set hive.execution.engine = tez; --"mr", "tez", "spark"
set tez.queue.name=root.hello;
set tez.grouping.min-size=556000000;
set tez.grouping.max-size=3221225472;
set hive.tez.auto.reducer.parallelism=true;
set mapreduce.map.cpu.vcores=6;
set mapreduce.map.memory.mb=3072;
set mapreduce.map.java.opts=-Xmx2400m -Dfile.encoding=UTF-8;
set mapreduce.reduce.cpu.vcores=6;
set mapreduce.reduce.memory.mb=6144;
set mapreduce.reduce.java.opts=-Xmx4900m -Dfile.encoding=UTF-8;
set hive.exec.max.created.files=900000;
set mapred.job.queue.name=root.ESS-GODDOG-OFFLINE;
set mapred.job.name=t_dm_relation_graph;
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=3000;
set hive.exec.max.dynamic.partitions.pernode=1000;
set hive.fetch.task.conversion=more;
set hive.exec.parallel=true;
set hive.exec.parallel.thread.number=2048;
set mapreduce.job.jvm.numtasks=-1;
set hive.exec.reducers.bytes.per.reducer=500000000;
--set mapred.reduce.tasks=1024;
set hive.auto.convert.join=true;
set hive.map.aggr=true;
set hive.groupby.skewindata=true;
set mapred.max.split.size=256000000;
set mapred.min.split.size.per.node=134217728;
set mapred.min.split.size.per.rack=134217728;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set hive.merge.mapfiles=true;
set hive.merge.mapredfiles=true;
set hive.merge.size.per.task=256000000;
set hive.merge.smallfiles.avgsize=16000000;
set io.file.buffer.size=2097152;
set mapreduce.task.io.sort.mb=300;
set mapreduce.map.sort.spill.percent=0.8;
set mapreduce.task.io.sort.factor=10;
set mapreduce.reduce.shuffle.parallelcopies=8;
set hive.exec.compress.intermediate=true;
set mapreduce.map.output.compress=true;
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapreduce.reduce.merge.inmem.threshold=0;
set mapreduce.reduce.input.buffer.percent=0.8;
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
# 关闭local hadoop
set hive.exec.mode.local.auto=false;
set mapred.job.priority=HIGH;
set mapreduce.job.reduce.slowstart.completedmaps=0.15
Map端调优
map数控制
对于map运行时间过长或者map数据倾斜比较严重时可以通过设置切片大小实现对map数的控制,hive设置如下
set mapred.max.split.size=100000000; set mapred.min.split.size.per.node=100000000; set mapred.min.split.size.per.rack=100000000;
map小文件优化
使用Combinefileinputformat,将多个小文件打包作为一个整体的inputsplit,减少map任务数
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
Map 内存控制
ApplicationMaster执行在独立的jvm中以child process的方式执行 Mapper/Reducer task
子任务继承ApplicationMaster的环境,用户可以通过mapreduce.{map|reduce}.java.opts 指定child-jvm参数
set mapreduce.map.memory.mb=2048; set mapreduce.map.java.opts=-Xmx1536m
MapJoin优化
set hive.auto.convert.join = true; set hive.mapjoin.smalltable.filesize=25000000;
select /*+ MAPJOIN(table_a)*/,a.*,b.* from table_a a join table_b b on a.id = b.id
reduce端优化
reduce数控制
hive1.2.1自己如何确定reduce数: reduce个数的设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为256*1000*1000)。hive.exec.reducers.max(每个任务最大的reduce数,默认为1009)
可以直接通过mapred.reduce.tasks(新mapreduce.job.reduces) 设置map数的大小或者通过hive.exec.reducers.bytes.per.reducer设置每个reduce task处理的数据量大小来间接控制reduce大小
set mapred.reduce.tasks = 15; set hive.exec.reducers.bytes.per.reducer=500000000;
其中
set mapreduce.job.reduces=number的方式优先级最高(旧参数:mapred.reduce.tasks)。
set hive.exec.reducers.max=number优先级次之,
set hive.exec.reducers.bytes.per.reducer=number 优先级最低。从hive0.14开始,一个reducer处理文件的大小的默认值是256M。
reduce内存控制
set mapreduce.reduce.memory.mb=2048; set mapreduce.reduce.java.opts=-Xmx1536m
MapReduce输出压缩优化
Map端压缩
--启用中间数据压缩 set hive.exec.compress.intermediate=true -- 启用最终数据输出压缩 set hive.exec.compress.output=true; --开启mapreduce中map输出压缩功能 set mapreduce.map.output.compress=true; --设置mapreduce中map输出数据的压缩方式 set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec; --开启mapreduce最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; --设置mapreduce最终数据输出压缩方式 set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; --设置mapreduce最终数据输出压缩为块压缩。三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 set mapreduce.output.fileoutputformat.compress.type=BLOCK;
hive创建文件限制
Maximum number of HDFS files created by all mappers/reducers in a MapReduce job.
一个MR job中允许创建多少个HDFS文件
MR对文件创建的总数是有限制的,这个限制取决于参数:
hive.exec.max.created.files,默认值是100000,可以根据实际情况调整
hive.error.on.empty.partition false 当动态分区插入产生空值时是否抛出异常
set hive.exec.max.created.files=150000
MapReduce文件合并优化
--设置map端输出进行合并,默认为true set hive.merge.mapfiles = true --设置MapReduce结果输出进行合并,默认为false set hive.merge.mapredfiles = true --设置合并文件的大小 set hive.merge.size.per.task = 256*1000*1000 --当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。 set hive.merge.smallfiles.avgsize=16000000
Group by优化
group by数据倾斜
hive.map.aggr=true //map端是否聚合 hive.map.aggr.hash.force.flush.memory.threshold=0.9 //map侧聚合最大内存,超出后flush hive.map.aggr.hash.min.reduction=0.5 //开启聚合的最小阈值 hive.map.aggr.hash.percentmemory=0.5 //map端hash表聚合内存大小 --group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置 set hive.groupby.mapaggr.checkinterval=100000 ; --如果是group by过程出现倾斜 应该设置为true set hive.groupby.skewindata=true; --join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置 set hive.skewjoin.key=100000; --如果是join 过程出现倾斜 应该设置为true set hive.optimize.skewjoin=true;
空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上
案例
- 不随机分布空null值
1). 设置5个reduce个数
set mapreduce.job.reduces = 5;
2). JOIN两张表
insert overwrite table jointable select n.* from nullidtable n left join ori b on n.id = b.id;

可以看出来,出现了数据倾斜,某些reducer的资源消耗远大于其他reducer。
- 随机分布空null值
1) . 设置5个reduce个数
set mapreduce.job.reduces = 5;
2). JOIN两张表
insert overwrite table jointable select n.* from nullidtable n full join ori o on case when n.id is null then concat('hive', rand()) else n.id end = o.id;

可以看出来,消除了数据倾斜,负载均衡reducer的资源消耗。
动态分区优化
hive默认关闭了动态分区,使用动态分区时候,hive.exec.dynamic.partition参数必须设置成true;nonstrict模式表示允许所有的分区字段都可以使用动态分区。一般需要设置为nonstrict;当分区数比较多时hive.exec.max.dynamic.partitions和hive.exec.max.dynamic.partitions.pernode也需要根据时间情况调大
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; set hive.exec.max.dynamic.partitions=3000; set hive.exec.max.dynamic.partitions.pernode=1000;
Fetch优化
我们在执行hive代码的时候,一条简单的命令大部分都会转换成为mr代码在后台执行,但是有时候我们仅仅只是想获取一部分数据而已,仅仅是获取数据,还需要转化成为mr去执行就比较浪费时间和内存了
hive提供了一个参数hive.fetch.task.conversion,这个参数所对应着"none", "minimal", "more":
1.在none下 : disable hive.fetch.task.conversion。所有查询都启动MR。
2.在minimal下,我们执行select * ,limit,filter在一个表所属的分区表上操作,这三种情况都会直接进行数据的拿去,也就是直接把数据从对应的表格拿出来,不用跑mr代码
3.在more模式下,运行select,filter,limit,都是运行数据的fetch,不跑mr应用
set hive.fetch.task.conversion=more;
Insert overwrite优化
当动态分区过多时,由于需要创建太多的文件,FileSinkOperator很有可能会触发GC overlimit问题,可以启用hive.optimize.sort.dynamic.partition,动态分区列将被全局排序。这样我们就可以为每个分区值只打开一个文件写入器,可以极大的减小reduce端内存的压力
set hive.optimize.sort.dynamic.partition=true;
Hive Sql并行执行优化
hive.exec.parallel参数控制在同一个sql中的不同的job是否可以同时运行,默认为false。有时候一个sql中的有些job是不相关的,设置hive.exec.parallel=true可以让这些不相关的job同时跑
set hive.exec.parallel=true; set hive.exec.parallel.thread.number=32; //同一个sql允许最大并行度,默认为8。
1.1.1 reduce数据倾斜导致报错?

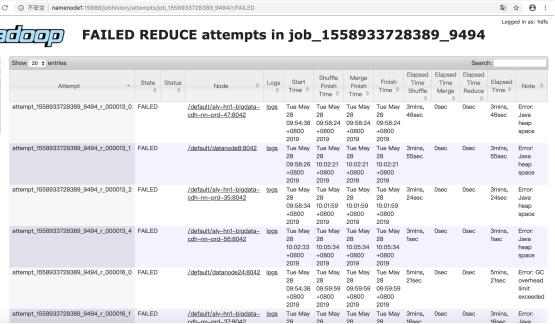
常见出错的原因:
通过INSERT语句插入数据到动态分区表中,也可能会超过HDFS同时打开文件数的限制。
如果没有join或聚合,INSERT ... SELECT语句会被转换为只有map任务的作业。mapper任务会读取输入记录然后将它们发送到目标分区目录。
在这种情况下,每个mapper必须为遇到的每个动态分区创建一个新的文件写入器(file writer)。
mapper在运行时所需的内存量随着它遇到的分区数量的增加而增加。
优化动作:
set hive.optimize.sort.dynamic.partition = true
通过这个优化,这个只有map任务的mapreduce会引入reduce过程,这样动态分区的那个字段比如日期在传到reducer时会被排序。由于分区字段是排序的,因此每个reducer只需要保持一个文件写入器(file writer)随时处于打开状态,在收到来自特定分区的所有行后,关闭记录写入器(record writer),从而减小内存压力。这种优化方式在写parquet文件时使用的内存要相对少一些,但代价是要对分区字段进行排序。
类似的详细说明,链接,如下:
https://www.jianshu.com/p/cfb827642905?from=groupmessage&isappinstalled=0