Python百度文库爬虫之ppt文件
对于文件的所有类型,我都会用一篇文章进行说明,链接:
- Python百度文库爬虫之txt文件
- Python百度文库爬虫之doc文件
- Python百度文库爬虫之pdf文件
- Python百度文库爬虫之ppt文件
- [Python百度文库爬虫之xls文件
- Python百度文件爬虫终极版
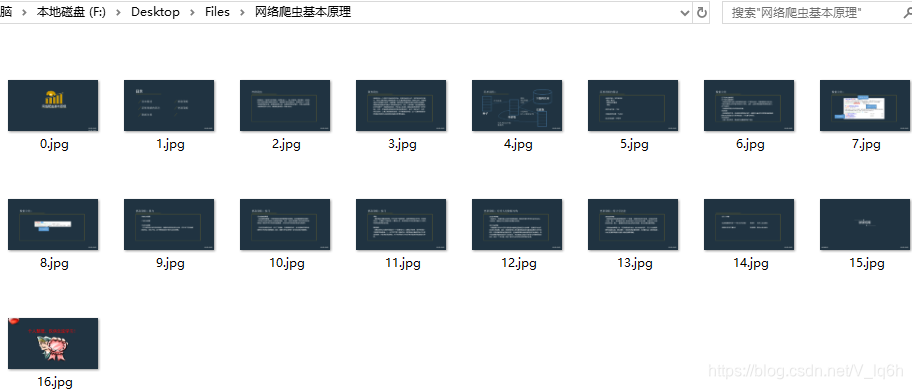
一.网页分析
PTT文件的内容实际是图片,我们只需要把图片下载并保存
from IPython.display import Image
Image("./Images/ppt_0.png",width="600px",height="400px")
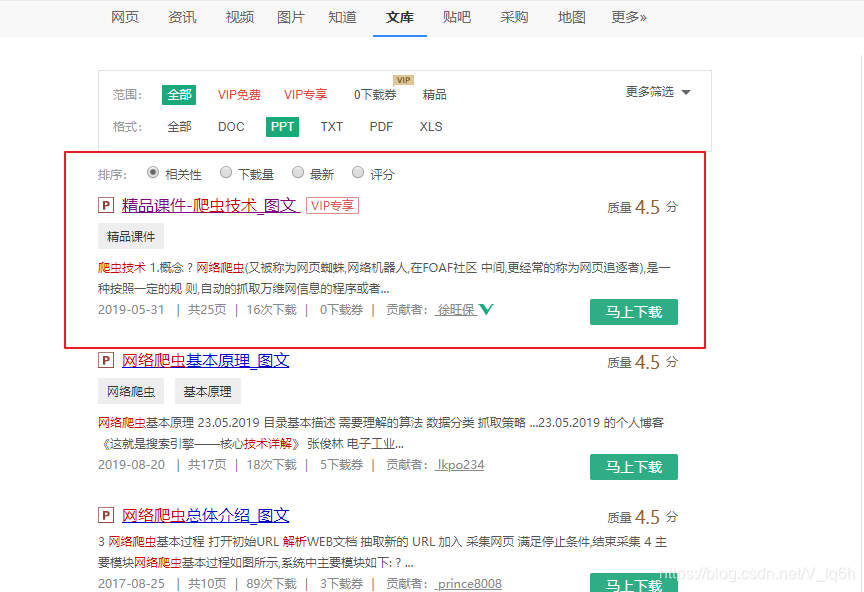
二.数据链接
Image("./Images/ppt_1.png",width="600px",height="400px")
查看链接,与我们数据一样:
Image("./Images/ppt_3.png",width="600px",height="400px")
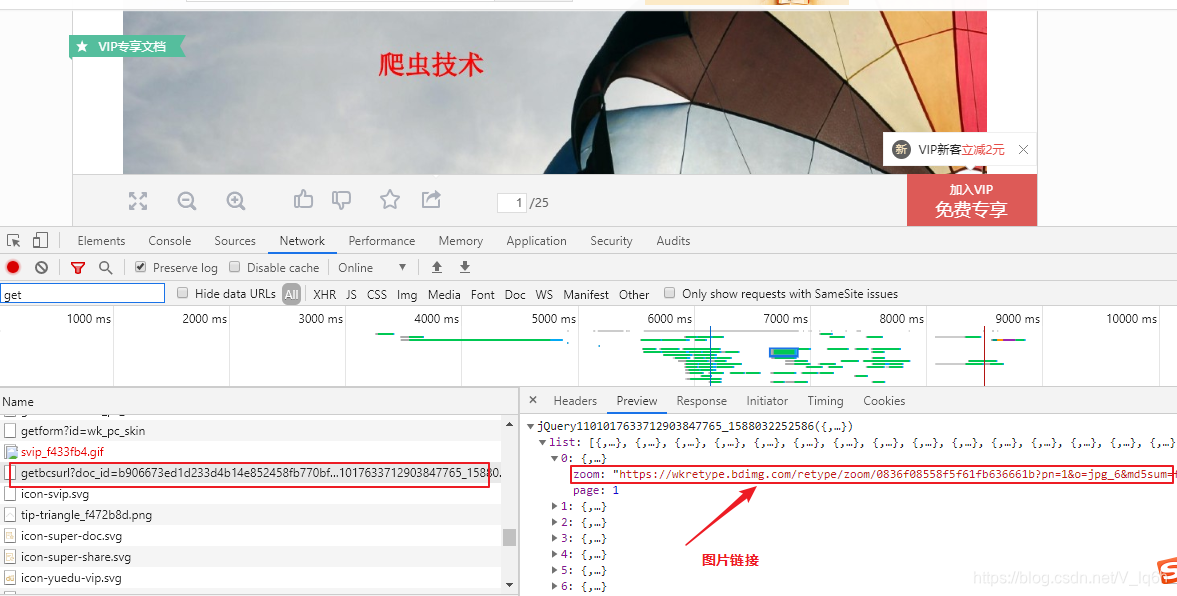
三.程序调试
import requests
import json
import re
import json
session=requests.session()
url=input("请输入下载的文件URL地址:")
content=session.get(url).content.decode('gbk')
doc_id=re.findall('view/(.*?).html',url)[0]
types=re.findall(r"docType.*?:.*?'(.*?)'",content)[0]
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
请输入下载的文件URL地址: https://wenku.baidu.com/view/b906673ed1d233d4b14e852458fb770bf68a3b18.html?fr=search
doc_id
'b906673ed1d233d4b14e852458fb770bf68a3b18'
types
'ppt'
title
'精品课件-爬虫技术'
content_url='https://wenku.baidu.com/browse/getbcsurl?doc_id='+doc_id+'&pn=1&rn=9999&type=ppt'
content=session.get(content_url).content.decode('gbk')
url_list=re.findall('{"zoom":"(.*?)","page"',content)
url_list=[addr.replace('\','') for addr in url_list]
url_list
['https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=1&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=0-487135&jpg=0-133194',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=2&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=487136-641849&jpg=133195-323627',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=3&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=641850-727977&jpg=323628-515968',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=4&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=727978-856818&jpg=515969-615553',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=5&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=856819-942946&jpg=615554-777861',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=6&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=942947-1029074&jpg=777862-946638',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=7&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1029075-1125666&jpg=946639-1030299',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=8&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1125667-1245334&jpg=1030300-1167061',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=9&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1245335-1331462&jpg=1167062-1272951',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=10&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1331463-1417590&jpg=1272952-1420059',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=11&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1417591-1503718&jpg=1420060-1609566',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=12&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1503719-1589846&jpg=1609567-1829614',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=13&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1589847-1675974&jpg=1829615-1961046',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=14&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1675975-1762102&jpg=1961047-2057806',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=15&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1762103-1848230&jpg=2057807-2244791',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=16&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1848231-1934358&jpg=2244792-2465213',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=17&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=1934359-2020486&jpg=2465214-2668167',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=18&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2020487-2106614&jpg=2668168-2791205',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=19&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2106615-2192742&jpg=2791206-2932355',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=20&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2192743-2278870&jpg=2932356-3128420',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=21&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2278871-2364998&jpg=3128421-3316449',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=22&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2364999-2451126&jpg=3316450-3622711',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=23&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2451127-2537254&jpg=3622712-3795370',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=24&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2537255-2623382&jpg=3795371-4062675',
'https://wkretype.bdimg.com/retype/zoom/0836f08558f5f61fb636661b?pn=25&o=jpg_6&md5sum=f2be3d1fed17d9e67fa325fbdfbafa6c&sign=c05e1cdb4f&png=2623383-&jpg=4062676-']
import os
path="F:\桌面\Files"+"\"+title
if not os.path.exists(path):
os.mkdir(path)
for index,url in enumerate(url_list):
content=session.get(url).content
paths=os.path.join(path,str(index)+'.jpg')
with open(paths,'wb') as f:
f.write(content)
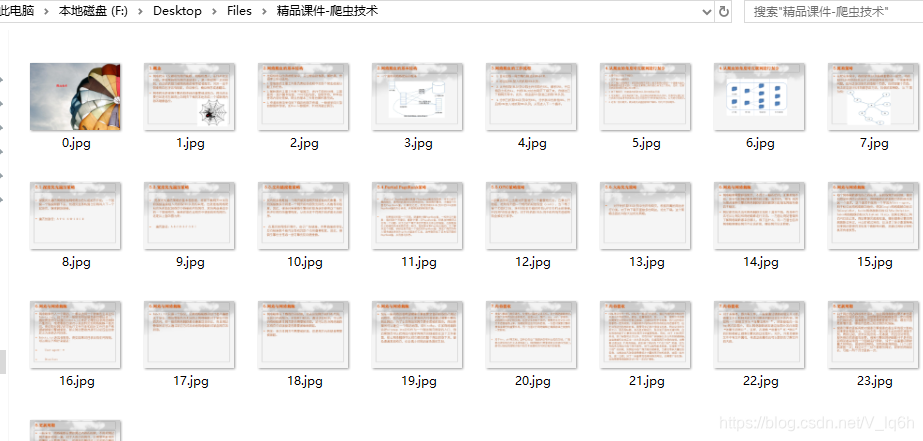
print("图片保存在"+title+"文件夹")
图片保存在精品课件-爬虫技术文件夹
Image("./Images/ppt_4.png",width="600px",height="400px")
三.函数编程
import requests
import json
import re
import os
session=requests.session()
path="F:\桌面\Files"
if not os.path.exists(path):
os.mkdir(path)
def parse_txt1(code,doc_id):
content_url='https://wenku.baidu.com/api/doc/getdocinfo?callback=cb&doc_id='+doc_id
content=session.get(content_url).content.decode(code)
md5sum=re.findall('"md5sum":"(.*?)",',content)[0]
rsign=re.findall('"rsign":"(.*?)"',content)[0]
pn=re.findall('"totalPageNum":"(.*?)"',content)[0]
content_url='https://wkretype.bdimg.com/retype/text/'+doc_id+'?rn='+pn+'&type=txt'+md5sum+'&rsign='+rsign
content=json.loads(session.get(content_url).content.decode('gbk'))
result=''
for item in content:
for i in item['parags']:
result+=i['c']
return result
def parse_txt2(content,code,doc_id):
md5sum=re.findall('"md5sum":"(.*?)",',content)[0]
rsign=re.findall('"rsign":"(.*?)"',content)[0]
pn=re.findall('"show_page":"(.*?)"',content)[0]
content_url='https://wkretype.bdimg.com/retype/text/'+doc_id+'?rn='+pn+'&type=txt'+md5sum+'&rsign='+rsign
content=json.loads(session.get(content_url).content.decode('utf-8'))
result=''
for item in content:
for i in item['parags']:
result+=i['c']
return result
def parse_doc(content):
url_list=re.findall(r'(https.*?0.json.*?)\x22}',content)
url_list=[addr.replace("\\\/","/") for addr in url_list]
result=""
for url in set(url_list):
content=session.get(url).content.decode('gbk')
y=0
txtlists=re.findall(r'"c":"(.*?)".*?"y":(.*?),',content)
for item in txtlists:
# 当item[1]的值与前面不同时,代表要换行了
if not y==item[1]:
y=item[1]
n='
'
else:
n=''
result+=n
result+=item[0].encode('utf-8').decode('unicode_escape','ignore')
return result
def parse_pdf(content):
url_list=re.findall(r'(https.*?0.json.*?)\x22}',content)
url_list=[addr.replace("\\\/","/") for addr in url_list]
result=""
for url in set(url_list):
content=session.get(url).content.decode('gbk')
y=0
txtlists=re.findall(r'"c":"(.*?)".*?"y":(.*?),',content)
for item in txtlists:
# 当item[1]的值与前面不同时,代表要换行了
if not y==item[1]:
y=item[1]
n='
'
else:
n=''
result+=n
result+=item[0].encode('utf-8').decode('unicode_escape','ignore')
return result
def parse_ppt(doc_id,title):
content_url='https://wenku.baidu.com/browse/getbcsurl?doc_id='+doc_id+'&pn=1&rn=9999&type=ppt'
content=session.get(content_url).content.decode('gbk')
url_list=re.findall('{"zoom":"(.*?)","page"',content)
url_list=[addr.replace('\','') for addr in url_list]
path="F:\桌面\Files"+"\"+title
if not os.path.exists(path):
os.mkdir(path)
for index,url in enumerate(url_list):
content=session.get(url).content
paths=os.path.join(path,str(index)+'.jpg')
with open(paths,'wb') as f:
f.write(content)
print("图片保存在"+title+"文件夹")
def save_file(title,filename,content):
with open(filename,'w',encoding='utf-8') as f:
f.write(content)
print("文件"+title+"保存成功")
f.close()
def main():
print("欢迎来到百度文库文件下载:")
print("-----------------------
")
while True:
try:
print("1.doc
2.txt
3.ppt
4.xls
5.ppt
")
types=input("请输入需要下载文件的格式(0退出):")
if types=="0":
break
if types not in ['txt','doc','pdf','ppt']:
print("抱歉功能尚未开发")
continue
url=input("请输入下载的文库URL地址:")
# 网页内容
response=session.get(url)
code=re.findall('charset=(.*?)"',response.text)[0]
if code.lower()!='utf-8':
code='gbk'
content=response.content.decode(code)
# 文件id
doc_id=re.findall('view/(.*?).html',url)[0]
# 文件类型
#types=re.findall(r"docType.*?:.*?'(.*?)'",content)[0]
# 文件主题
#title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
if types=='txt':
md5sum=re.findall('"md5sum":"(.*?)",',content)
if md5sum!=[]:
result=parse_txt2(content,code,doc_id)
title=re.findall(r'<title>(.*?). ',content)[0]
#filename=os.getcwd()+"\Files\"+title+'.txt'
filename=path+"\"+title+".txt"
save_file(title,filename,result)
else:
result=parse_txt1(code,doc_id)
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
#filename=os.getcwd()+"\Files\"+title+'.txt'
filename=path+"\"+title+".txt"
save_file(title,filename,result)
elif types=='doc':
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
result=parse_doc(content)
filename=path+"\"+title+".doc"
save_file(title,filename,result)
elif types=='pdf':
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
result=parse_pdf(content)
filename=path+"\"+title+".txt"
save_file(title,filename,result)
elif types=='ppt':
title=re.findall(r"title.*?:.*?'(.*?)'",content)[0]
parse_ppt(doc_id,title)
except Exception as e:
print(e)
if __name__=='__main__':
main()
欢迎来到百度文库文件下载:
-----------------------
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出): ppt
请输入下载的文库URL地址: https://wenku.baidu.com/view/b906673ed1d233d4b14e852458fb770bf68a3b18.html?fr=search
图片保存在精品课件-爬虫技术文件夹
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出): ppt
请输入下载的文库URL地址: https://wenku.baidu.com/view/26f8556af021dd36a32d7375a417866fb94ac0e3.html?fr=search
图片保存在网络爬虫基本原理文件夹
1.doc
2.txt
3.ppt
4.xls
5.ppt
请输入需要下载文件的格式(0退出): 0
Image("./Images/ppt_5.png",width="600px",height="400px")

Image("./Images/ppt_6.png",width="600px",height="400px")