数据库:Database
Mysql:
sql语言:
结构数据定义语言(DDL)(Data Definition Language): CREATE ALTER DROP
数据操纵语言(DML)(data manipulation language): INSERT SELECT UPDATE DELETE
事务控制语言(TCL): COMMIT ROLLBACK
数据控制语言(DCL): GRANT REVOKE
化查询语言)DBA(数据库管理员)
mysql命令
1.展示所有的数据库
show databases
2.新建数据库
create database 数据库名称(字母开头)
3.使用数据库
use 数据库名称
4.查看数据库中可用的表(可用文件)
show tables
5.给数据库中添加文件
source 资源路径
6.mysql中常用的数据类型
字符型 char
字符串 varchar(255) (相当于java的String类型)
整型 int(11)
浮点型 float,double
布尔 boolean
7.查看表结构
desc 表名
dept表 部门表
deptno 部门编号 int类型
dname 部门名称 varchar类型
loc 部门所在城市 varchar类型
emp表 员工表
empno 员工编号 int
ename 员工姓名 varchar
job 工作 varchar
mgr 经理编号 int
hiredate 入职时间 date
sal 工资 int
comm 奖金 int
deptno 员工所在部门编号 int
salgrade 薪水等级表
grade 工资等级 int
losal 最低工资 int
hisal 最高工资 int
每个关系型数据库都有一张虚拟表(虚表)dual
select 2*3 from dual;
select 2*3 from emp;会出现冗余数据
null值:
空值是一个表达不可用、未分配、未知、或者不适用等意义的值。空值与零和空格的概念不同,应当严格区分。
数据操纵语言:DML(操作的的表中的数据)
select:查询 并显示到表中
*对select的字段做加减乘除操作
1.查询部门中的所有信息
select * from dept;
2.查询部门编号和部门名称
select deptno,dname from dept;
3.计算每个员工的年薪
select ename,sal*12 from emp;
月薪加100乘以12
select (sal+100)*12 from emp;
4查看当前系统时间
select now() from dual;
5.字段起别名 as 可以省略不写
select sal as '月薪' from emp;
select sal '月薪' from emp;
6.去除冗余字段 distinct
select distinct 2*3 from emp;
筛选:where
7.查找员工表中工作为办事员的员工信息
select * from emp where job='CLERK';
8.查找员工表中入职时间大于1981-01-01年的员工信息
select * from emp where hiredate>'1981-01-01';
9.查询员工表工资在1500-3000的员工信息
select * from emp where sal between 1500 and 3000;
10.查询员工表工资在1100,1500,2000的员工信息
select * from emp where sal in(1100,1500,2000);
11.like 像 % 表示0到多个字符 _表示一个字符
查询员工姓名以A开头的员工信息
select * from emp where ename like 'A%';
12.查询员工姓名第二个字符为A的员工信息
select * from emp where ename like '_A%';
13.查询员工姓名包含A的员工信息
select * from emp where ename like '%A%';
14.查询奖金为null的员工信息
select * from emp where comm is null;
15.查询奖金不为null的员工信息
select * from emp where comm is not null;
16.and表示两个条件必须成立
查询工作为办事员并且工资大于1000
select * from emp where job='CLERK' and sal>1000;
17.查询工作为办事员或者工作为经理的员工信息
select * from emp where job='CLERK' or job='MANAGER';
18.查询工资不在3000,2500之内的员工信息
select * from emp where sal not in(3000,2500);
19.and 和 or优先级 and的优先级高
查询工作为销售,工作为董事长并且工资大于1500
select * from emp where job='SALESMAN' or job='PRESIDENT' and sal>1500;
查询工作为销售或者董事长的员工信息,并且工资大于1500
select * from emp where (job='SALESMAN' or job='PRESIDENT') and sal>1500;
update:修改
delete:删除
insert:添加
数据排序 (asc-升序 desc-降序)
单一字段排序 order by 字段名称,作用:通过哪个字段或哪些字段进行排序
含义:排序通过order by 子句,order by 后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔,order by 默认采用升序asc ,如果存在where子句,那么order by 必须放在where语句后面。
排序:
order by(默认的排序方式为升序 asc 降序的 desc)
order by 在查询语句的最后(在where条件之后)
1.按照员工姓名排序
select * from emp order by ename;
2.按照工资降序、如果工资相同时按照姓名降序
select * from emp order by sal desc,ename desc;
3.查找所有10部门的经理和20部门的办事员
select * from emp where deptno = 10 and job = 'MANAHER'
union
select * from emp where deptno = 20 and job = 'CLERK';
4.聚合函数(max,min,count,avg,sum)
获取员工表中的最高工资
select max(sal) from emp;
5.获取员工表中的最低工资
select min(sal) from emp;
6.获取员工表的平均工资
select avg(sal) from emp;
7.获取员工表的总工资
select sum(sal) from emp;
8.获取有多少行记录
select count(ename) from emp;
9.分组 group by 一般配合聚合函数使用
如果查询语句中出现了聚合函数和普通字段必须使用group by
求每个部门的总工资
select deptno '部门编号',sum(sal) from emp group by deptno;
10.having(聚合)在分组函数之上再筛选
求每个部门的总工资,只展示工资高于10000的信息
select deptno '部门编号',sum(sal) from emp group by deptno having sum(sal)>10000;
11.查找每个部门工资高于2000的员工的总工资,要求只显示总工资高于5000的,按总工资降序排列:
select sum(sal) from emp where sal>2000 group by deptno
having sum(sal)>5000
order by sum(sal) desc;
场景一:列出username字段有重读的数据
select username,count(*) as count from 表 group by username having count>1;
场景二:列出username字段重复记录:
select * from 表 where username in (select username from 表 group by username having count(username) > 1)
count(*)、count(1)和count(列名)的区别
1、执行效果上:
l count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
l count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
l count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
2、执行效率上:
l 列名为主键,count(列名)会比count(1)快
l 列名不为主键,count(1)会比count(列名)快
l 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
l 如果有主键,则 select count(主键)的执行效率是最优的
l 如果表只有一个字段,则 select count(*)最优。
DDL(数据定义语言)
create alter drop
create:创建
创建表:
create table 表名(
字段名 字段类型(长度),
...
字段名 字段类型(长度)
)
--创建表
create table user(
id int(10),
name varchar(50),
age int(10)
);
DDL(数据定义语言)
create:创建(表和数据库)
alter:修改/添加
添加字段
alter table 表名 add(字段名 字段类型(长度));
//添加一个性别字段
alter table user add (sex varchar(4));
//修改字段
alter table 表名 change name username 字段类型(长度);
alter table user change name username varchar(50);
//删除字段
alter table 表名 drop 字段名;
//--删除sex字段
alter table user drop sex;
drop:删除(删除表结构)
drop table 表名;
--删除user表
drop table user;
DML(数据操纵语言)
insert:添加
insert into 表名 values(与创建表时字段顺序的类型一致);
insert into 表名(需要添加的数据的字段) values(需要添加的数据的字段类型相同的数据
选择性添加
insert into 表名 set 字段=值,...,字段=值;
--第一种
insert into user values(1,'zhangsan',22);
--第二种select
insert into user(id,age) values(1,44);
--第三种
insert into user set id = 3,name='lisi';
改变编码格式 汉字兼容
set names gbk;
在db.propertites中加 ?useUnicode=true&characterEncoding=utf8
db.url=jdbc:mysql:///stockManageSysterm?useUnicode=true&characterEncoding=utf8
update:修改
update 表名 set 字段=值 where 条件字段=值;
会出错(会修改所有字段)
update user set name='张三' where id=1;
delete 删除
delete from 表名 where 条件字段=值; 如果整行是NULL 则 条件字段值 is NULL
如果不写where条件会删除整张表的所有记录
清空表(会保留表结构)
delete from user;
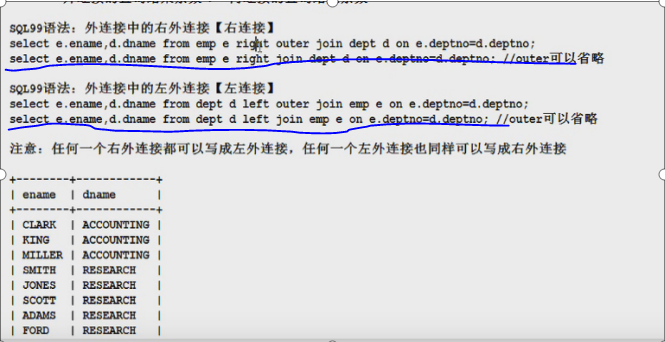
左(left)连接和右(right)连接,是相对join 关键字而言,想把左边全部展示就写left.
左连接把左边表的数据都展示出来,右连接把右边表的数据都展示出来