噢,它明白了,河水既没有牛伯伯说的那么浅,也没有小松鼠说的那么深,只有亲自试过才知道。
---寓言故事《小马过河》
数据处理是每种语言必备的功能,Java更甚之,数据集可以允许重复,也可以不允许重复,可以允许null存在,也可以不允许null存在,可以自动排序,也可以不自动排序,可以是阻塞式的,也可以是非阻塞式的,可以是栈,也可以是队列......
本章将围绕我们使用最多的三个数据集合(数组,ArrayList和HashMap)来阐述在开发过程中要注意的事项,并由此延伸至Set、Quene、Stack等集合。
建议60:性能考虑,数组是首选
数组在实际的系统开发中用的越来越少了,我们通常只有在阅读一些开源项目时才会看到它们的身影,在Java中它确实没有List、Set、Map这些集合类用起来方便,但是在基本类型处理方面,数组还是占优势的,而且集合类的底层也都是通过数组实现的,比如对一数据集求和这样的计算:

1 //对数组求和
2 public static int sum(int datas[]) {
3 int sum = 0;
4 for (int i = 0; i < datas.length; i++) {
5 sum += datas[i];
6 }
7 return sum;
8 }
对一个int类型 的数组求和,取出所有数组元素并相加,此算法中如果是基本类型则使用数组效率是最高的,使用集合则效率次之。再看使用List求和:
1 // 对列表求和计算
2 public static int sum(List<Integer> datas) {
3 int sum = 0;
4 for (int i = 0; i < datas.size(); i++) {
5 sum += datas.get(i);
6 }
7 return sum;
8 }
注意看sum += datas.get(i);这行代码,这里其实已经做了一个拆箱动作,Integer对象通过intValue方法自动转换成了一个int基本类型,对于性能濒于临界的系统来说该方案是比较危险的,特别是大数量的时候,首先,在初始化List数组时要进行装箱操作,把一个int类型包装成一个Integer对象,虽然有整型池在,但不在整型池范围内的都会产生一个新的Integer对象,而且众所周知,基本类型是在栈内存中操作的,而对象是堆内存中操作的,栈内存的特点是:速度快,容量小;堆内存的特点是:速度慢,容量大(从性能上讲,基本类型的处理占优势)。其次,在进行求和运算时(或者其它遍历计算)时要做拆箱动作,因此无谓的性能消耗也就产生了。在实际测试中发现:对基本类型进行求和运算时,数组的效率是集合的10倍。
注意:性能要求较高的场景中使用数组代替集合。
建议61:若有必要,使用变长数组
Java中的数组是定长的,一旦经过初始化声明就不可改变长度,这在实际使用中非常不方便,比如要对班级学生的信息进行统计,因为我们不知道一个班级会有多少学生(随时都可能会有学生入学、退学或转学),所以需要一个足够大的数组来容纳所有的学生,但问题是多大才算足够大?20年前一台台式机64MB的内存已经很牛了,现在要是没有2GB的内存(现在这个都太小了)你都不好意思跟别人交流计算机的配置,所以呀,这个足够大是相对于当时的场景而言的,随着环境的变化,"足够大"也可能会转变成"足够小",然后就会出现超出数组最大容量的情况,那该如何解决呢?事实上,可以通过对数组扩容"婉转" 地解决该问题,代码如下:
1 public static <T> T[] expandCapacity(T[] datas, int newLen) {
2 // 不能是负值
3 newLen = newLen < 0 ? 0 : newLen;
4 // 生成一个新数组,并拷贝原值
5 return Arrays.copyOf(datas, newLen);
6 }
上述代码采用的是Arrays数组工具类的copyOf方法,产生了一个newLen长度的新数组,并把原有的值拷贝了进去,之后就可以对超长的元素进行赋值了(依据类型的不同分别赋值0、false或null),使用方法如下:
public class Client61 {
public static void main(String[] args) {
//一个班级最多容纳60个学生
Stu [] stuNums= new Stu[60];
//stuNums初始化......
//偶尔一个班级可以容纳80人,数组加长
stuNums=expandCapacity(stuNums,80);
/* 重新初始化超过限额的20人...... */
}
public static <T> T[] expandCapacity(T[] datas, int newLen) {
// 不能是负值
newLen = newLen < 0 ? 0 : newLen;
// 生成一个新数组,并拷贝原值
return Arrays.copyOf(datas, newLen);
}
}
class Stu{
}
通过这样的处理方式,曲折的解决了数组的变长问题,其实,集合的长度自动维护功能的原理与此类似。在实际开发中,如果确实需要变长的数据集,数组也是在考虑范围之内的,不能因固定长度而将其否定之。
建议62:警惕数组的浅拷贝
有这样一个例子,第一个箱子里有赤橙黄绿青蓝紫7色气球,现在希望在第二个箱子中也放入7个气球,其中最后一个气球改为蓝色,也就是赤橙黄绿青蓝蓝7个气球,那我们很容易就会想到第二个箱子中的气球可以通过拷贝第一个箱子中的气球来实现,毕竟有6个气球是一样的嘛,来看实现代码:
1 import java.util.Arrays;
2 import org.apache.commons.lang.builder.ToStringBuilder;
3
4 public class Client62 {
5 public static void main(String[] args) {
6 // 气球数量
7 int ballonNum = 7;
8 // 第一个箱子
9 Balloon[] box1 = new Balloon[ballonNum];
10 // 初始化第一个箱子中的气球
11 for (int i = 0; i < ballonNum; i++) {
12 box1[i] = new Balloon(Color.values()[i], i);
13 }
14 // 第二个箱子的气球是拷贝第一个箱子里的
15 Balloon[] box2 = Arrays.copyOf(box1, box1.length);
16 // 修改最后一个气球颜色
17 box2[6].setColor(Color.Blue);
18 // 打印出第一个箱子中的气球颜色
19 for (Balloon b : box1) {
20 System.out.println(b);
21 }
22
23 }
24 }
25
26 // 气球颜色
27 enum Color {
28 Red, Orange, Yellow, Green, Indigo, Blue, Violet
29 }
30
31 // 气球
32 class Balloon {
33 // 编号
34 private int id;
35 // 颜色
36 private Color color;
37
38 public Balloon(Color _color, int _id) {
39 color = _color;
40 id = _id;
41 }
42
43 public int getId() {
44 return id;
45 }
46
47 public void setId(int id) {
48 this.id = id;
49 }
50
51 public Color getColor() {
52 return color;
53 }
54
55 public void setColor(Color color) {
56 this.color = color;
57 }
58
59 @Override
60 public String toString() {
61 //apache-common-lang包下的ToStringBuilder重写toString方法
62 return new ToStringBuilder(this).append("编号", id).append("颜色", color).toString();
63 }
64
65 }
第二个箱子里最后一个气球的颜色毫无疑问是被修改为蓝色了,不过我们是通过拷贝第一个箱子里的气球然后再修改的方式来实现的,那会对第一个箱子的气球颜色有影响吗?我们看看输出结果:
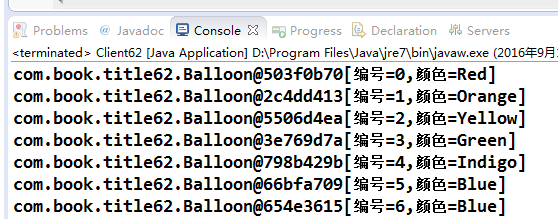
最后一个气球颜色竟然也被修改了,我们只是希望修改第二个箱子的气球啊,这是为何?这是典型的浅拷贝(Shallow Clone)问题,以前第一章序列化时讲过,但是这里与之有一点不同:数组中的元素没有实现Serializable接口。
确实如此,通过copyOf方法产生的数组是一个浅拷贝,这与序列化的浅拷贝完全相同:基本类型是直接拷贝值,其它都是拷贝引用地址。需要说明的是,数组的clone方法也是与此相同的,同样是浅拷贝,而且集合的clone方法也都是浅拷贝,这就需要大家在拷贝时多留心了。
问题找到了,解决办法也很简单,遍历box1的每个元素,重新生成一个气球(Balloon)对象,并放置到box2数组中,代码比较简单,不再赘述。
该方法用的最多的地方是在使用集合(如List),进行业务处理时,比如发觉需要拷贝集合中的元素,可集合没有提供拷贝方法,如果自己写会很麻烦,所以干脆使用List.toArray方法转换成数组,然后通过Arrays.copyOf拷贝,再转换回集合,简单便捷!但是,非常遗憾的是,这里我们又撞到浅拷贝的枪口上了,虽然很多时候浅拷贝可以解决业务问题,但更多时候会留下隐患,我们需要提防又提防。
建议63:在明确的场景下,为集合指定初始容量
我们经常使用ArrayList、Vector、HashMap等集合,一般都是直接用new跟上类名声明出一个集合来,然后使用add、remove等方法进行操作,而且因为它是自动管理长度的,所以不用我们特别费心超长的问题,这确实是一个非常好的优点,但也有我们必须要注意的事项。
下面以ArrayList为例深入了解一下Java是如何实现长度的动态管理的,先从add方法的阅读开始,代码(JDK7)如下:
1 public boolean add(E e) {
2 //扩展长度
3 ensureCapacityInternal(size + 1); // Increments modCount!!
4 //追加元素
5 elementData[size++] = e;
6 return true;
7 }
我们知道ArrayList是一个大小可变的数组,但它在底层使用的是数组存储(也就是elementData变量),而且数组长度是定长的,要实现动态长度必然要进行长度的扩展,ensureCapacityInternal方法提供了此功能,代码如下:
private void ensureCapacityInternal(int minCapacity) {
//修改计数器
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
//上次(原始)定义的数组长度
int oldCapacity = elementData.length;
//新长度为原始长度+原始长度右移一位 ==>原始长度的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//数组拷贝,生成新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
大概分析一下这些源码,这个源码还是JDK7之前的版本上做了优化处理的。先说一下第一个方法ensureCapacityIntenal, 方法名的英文大致意思是“确保内部容量”,这里要说明,size表示的是现有的元素个数,并非ArrayList的容量,容量应该是数组 elementData的长度。参数minCapacity是需要检查的最小容量,即方法的功能就是确保elementData的长度不小于 minCapacity,如果不够,则调用grow增加容量。容量的增长也算结构性变动,所以modCount需要加1。
grow方法:先对容量扩大1.5倍,这里oldCapacity >> 1是二进制操作右移,相当于除以2,如果不知道这个面壁去吧。接再来把新的临时容量(还没正式改变容量,应该叫预期容量)和实际需要的最小容量比较,如果还不满 足,则把临时容量改成需要的最小容量值。在判断容量是否超过MAX_ARRAY_SIZE的值,MAX_ARRAY_SIZE值为 Integer.MAX_VALUE - 8,比int的最大值小8,不知道设计初衷是什么,可能方便判断吧。如果已经超过,调用hugeCapacity方法检查容量的int值是不是已经溢出。一般很 少用到int最大值的情况,那么多数据也不会用ArrayList来做容器了,估计没机会见到hugeCapacity运行一次了。最后确定了新的容量,就使用Arrays.copyOf方法来生成新的数组,copyOf也已经完成了将就的数据拷贝到新数组的工作。
回归正题,大家注意看数组长度的计算方法,并不是增加一个元素,elementData的长度就加1,而是在达到elementData长度的临界点时,才将elementData扩容1.5倍,这样实现避免了多次copyOf方法的性能开销,否则每增加一个元素都要扩容一次,那性能会更差。不知道大家有没有这样一个疑问,为啥要扩容1.5倍,而不是2.5,倍、3.5倍呢?其实我也这么想过,原因是一次扩容太大,占用的内存就越大,浪费的内存也就越多(1.5倍扩容,最多浪费33%的数组空间,而2.5倍则最多消耗60%的内存),而一次扩容太小,则需要多次对数组重新分配内存,性能消耗严重,经过测试验证,扩容1.5倍既满足了性能要求,也减少了内存消耗。
现在我们知道了ArrayList的扩容原则,那还有一个问题:elementData的默认长度是多少呢?答案是10,如果我们使用默认方式声明ArrayList,如new ArrayList(),则elementData的初始长度是10,我们看看ArrayList的三个构造函数。
//无参构造
public ArrayList() {
this(10);
}
//构造一个具有指定初始容量的空列表。
public ArrayList(int initialCapacity) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
}
//构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
size = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
ArrayList():默认构造函数,提供初始容量为10的空列表。
ArrayList(int initialCapacity):构造一个具有指定初始容量的空列表。
ArrayList(Collection<? extends E> c):构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
从这里我们可以看出,如果不设置初始容量,系统会按照1.5倍的规则扩容,每次扩容都是一次数组的拷贝,如果数据量大,这样的拷贝会非常消耗资源,而且效率非常低下。所以,我们如果知道一个ArrayList的可能长度,然后对ArrayList设置一个初始容量则可以显著提高系统性能。
其它的集合如Vector和ArrayList类似,只是扩容的倍数不同而已,Vector扩容2倍,大家有兴趣的话可以看看Vector,HashMap的JDK源码。
建议64:多种最值算法,适时选择
对一批数据进行排序,然后找出其中的最大值或最小值,这是基本的数据结构知识。在Java中我们可以通过编写算法的方式,也可以通过数组先排序再取值的方式来实现,下面以求最大值为例,解释一下多种算法:
(1)、自行实现,快速查找最大值
先看看用快速查找法取最大值的算法,代码如下:
1 public static int max(int[] data) {
2 int max = data[0];
3 for (int i : data) {
4 max = max > i ? max : i;
5 }
6 return max;
7 }
这是我们经常使用的最大值算法,也是速度最快的算法。它不要求排序,只要遍历一遍数组即可找出最大值。
(2)、先排序,后取值
对于求最大值,也可以采用先排序后取值的方式,代码如下:
1 public static int max(int[] data) {
2 Arrays.sort(data);
3 return data[data.length - 1];
4 }
从效率上讲,当然是自己写快速查找法更快一些了,只用遍历一遍就可以计算出最大值,但在实际测试中发现,如果数组量少于10000,两个基本上没有区别,但在同一个毫秒级别里,此时就可以不用自己写算法了,直接使用数组先排序后取值的方式。
如果数组元素超过10000,就需要依据实际情况来考虑:自己实现,可以提高性能;先排序后取值,简单,通俗易懂。排除性能上的差异,两者都可以选择,甚至后者更方便一些,也更容易想到。
现在问题来了,在代码中为什么先使用data.clone拷贝再排序呢?那是因为数组也是一个对象,不拷贝就改变了原有的数组元素的顺序吗?除非数组元素的顺序无关紧要。那如果要查找仅次于最大值的元素(也就是老二),该如何处理呢?要注意,数组的元素时可以重复的,最大值可能是多个,所以单单一个排序然后取倒数第二个元素时解决不了问题的。
此时,就需要一个特殊的排序算法了,先要剔除重复数据,然后再排序,当然,自己写算法也可以实现,但是集合类已经提供了非常好的方法,要是再使用自己写算法就显得有点重复造轮子了。数组不能剔除重复数据,但Set集合却是可以的,而且Set的子类TreeSet还能自动排序,代码如下:
1 public static int getSecond(Integer[] data) {
2 //转换为列表
3 List<Integer> dataList = Arrays.asList(data);
4 //转换为TreeSet,剔除重复元素并升序排列
5 TreeSet<Integer> ts = new TreeSet<Integer>(dataList);
6 //取得比最大值小的最大值,也就是老二了
7 return ts.lower(ts.last());
8 }
剔除重复元素并升序排列,这都是由TreeSet类实现的,然后可再使用lower方法寻找小于最大值的值,大家看,上面的程序非常简单吧?那如果是我们自己编写代码会怎么样呢?那至少要遍历数组两遍才能计算出老二的值,代码复杂度将大大提升。因此在实际应用中求最值,包括最大值、最小值、倒数第二小值等,使用集合是最简单的方式,当然从性能方面来考虑,数组才是最好的选择。
注意:最值计算时使用集合最简单,使用数组性能最优。