoop.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * Description: * * @author LXL * @date 2019年5月23日 */ public class MyWC { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true); Job job = Job.getInstance(conf); // Create a new Job // Job job = Job.getInstance(); job.setJarByClass(MyWC.class); // Specify various job-specific parameters job.setJobName("ooxx"); //输入 // job.setInputPath(new Path("in")); // job.setOutputPath(new Path("out")); Path input = new Path("/user/root/test.txt"); FileInputFormat.addInputPath(job, input ); //输出 Path output = new Path("/data/wc/output"); if(output.getFileSystem(conf).exists(output)){ output.getFileSystem(conf).delete(output, true); } FileOutputFormat.setOutputPath(job, output); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete job.waitForCompletion(true); } }
/** * */ package com.lxl.hadoop.mr; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * Description: * * @author LXL * @date 2019年5月24日 */ public class MyMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // hello sxt 102 StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
/** * */ package com.lxl.hadoop.mr; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /** * Description: * * @author LXL * @date 2019年5月24日 */ public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { // 相同的key为一组。。调用一次reduce方法,在方法内迭代这一组数据,进行计算:sum count max min..... private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //hello 1 //hello 1 //..... //key: hello //values:(1,1,...) int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }

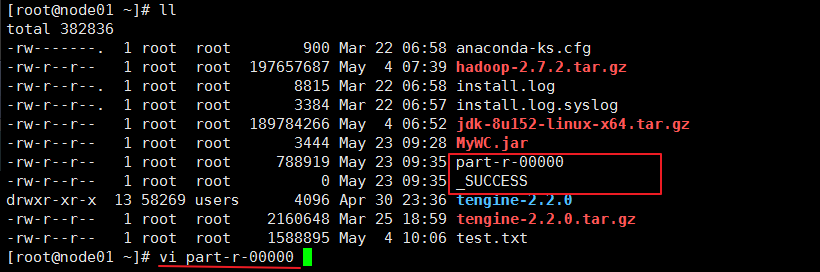
导出JAR包:




需要计算文件的目录位置:
执行jar包:
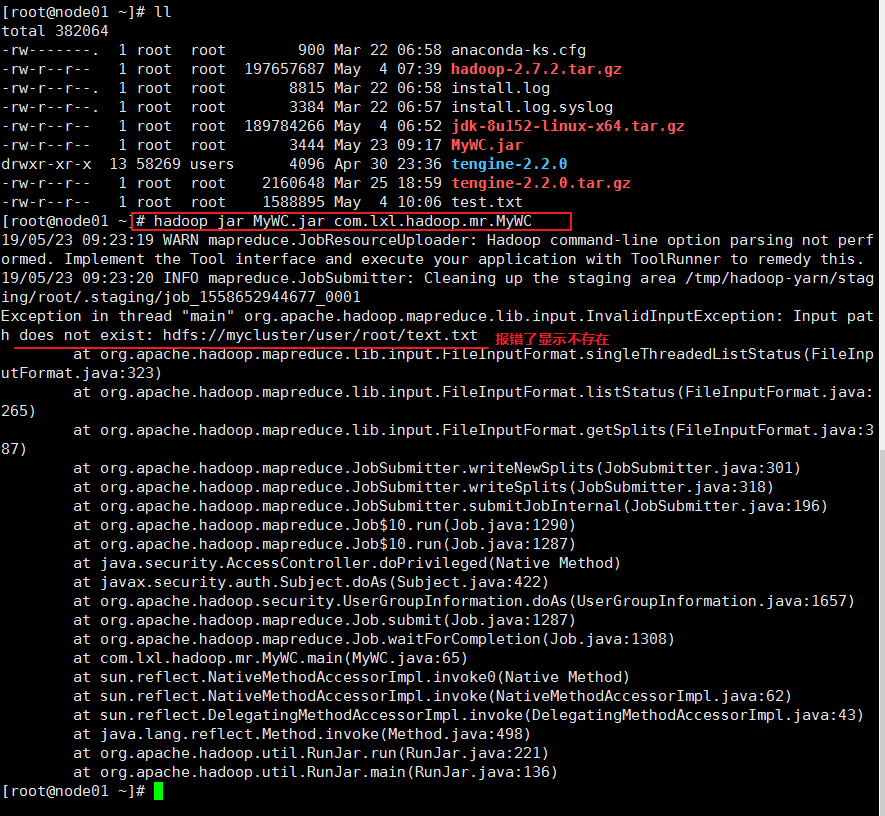
修改自己写的代码。重新上传jar包
重新执行: