一、前述
上一篇讲述了神经网络中的调优实现,本文继续讲解。
二、L1,L2正则防止过拟合
使用L1和L2正则去限制神经网络连接的weights权重,限制更小
1、对于一层时可以定义如下:
一种方式去使用TensorFlow做正则是加合适的正则项到损失函数,当一层的时候,可以如下定义:

2、对于多层时可以定义如下:
可是如果有很多层,上面的方式不是很方便,幸运的是,TensorFlow提供了更好的选择,很多函数如get_variable()或者fully_connected()接受一个 *_regularizer 参数,可以传递任何以weights为参数,返回对应正则化损失的函数,l1_regularizer(),l2_regularizer()和l1_l2_regularizer()函数返回这个的函数。

上面的代码神经网络有两个隐藏层,一个输出层,同时在图里创建节点给每一层的权重去计算L1正则损失,TensorFlow自动添加这些节点到一个特殊的包含所有正则化损失的集合。你只需要添加这些正则化损失到整体的损失中,不要忘了去添加正则化损失到整体的损失中,否则它们将会被忽略。

三、Dropout防止过拟合
1、原理
在深度学习中,最流行的正则化技术,它被证明非常成功,即使在顶尖水准的神经网络中也可以带来1%到2%的准确度提升,这可能乍听起来不是特别多,但是如果模型已经有了95%的准确率,获得
2%的准确率提升意味着降低错误率大概40%,即从5%的错误率降低到3%的错误率!!!
在每一次训练step中,每个神经元,包括输入神经元,但是不包括输出神经元,有一个概率被临时的丢掉,意味着它将被忽视在整个这次训练step中,但是有可能下次再被激活(是随机的)
超参数p叫做dropout rate,一般设置50%,在训练之后,神经元不会再被dropout(设置成50%的话,传输到下一层就少了半的参数)
2、举例
公司每天投掷硬币只要一半的员工上班,或许带来的公司收入更高?公司或许因为这个被迫调整组织结构,也许员工一人会多个任务,而不是未来受制于一俩个员工的缺席,这里的员工类比到神经元
3、优点
相当于变相的提高数据量,但迭代次数要增加,可以理解成每次遮挡一部分数据,变相提高推广能力,使模型更加健壮,防止过拟合。
4、图例
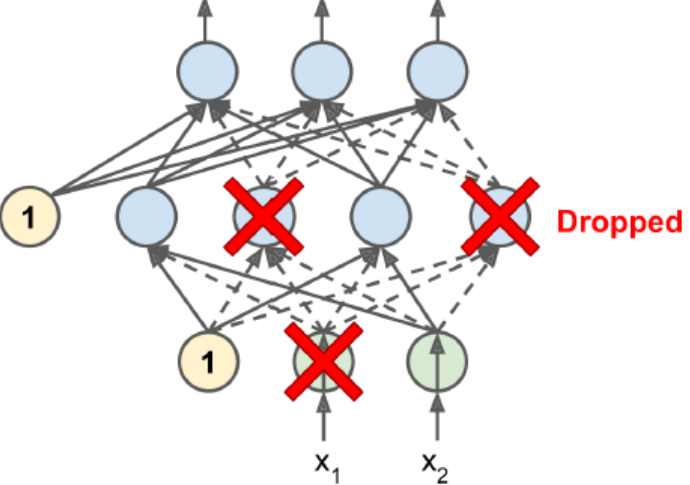
除了输出层其他都可以Dropout,一般我们Dropout的是全连接层。
5、应用
keep_prob是保留下来的比例,1-keep_prob是dropout rate
当训练的时候,把is_training设置为True,(丢掉一些数据),当测试的时候,设置为False(不能Dropout)

四、选择适当的激活函数
大多数情况下激活函数使用ReLU激活函数,这种激活函数计算更快,并且梯度下降不会卡在plateaus,并且对于大的输入值,它不会饱和,相反对比logistic function和hyperbolic tangent
function,将会饱和在1对于输出层,
softmax激活函数通常是一个好的选择对于分类任务,因为类别和类别之间是互相排斥的,(会做到归一化)
对于回归任务,根本不使用激活函数
多层感知机通常用于分类问题,二分类,也有很多时候会用于多分类,需要把输出层的激活函数改成共享的softmax函数,输出变成用于评估属于哪个类别的概率值
五、数据增大
1、原理
从现有的数据产生一些新的训练样本,人工增大训练集,这将减少过拟合
2、举例
例如如果你的模型是分类蘑菇图片,你可以轻微的平移,旋转,改变大小,然后增加这些变化后的图片到训练集,这使得模型可以经受位置,方向,大小的影响,如果你想用模型可以经受光条件的影响,你可以同理产生许多图片用不同的对比度,假设蘑菇对称的,你也可以水平翻转图片TensorFlow提供一些图片操作算子,例如transposing(shifting),rotating,resizing,flipping,cropping,adjusting brightness(亮度),contrast(对比度),saturation(饱和度),hue(色调)
3、图示
