一、前述
在 Kaggle 的很多比赛中,我们可以看到很多 winner 喜欢用 xgboost,而且获得非常好的表现,今天就来看看 xgboost 到底是什么以及如何应用。Gradient boosting 是 boosting 的其中一种方法,所谓 Boosting ,就是将弱分离器 f_i(x) 组合起来形成强分类器 F(x) 的一种方法。
二、具体
1、举例
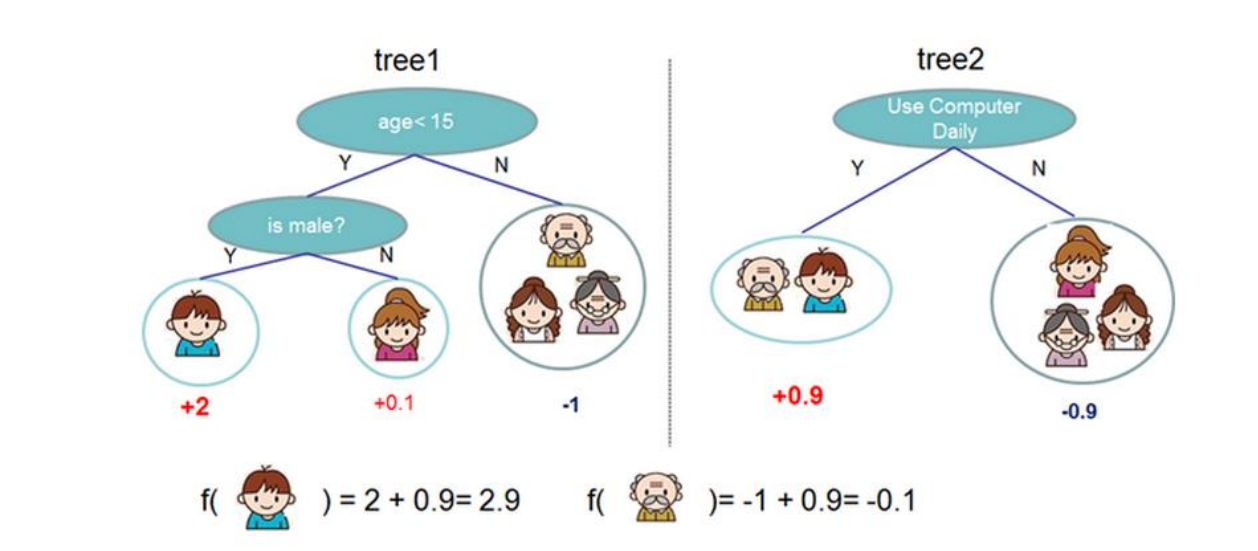
说明:在tree1和tree2里面 男孩的得分值是2.9,实际是将不同的权重值加和 。 相当于将不同的弱分类器组合起来,这种思想就是集成思想。
2、案例分析
举列子:比如比银行借钱,假设想向银行借1000块钱 ,第一次银行借给我们950块钱,与我们想要的差1000-950=50元 ,然后加一颗决策树,让银行再多借30元,这时银行借给我们950+30=980元 ,差1000-980=20元,然后再加一颗决策树,让银行多借15元,与最终目标差5元,即每一次不断拟合残差,达到最后效果。
我们希望每加一个树能够对预测值提升,所以保留之前的预测值,然后再这基础上再加上新的函数来预测,改变预测值,但是新函数的效果必须是朝着提升之前的预测结果目标(即减少误差,使目标函数越来越小)来的,这是xgboost的目标。

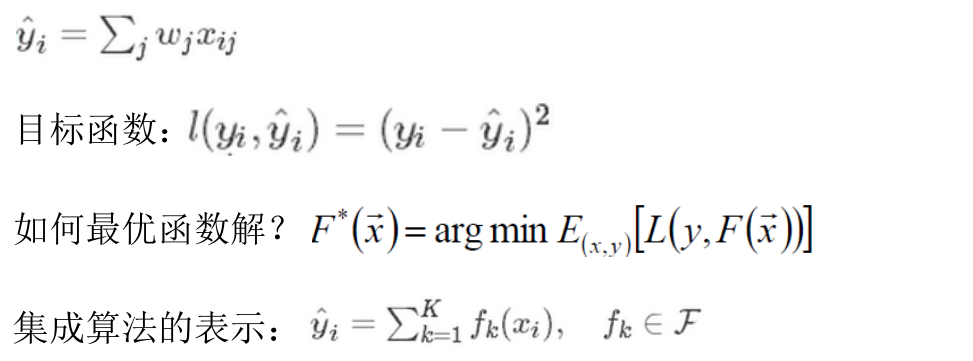
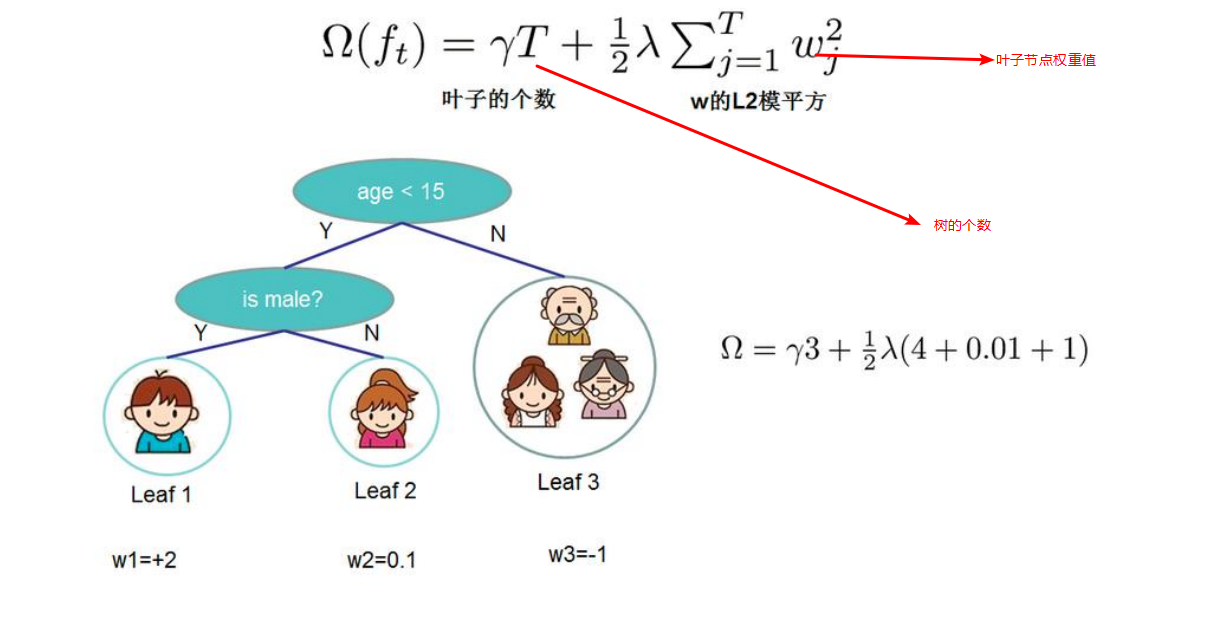
为了防止过拟合,我们需要对目标函数加上正则项,在决策树里面,叶子结点越多,越容易过拟合,所以我们需要对叶子节点个数加上正则化,决策越多,加上的惩罚越大,同时我们还要对叶子结点权重加上惩罚项,最终表现形式如下。T代表一棵树。

那么我们如何选择每一轮加入什么f呢?答案是非常直接的,选取一个f来使得我们的目标函数尽量最大地降低、最终损失函数的表示如下。希望在t-1颗树的基础上,新加一个树来优化这一个目标。
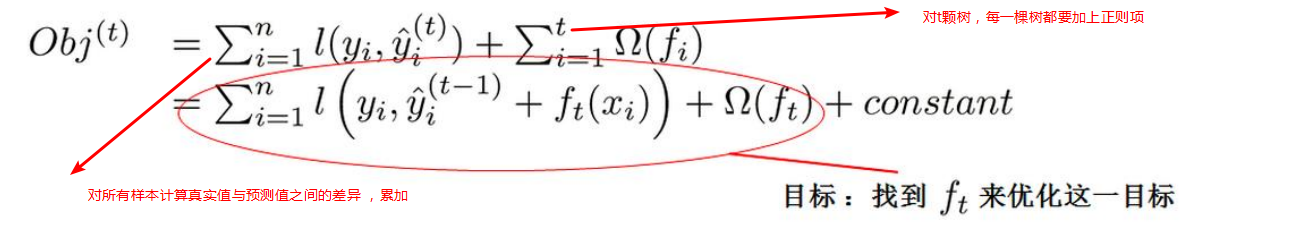

目标函数接着转换:



目标函数应用实例:

对于每次扩展,遍历所有的分割方案,选择基尼系数最大的一个分类来扩展。
