1. 弱监督视觉理解
1.1 弱监督学习简介
- 不完全监督:只有一部分训练数据具备标签;
- 不确切监督:训练数据只具备粗粒度标签;
- 不准确监督:给出的标签并不总是真值;(标签有噪声?)
- 弱监督的含义:弱监督给出的标签会在某种程度上弱于我们面临的任务所要求的输出。
- 研究背景:
- 数据集很重要:现阶段CV领域的大多数问题还是依赖于特定的数据集进行训练和测试评估的;
- 标注成本很大:高质量额图像标注为我们进行图像理解提供了方便,但获取精确的标注是非常困难和耗时的;
- 研究方法难选:深度神经网络共性技术,视觉基元属性感知。
1.2 VALSE2019中弱监督的新方法
1.2.1 mingming chen (NKU)
-
Motivation:
当前各种深度网络的进步得益于网络多尺度信息综合能力的提升
-
报告主要内容:
- 富尺度空间神经网络架构:多任务协同求解,鲁棒性提高;
- 显著性物体检测:预设基元属性感知能力,减少数据依赖;
- 互联网大数据自主学习:减少人工标注,自动学习。

-
富尺度空间神经网络是什么?
- 网络结构:一个富尺度空间的深度神经网络通用架构,在每一个基础网络上,对图像进行深度(?)层上的分割,然后通过不同尺度的处理再结合到输出。
- 学习目标:富尺度指代通过CNN学习图像的位移、平移、形变等特性;
- 设计基准:金字塔结构;空间池化;残差学习。
- papers:
- Res2Net: A new Multi-scale Backbone Architecture, TPAMI2019 (in submission)

-
显著性物体检测分类:
- 3种任务:RGBD显著性物体检测,边缘检测,视觉注意力机制若监督语义分割
- 基于属性预先构建:预先构建显著性物体检测、边缘提取等 任务无关的基元属性 感知能力,减少具体任务中的数据依赖,实现“举一反三”
- 通用视觉基元属性感知方法分类
- papers:
- Deeply supervised salient object detection with short connection (ECCV2018)

-
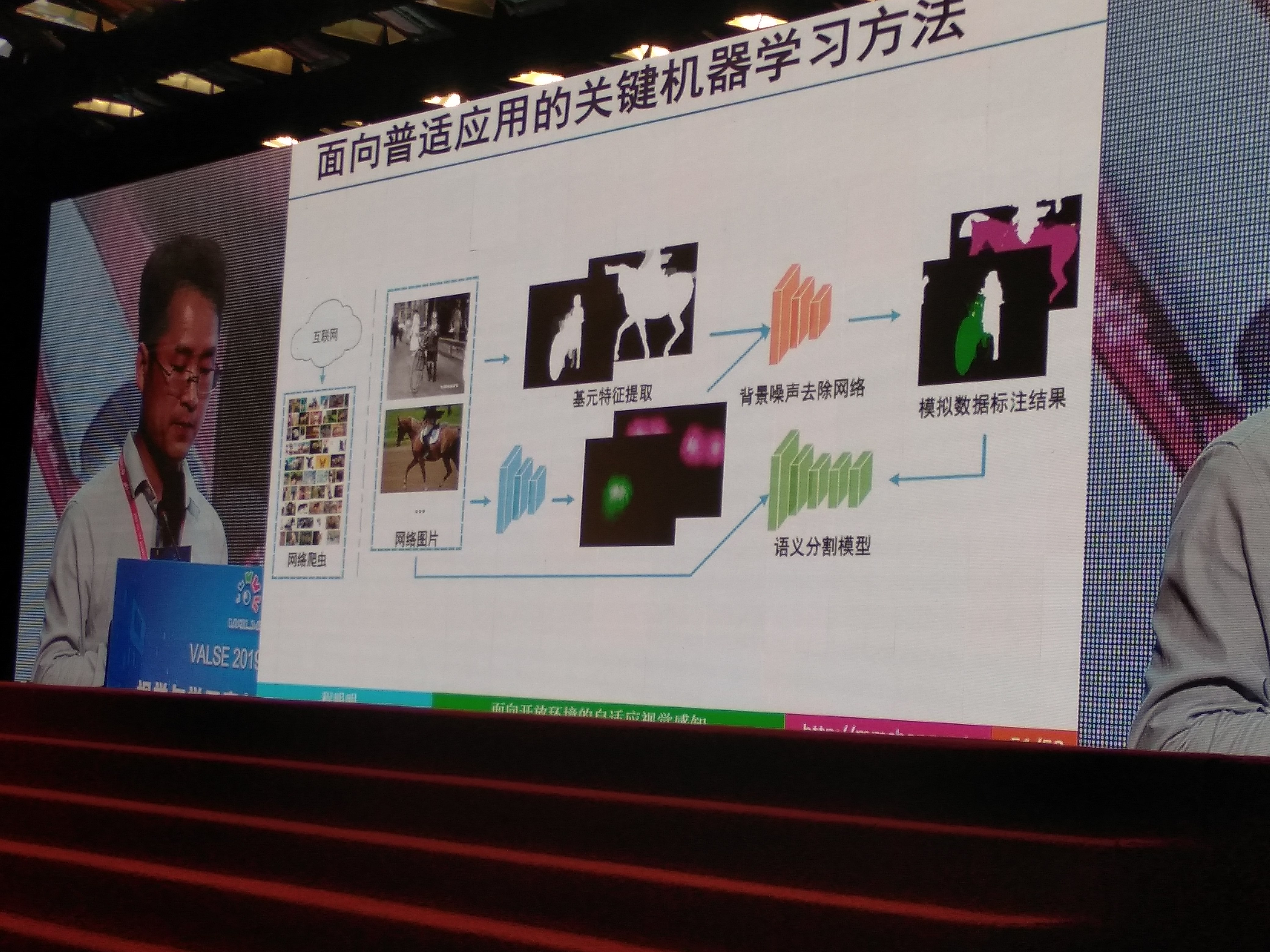
互联网大数据自主学习:
利用互联网海量多媒体数据,减少对人工标注数据的依赖,自主学习目标类别的识别与检测模型,实现系统只能的自主发育

1.2.2 qixiang ye (CAS)
-
现状
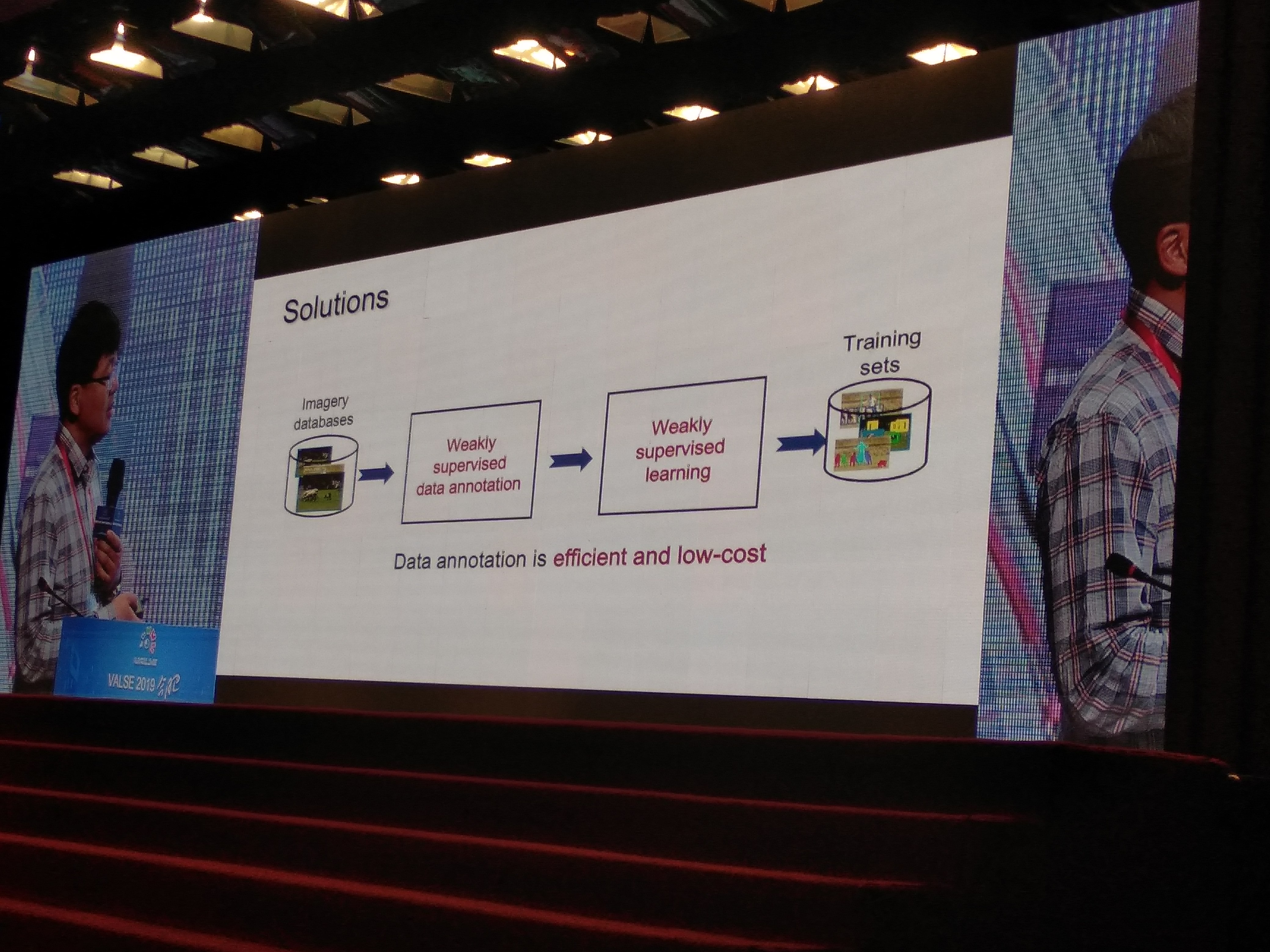
- 目前的object detection / segmentation存在的问题:需要为每一个任务制定详细而具体的标注,成本极大
- 一种解决思路:
- 粗粒度的弱监督标记:比如,只给目标物体上画一条线,只在目标物体上打一个点,仅仅告诉模型一系列图片中包含什么而不给位置,让模型自己学习找到这些目标。(瞬间想到我的VAD,CVPR2018-UCF,那个 video-level labeling)

-
papers:
-

-
整理如下:
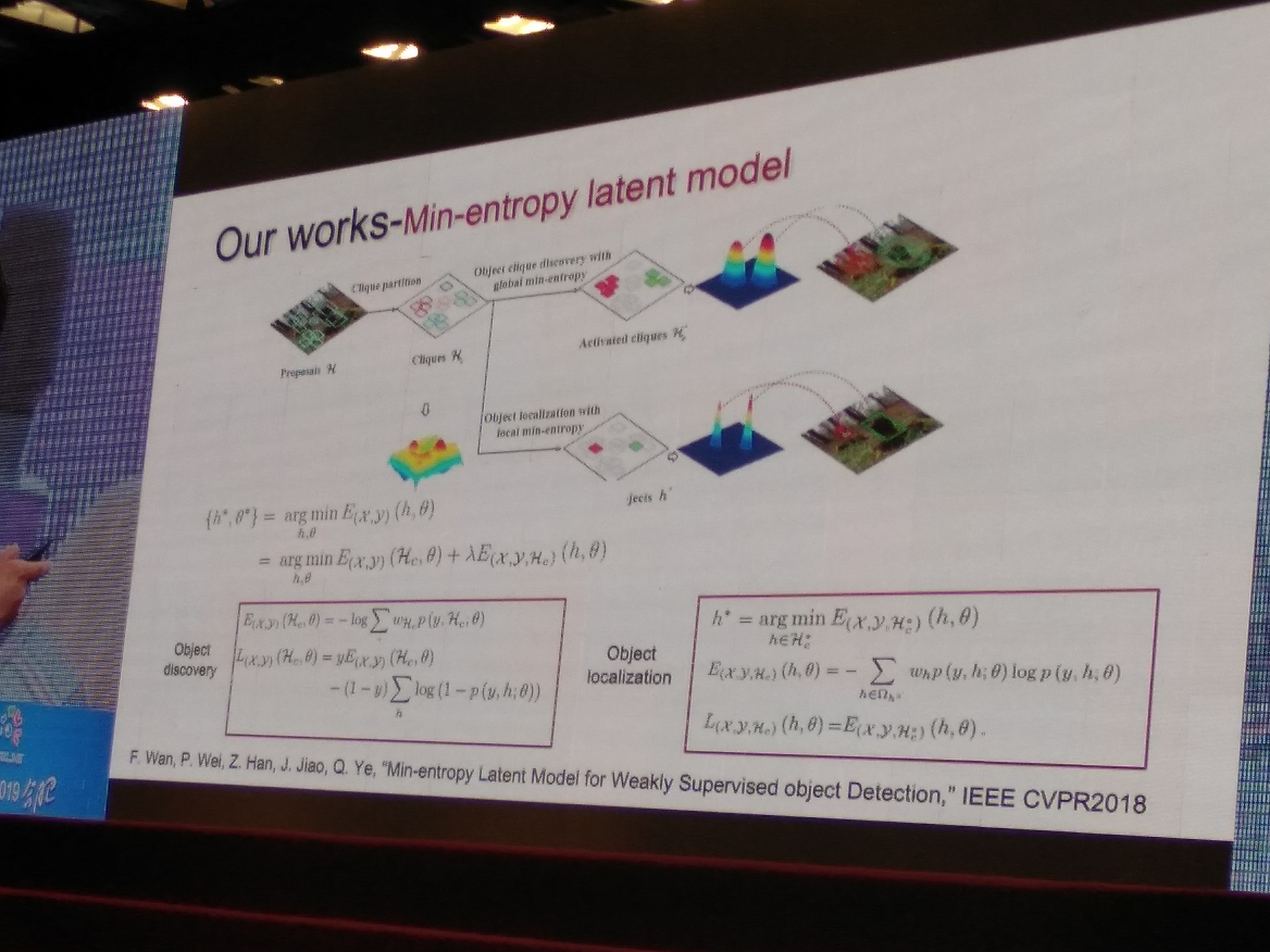
- Min-entropy Latent Model for Weakly Supervised object Detection, (CVPR2018)
- CMIL: Continuation Multiple Instance Learning for Weakly Supervised Detection (CVPR2019 Oral)
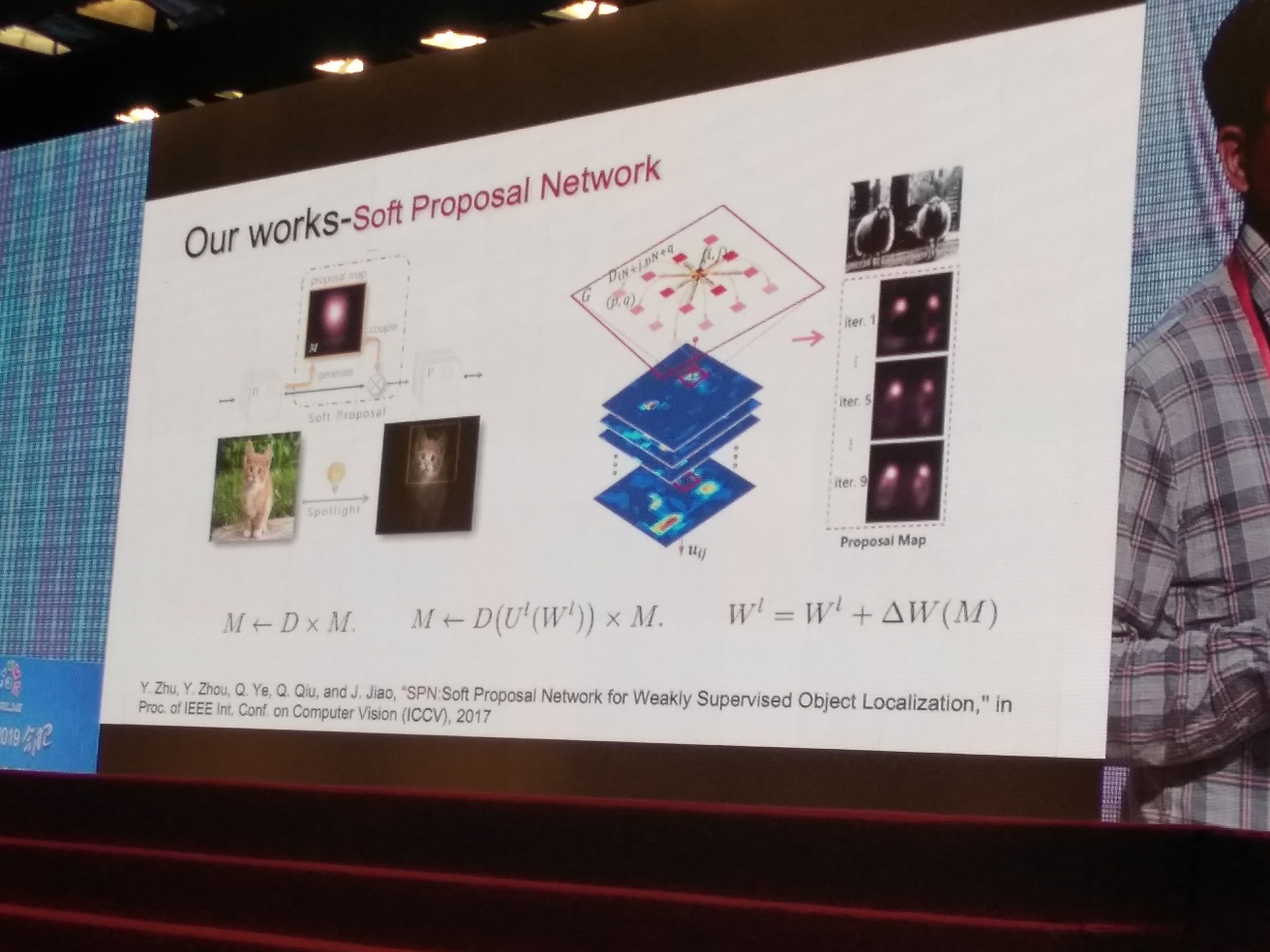
- SPN: Soft Proposal Network for Weakly Supervised Object Localization (ICCV2017)
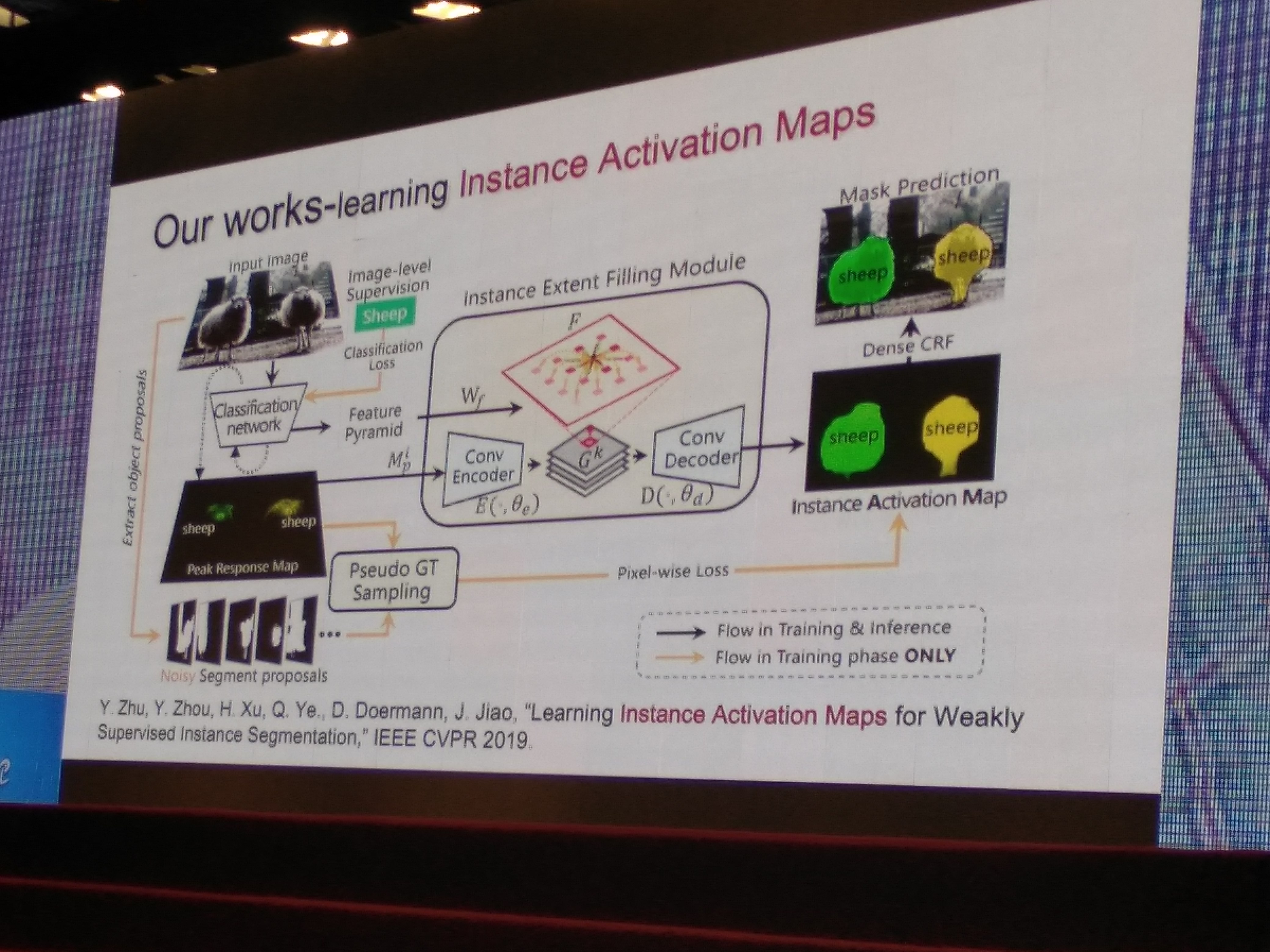
- Learning Instance Activation Maps for Weakly Supervised Instance Segmentation (CVPR2019)
- PAMI2019: Recurrent Learning(MELM+RecurrentLearning)
- PeakResponseMapping(PRM) (CVPR2018)
-
上述论文思路
-
隐变量学习、多实例学习,但是有个问题:一般无法找到全局最优解
-
对应的solution如下:
-
上面几篇论文都是对上面两种优化方式的具体解法,摘选如下:
-
-
-
未来发展方向:
- Beyond regularization and continuation optimization
- Beyond weakly supervised detection and segmentation
- Fill the gap of supervised and weakly supervised methods
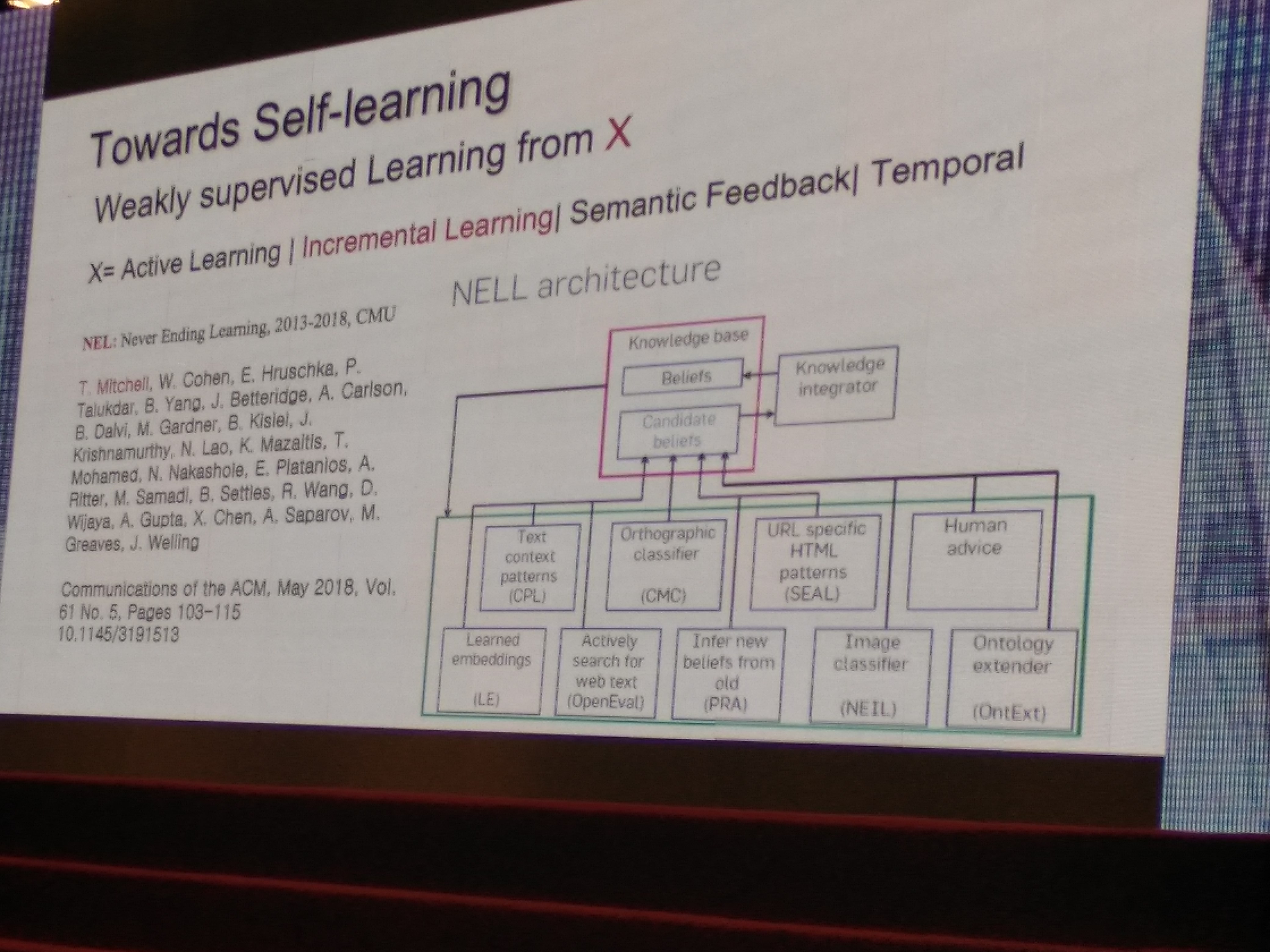
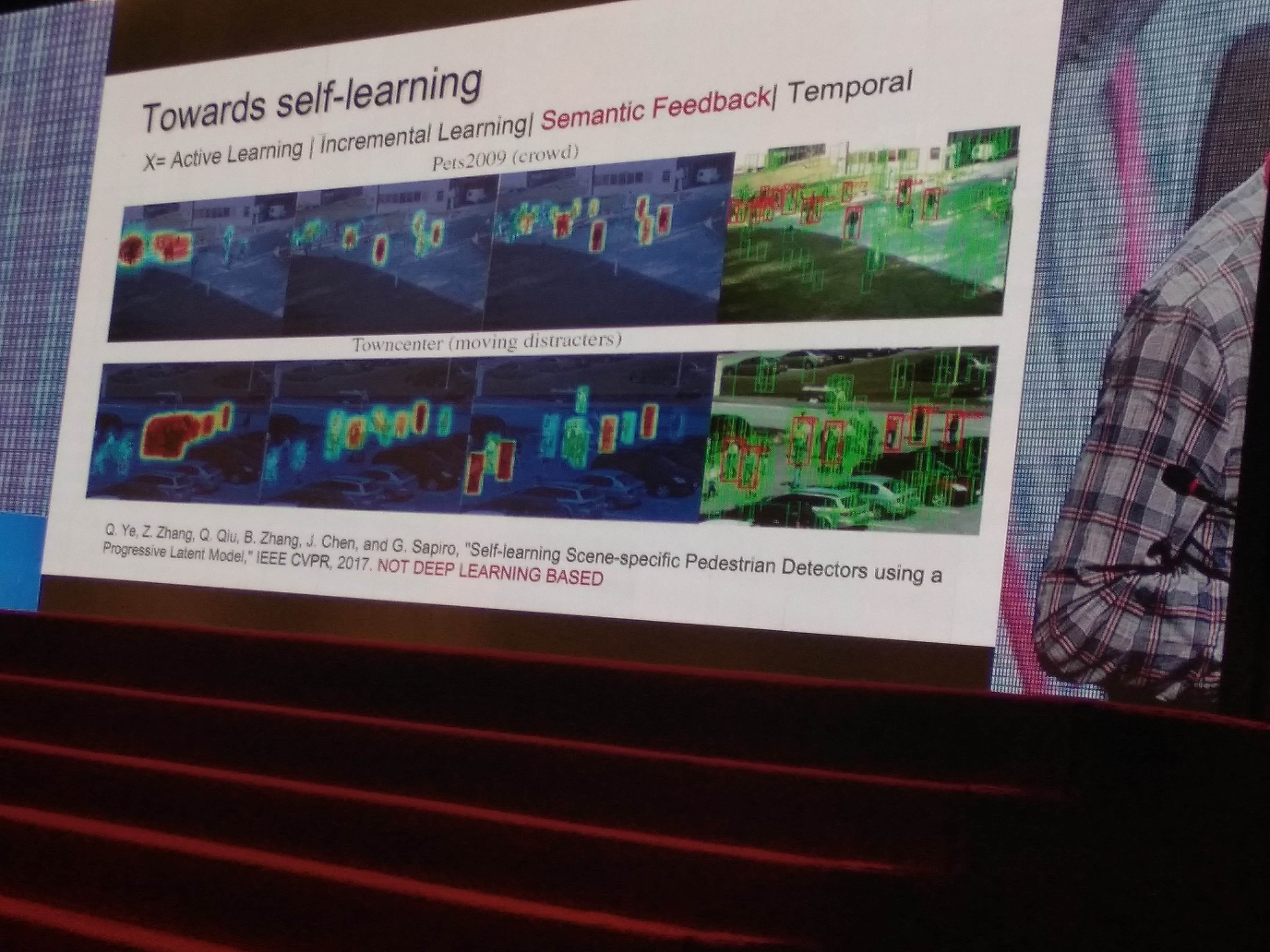
- Weakly supervised detection meets X (Self-learning Scene-specific Pedestrian Detectors using a Progressive Latent Model)
X= Few-shot Active Learning | Online Feedback | Temporal
-
-
Towrad Self-Learning
-






1.2.3 sheng jun huang (NHU)
-
Active Learning
-
传统的有监督学习

-
问题在哪里?
大量的数据标记成本巨大,有一些甚至是不可得的(比如医院的患者信息,异常检测的异常样本,几年才发生一次异常)
-
Active Learning

-
-
Cost Sensitive Active Learning
- goal: train an effective model with least labeling cost
- 细致定义 least 就是 Active Learning 的 核心
-
The cost is sensitive to (不是简单的 number of queries)
-
Instances | Features | Labels | Oracles
-
一个应用举例:用于视频推荐的多视角主动学习(multi-view active learning for video recommendation)
-
实例(instance):用于视频推荐的多视角主动学习
特征(feature):有监督矩阵补全的主动特征获取
标签(label):主动查询分层多标签学习代理(oracles):积极学习各种不完美的oracles
-

-
-
详细分析:
-
instances ——multi-view active learning for video recommendation
视频推荐:协同过滤(冷门启动问题)| 基于内容的过滤(需要大量数据训练)
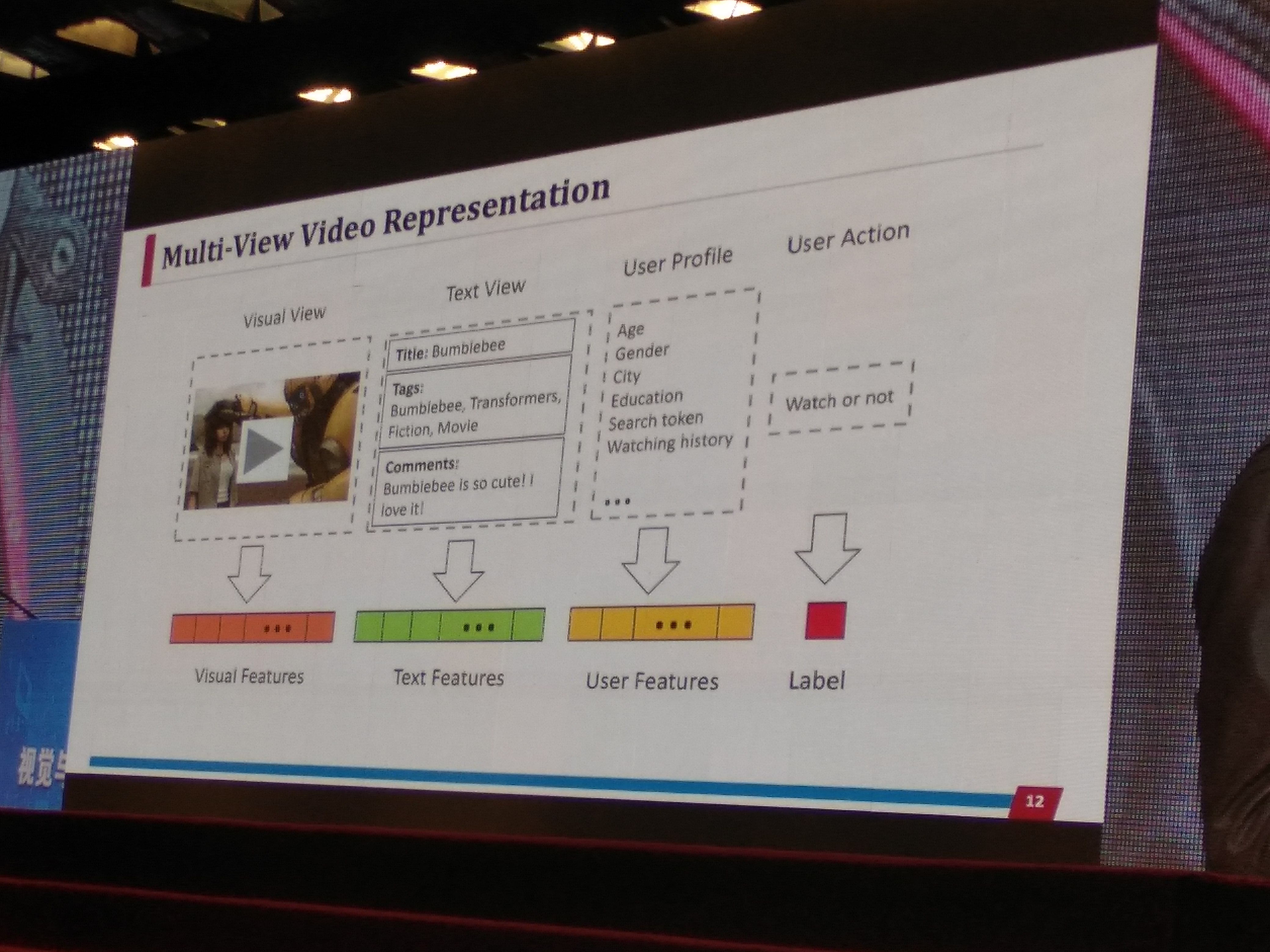
多视角视频表示:视觉特征、文本特征、用户特征、标签
motivation:在视频推荐任务中,文本特征(即评论)获取需要很大代价,视觉特征不需要人力代价。
idea: Visual to text Mapping
-
如下图所示,


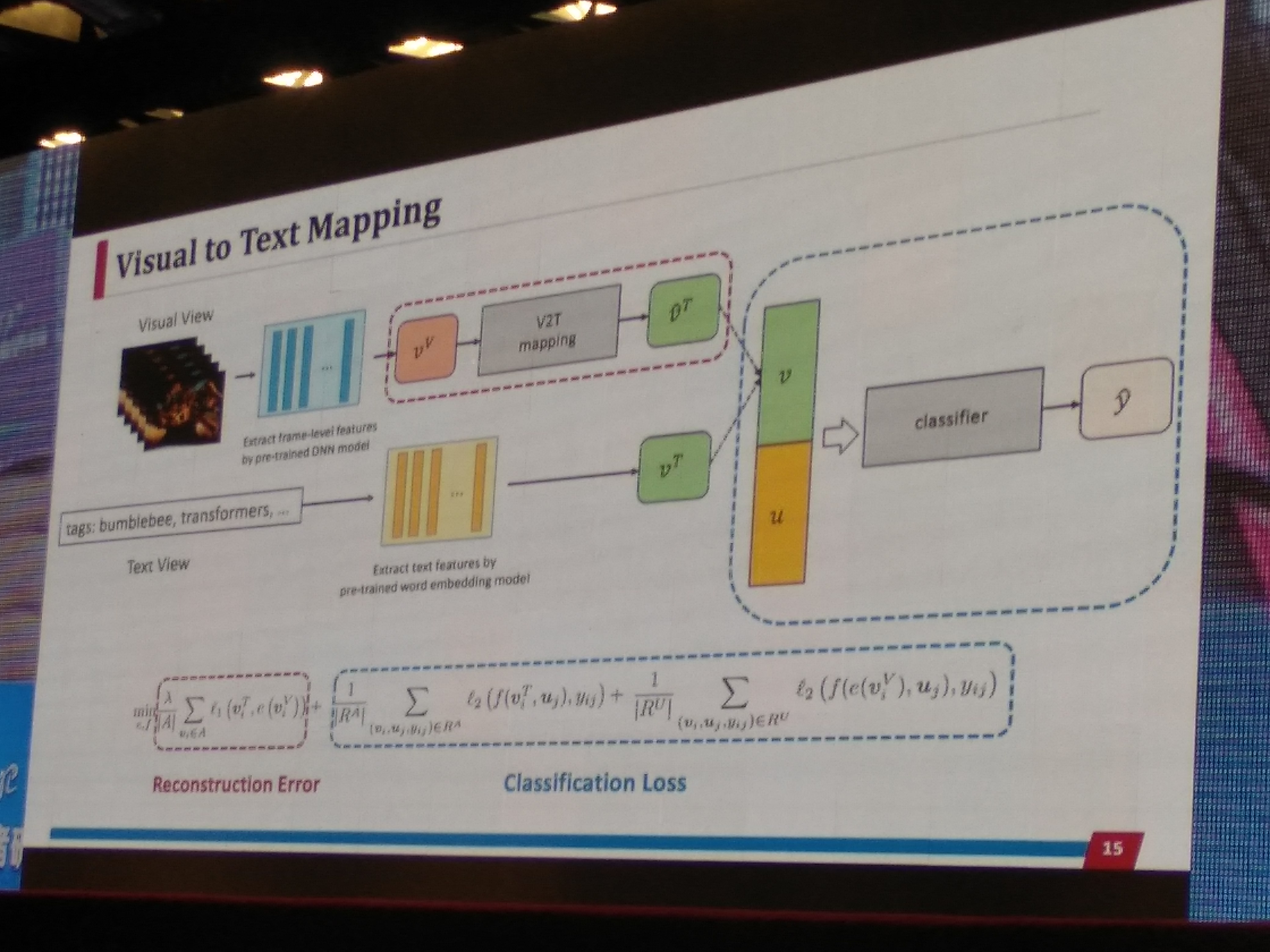
-
-
features——active feature acquisition with supervised matrix completion
问题:现实应用中往往会出现特征丢失现象,通常导致学习性能下降
motivation: SMC——supervised matrix completion(exploit the label information / Trace norm for low-rank assumption)
-
如下图,






-
-
labels——active querying for hierarchical multi-label learning
标签有层次结构
平衡成本和信息
-
如下图,
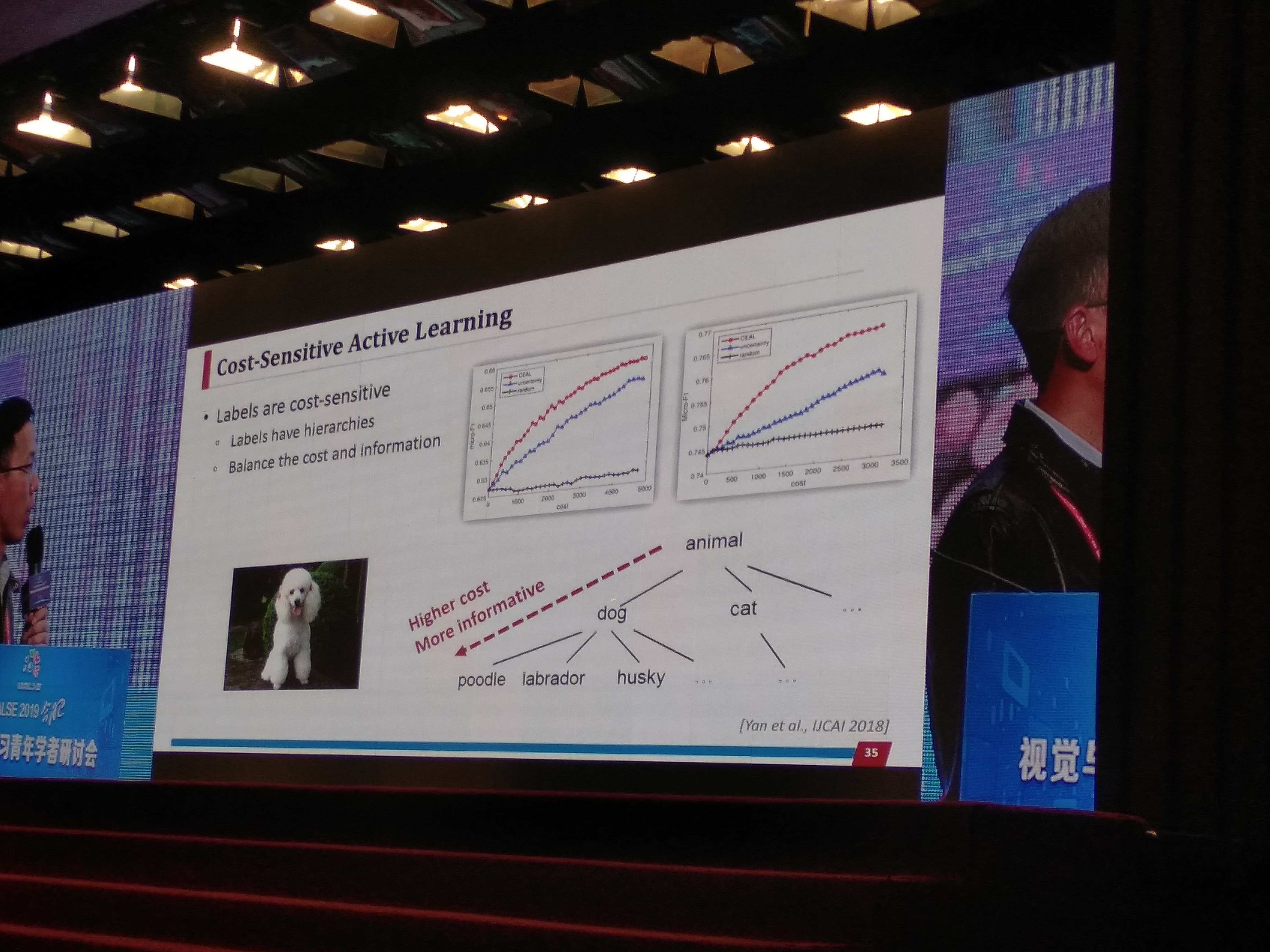
-
-
Oracles——active learning from diverse and imperfect oracles
不同的oracles有不同的价格
同时选择instance和oracle
准确而便宜的标签
-
如下图,
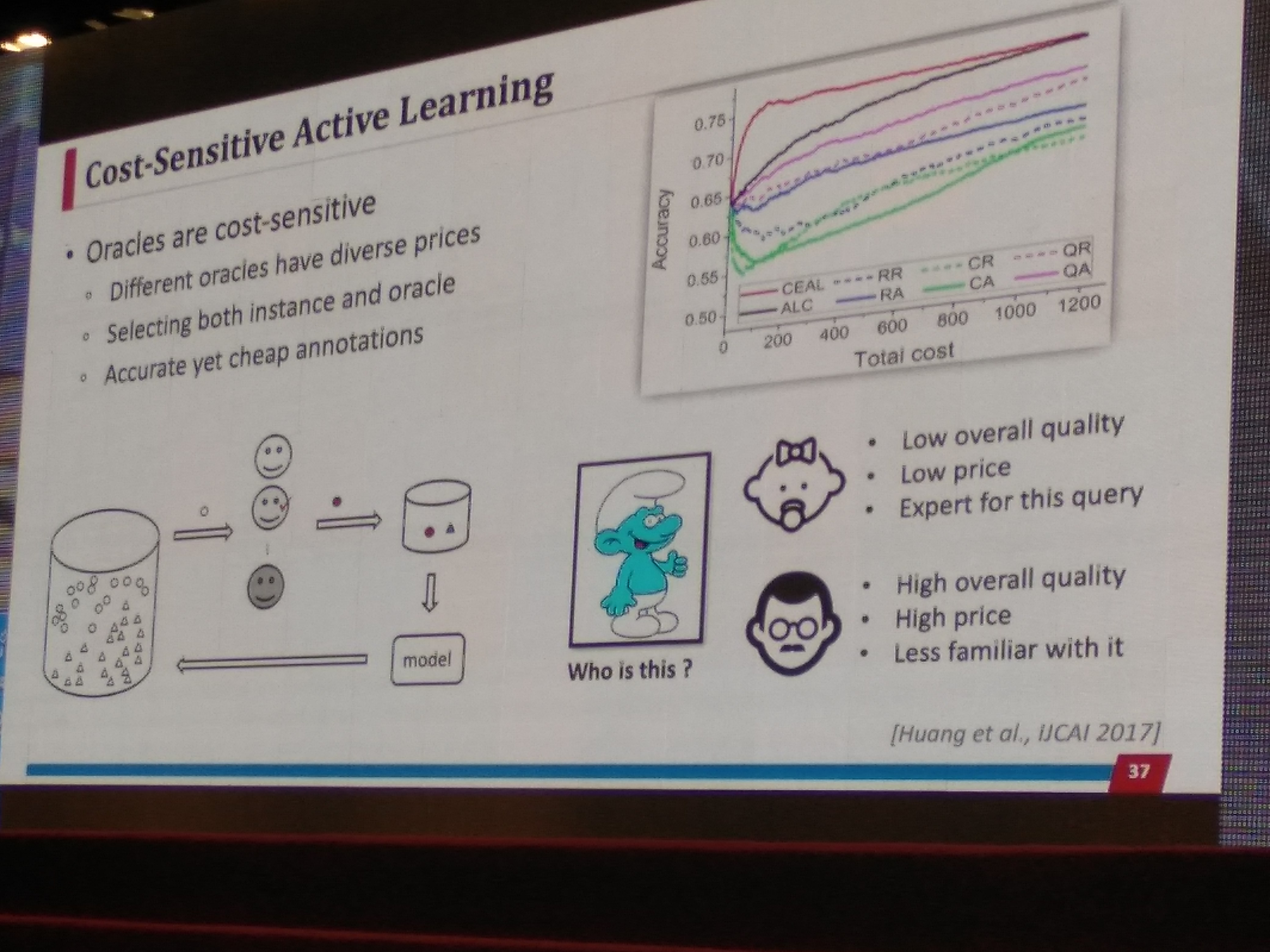
-
-
-
-
Summary:
-
Active Learning: train an effective model with least labeling cost
-
The cost may be sensitive to different instances/features/labels/oracles
-
Key issues in active learning
-
Selection Criterion
- which instance to select ?
-
Query Type
- what information to query ?
-
Imperfect Oracles
- noisy or unavailable oracles
-
Huge Unlabeled Data
- fast selection and training
-
如下图,

-
-
我之前关注过的关于 Active Learning的 zhihu link: link-1 link-2, link-3
-
1.2. 4 yunchao wei (UIUC)
-
引子:
-
Towards Weakly Supervised Object Segmentation & Scene Parsing
-
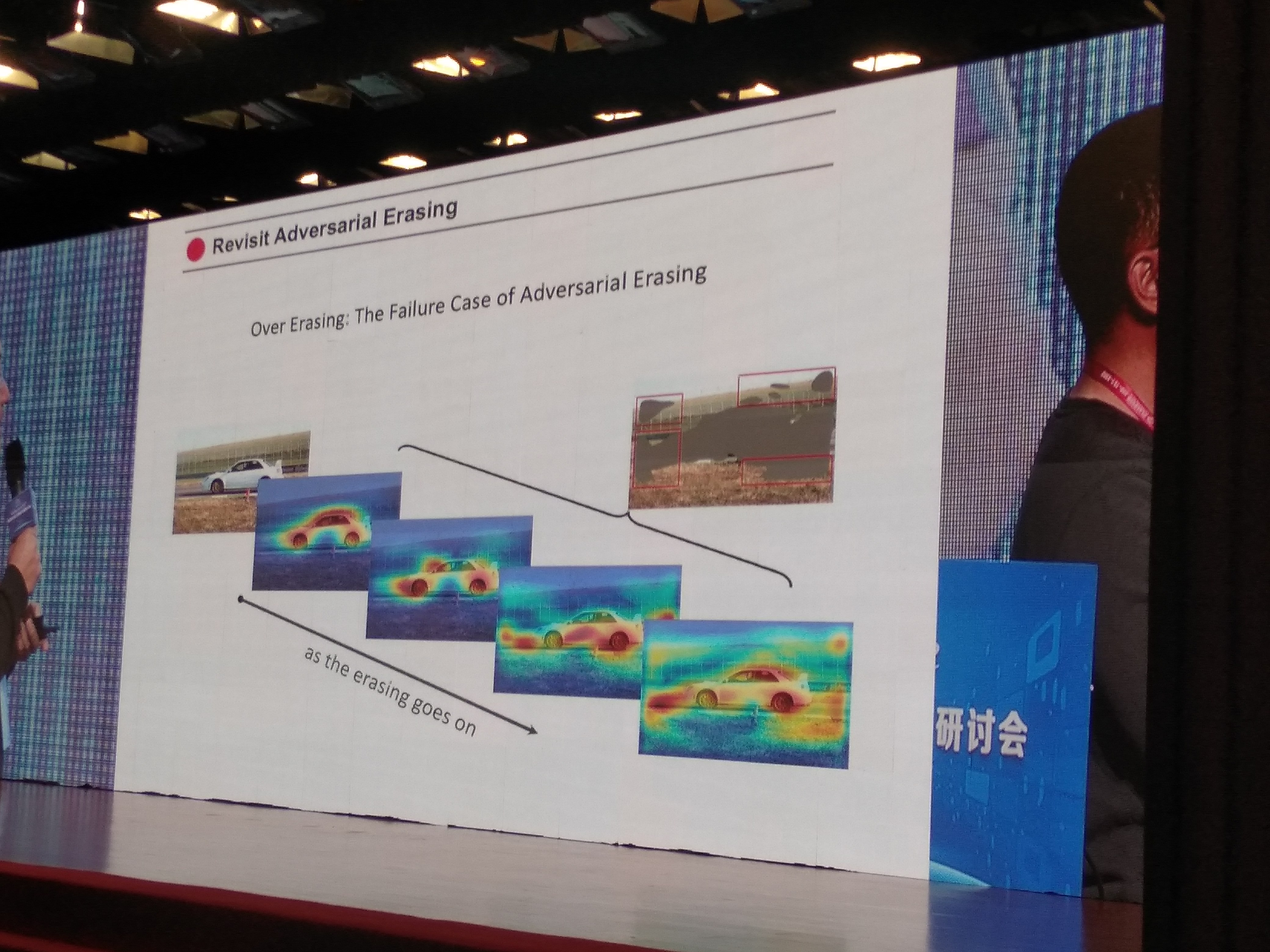
Revisit Adversarial Erasing
-
Object Region Mining with Adversarial Erasing (CVPR2017)
-
Adversarial Complementary Learning (Zhang CVPR2018)
-
Issue:Over Erasing: The Failure Case of Adversarial Erasing
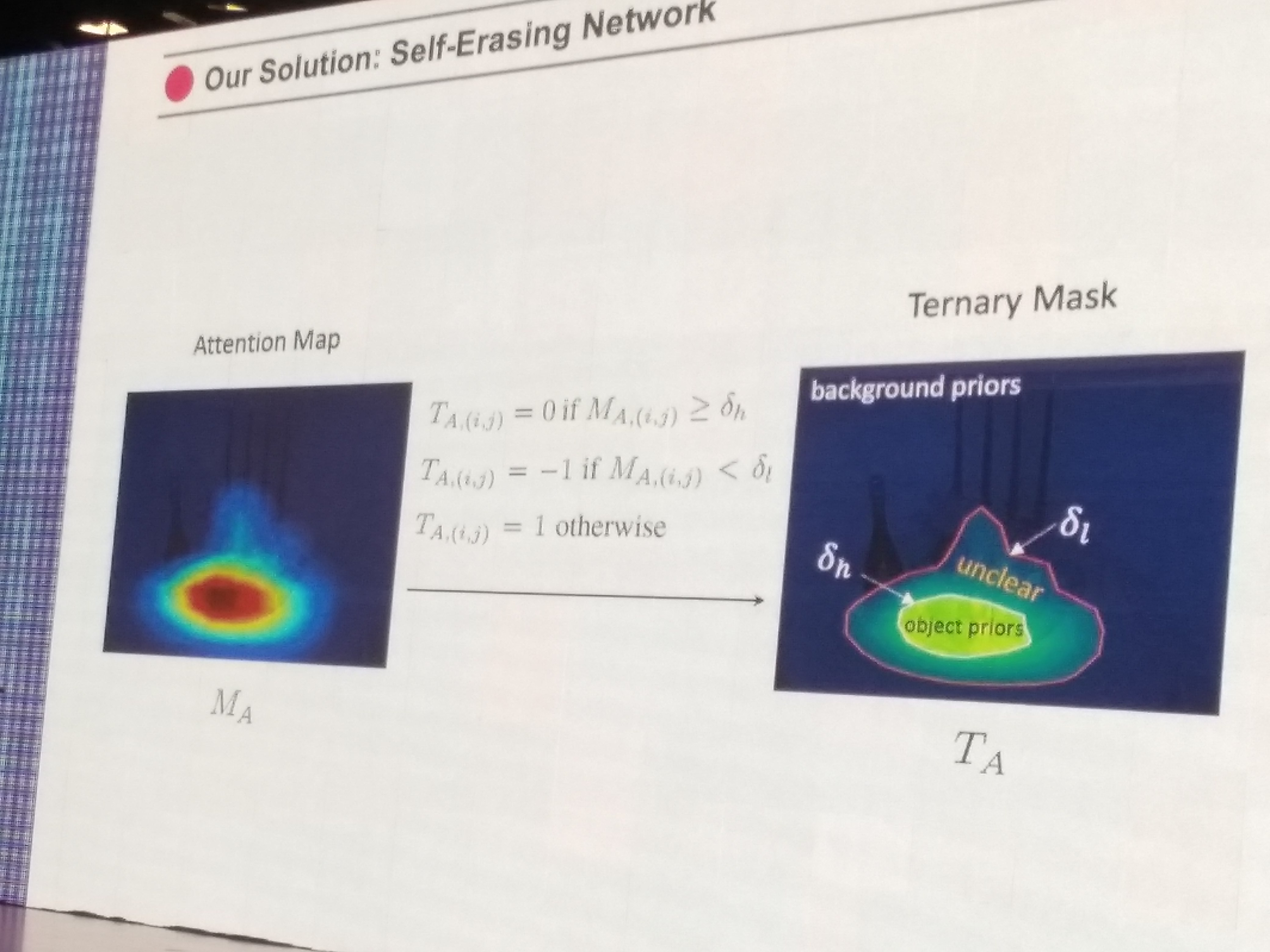
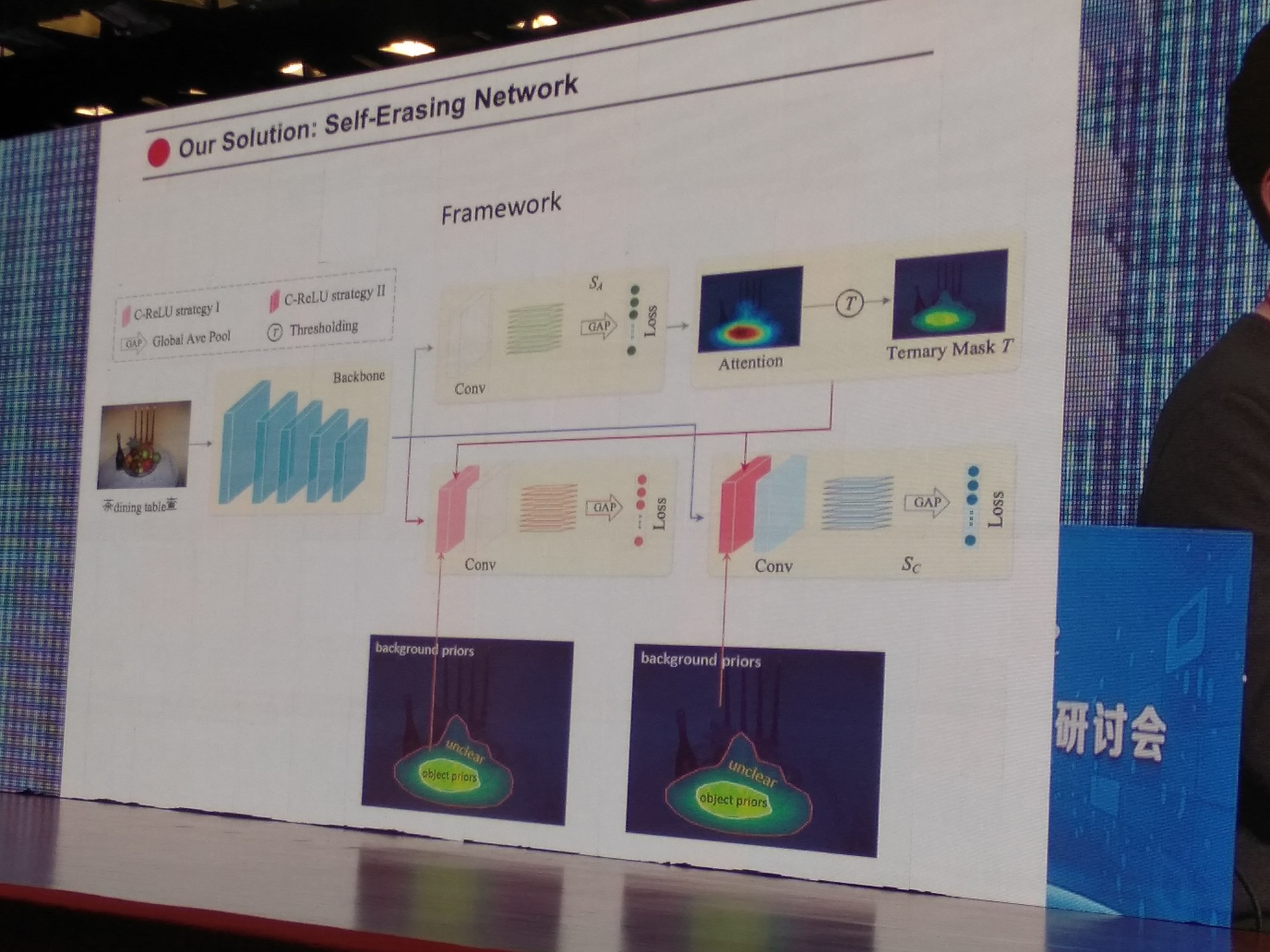
- yc, w的solution: Self-Erasing Network
-
如下图,

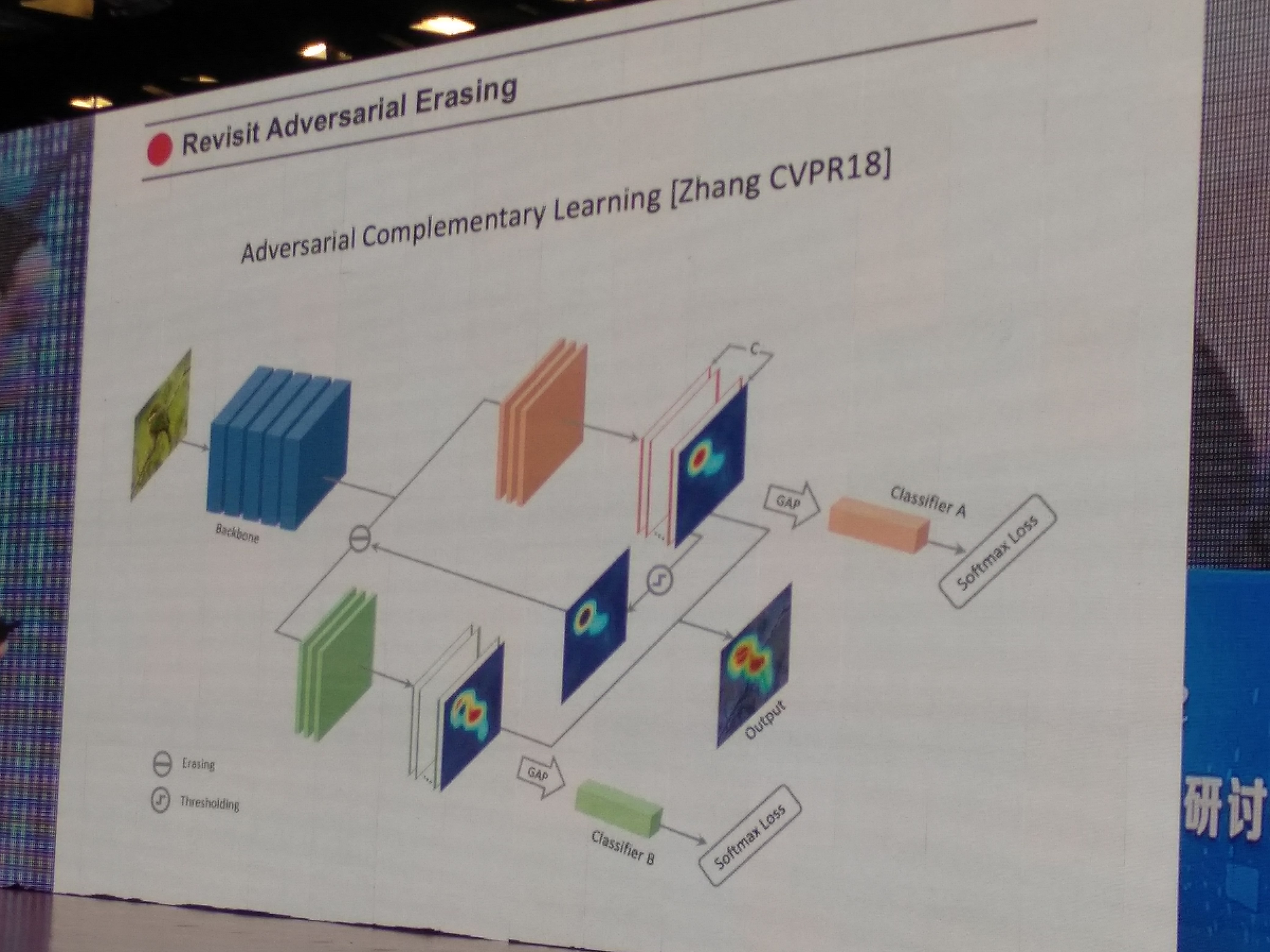
-
-
-
一篇论文:
-
Weakly Supervised Scene Parsing with Point-based Distance Metric Learning (yunchao wei, CVPR)
-
Weakly supervised methods for scene parsing
-
image-level labeling -> Box-level -> scribble-level -> point-level
如图,

-
wekaly的体现: point-based labeling than pixel-based labeling
-
motivation: How to utillze limited annotation? 答:Cross-Image semantic similarity
如图,

-
-
论文方法overview
-
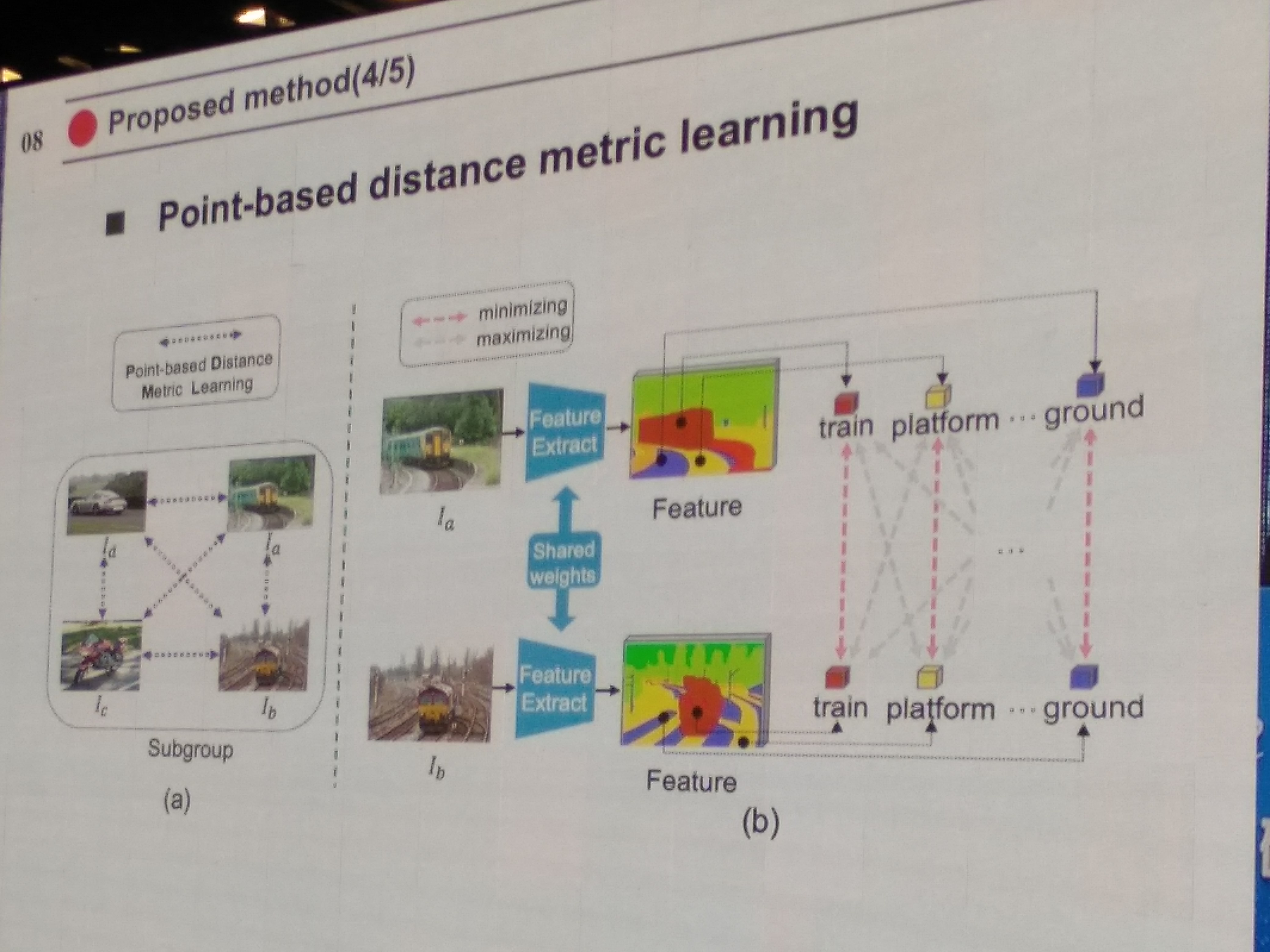
Point-based distance metric learning (PDML)
-
point supervision (PointSup)
-
Online extension supervision(ExtendSup)
-
如图,



-
-
Conclusion

-
1.3 弱监督学习的启发
-
叶齐祥的弱标记:
只给目标物体上画一条线,只在目标物体上打一个点,仅仅告诉模型一系列图片中包含什么而不给位置,让模型自己学习找到这些目标。
-
魏云超的擦除思想:
作者尝试直接使用预训练模型,找原图【使得预训练模型最后一个卷积层激活较大】的区域,然后发现在Image-Net上预训练模型虽然有很好的分类能力,但最后的激活层往往来自于原图中最有判别能力的部分而不是全部物体。举例:虽然预训练模型能将狗分类成狗,但是使得最后输出“狗”这个维度的激活最大的可能仅是狗头、狗腿这些比较discriminative的区域,而不是整个狗的instance segmentation,于是作者提出,将原图中最disciminative的区域擦掉(erase),然后再训练模型,如此反复,直到模型最后的激活来源于整个狗。
-
一些idea:
-
卷积激励的显著分布估计,与前文所说的pre-trained model一样,对原图使得最后激活大的区域进行分析
-
通过对抗生成网络生成边界周围的样本来得到更细粒度的分类边界
-
为了衡量图像和文本的相似度,将图像编码到文本的特征空间中,或者将文本编码到图像的特征空间中,以此衡量,而不是将二者编码到第三个特征空间中衡量
-
设计好的loss是发表论文的好方法
-
-
待看blog: