HA Hadoop完全分布式环境部署
1、背景知识
HDFS HA通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
Hadoop 2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。这里我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode,这里还配置了一个Zookeeper集群,用于ZKFC故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为Active状态。
YARN的ResourceManager也存在单点故障问题,这个问题在hadoop-2.4.1得到了解决:有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调。
YARN框架下的MapReduce可以开启JobHistoryServer来记录历史任务信息,否则只能查看当前正在执行的任务信息。
Zookeeper的作用是负责HDFS中NameNode主备节点的选举,和YARN框架下ResourceManaer主备节点的选举。
2、使用软件及其版本
环境
虚拟机:VirtualBox 6.0.24 r139119
Linux:CentOS 7
Windows:Windows10
软件
JDK:Jdk1.8_131
Hadoop:Hadoop-2.6.0-cdh5.7.0
Zookeeper:zookeeper-3.4.5-cdh5.7.0
工具
远程连接工具:XShell6
SFTP工具:FileZilla3.33.0
3、目标
-
HA Hadoop高可用集群搭建
4、操作步骤
-
集群规划
-
规划集群由3台主机构成
主机名 IP Namenode DataNode Yarn Zookeeper JournalNode master 192.168.137.2 是 是 否 是 是 slave01 192.168.137.3 是 是 是 是 是 slave02 192.168.137.4 否 是 是 是 是
-
-
HA Hadoop高可用集群搭建
注意:
HA Hadoop在前面章节的完全分布式Hadoop的配置环境上搭建(注意:先删除/opt/hdfs/tmp下所有的文件)。
为了防止namenode不能热切换,最好安装此插件,在master和slave01上安装,使用命令:
sudo yum -y install psmisc-
在mastar主机上修改配置文件
-
修改hadoop目录下/etc/hadoop/core-site.xml文件,使用命令:
sudo vi core-site.xml调整内容为:
<!-- 指定hdfs的nameservice为名称ns,把两个 NameNode的地址组装成一个集群 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--指定hadoop数据存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hdfs/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave01:2181,slave02:2181</value>
</property>
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property> -
修改hadoop目录下/etc/hadoop/hdfs-site.xml文件,使用命令:
sudo vi hdfs-site.xml调整内容为:
<!--完全分布式集群名称,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave01:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave01:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave01:8485;slave02:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hdfs/journal</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hdfs/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hdfs/tmp/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
省略后续截图
-
修改hadoop目录下/etc/hadoop/yarn-site.xml文件,使用命令:
sudo vi yarn-site.xml调整内容为:
<!-- 开启YARN HA -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 启用自动故障转移 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定YARN HA的名称 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarncluster</value>
</property>
<!-- 指定两个resourcemanager的名称 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 配置rm1,rm2的主机 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>slave02</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave01</value>
</property>
<!-- 配置YARN的http端口 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>slave02:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>slave01:8088</value>
</property>
<!-- 配置zookeeper的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave01:2181,slave02:2181</value>
</property>
<!-- 配置zookeeper的存储位置 -->
<property>
<name>yarn.resourcemanager.zk-state-store.parent-path</name>
<value>/rmstore</value>
</property>
<!-- 开启yarn resourcemanager restart -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置resourcemanager的状态存储到zookeeper中 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 开启yarn nodemanager restart -->
<property>
<name>yarn.nodemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置nodemanager IPC的通信端口 -->
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
省略后续截图
-
在master节点复制hadoop目录到slave01,slave02节点,覆盖原有内容,使用命令:
scp -r hadoop-2.6.0-cdh5.7.0/ hadoop@slave01:~/app/scp -r hadoop-2.6.0-cdh5.7.0/ hadoop@slave02:~/app/
-
-
启动集群
-
在所有节点(master,slave01,slave02)启动Zookeeper集群
Zookeeper安装目录的/bin目录下启动,使用命令:
/zkServer.sh start启动完后,使用命令
./zkServer.sh status查看状态


Mode为leader或者follower则代表启动Zookeeper成功!
-
在master节点启动journalnode
进入到hadoop安装目录sbin文件夹下,使用命令:
./hadoop-daemons.sh start journalnode
在master,slave01,slave02使用
jps命令查看进程:


-
在master节点格式化zkfc,使用命令:
hdfs zkfc -formatZK
-
在master上格式化hdfs,使用命令:
hadoop namenode -format
-
在master上启动namenode
进入到hadoop安装目录sbin文件夹下,使用命令:
./hadoop-daemon.sh start namenode启动namenode进程

使用
jps命令,查看进程
-
在slave01上启动数据同步和standby的namenode
在slave01上,使用命令:
hdfs namenode -bootstrapStandby同步数据

进入到hadoop安装目录sbin文件夹下,使用命令:
./hadoop-daemon.sh start namenode启动namenode进程

使用
jps命令,查看进程
-
在master上启动datanode
进入到hadoop安装目录sbin文件夹下,使用命令:
./hadoop-daemons.sh start datanode
在master,slave01,slave02节点上,使用
jps命令,查看进程


-
在在slave01和slave02上启动yarn
在slave01节点和slave02节点上,进入到hadoop安装目录sbin文件夹下,使用命令:
./start-yarn.sh -
在master上启动zkfc
进入到hadoop安装目录sbin文件夹下,使用命令:
./hadoop-daemons.sh start zkfc
-
-
检验
-
在所有节点查看进程
master节点,使用
jps命令:
slave01节点,使用
jps命令:
slave02节点,使用
jps命令:
如果显示以上信息,表示HA Hadoop集群配置成功~
-
-
测试
-
在(master的ip)192.168.137.2:50070和(slave01的ip)192.168.137.3:50070上查看namenode的状态:

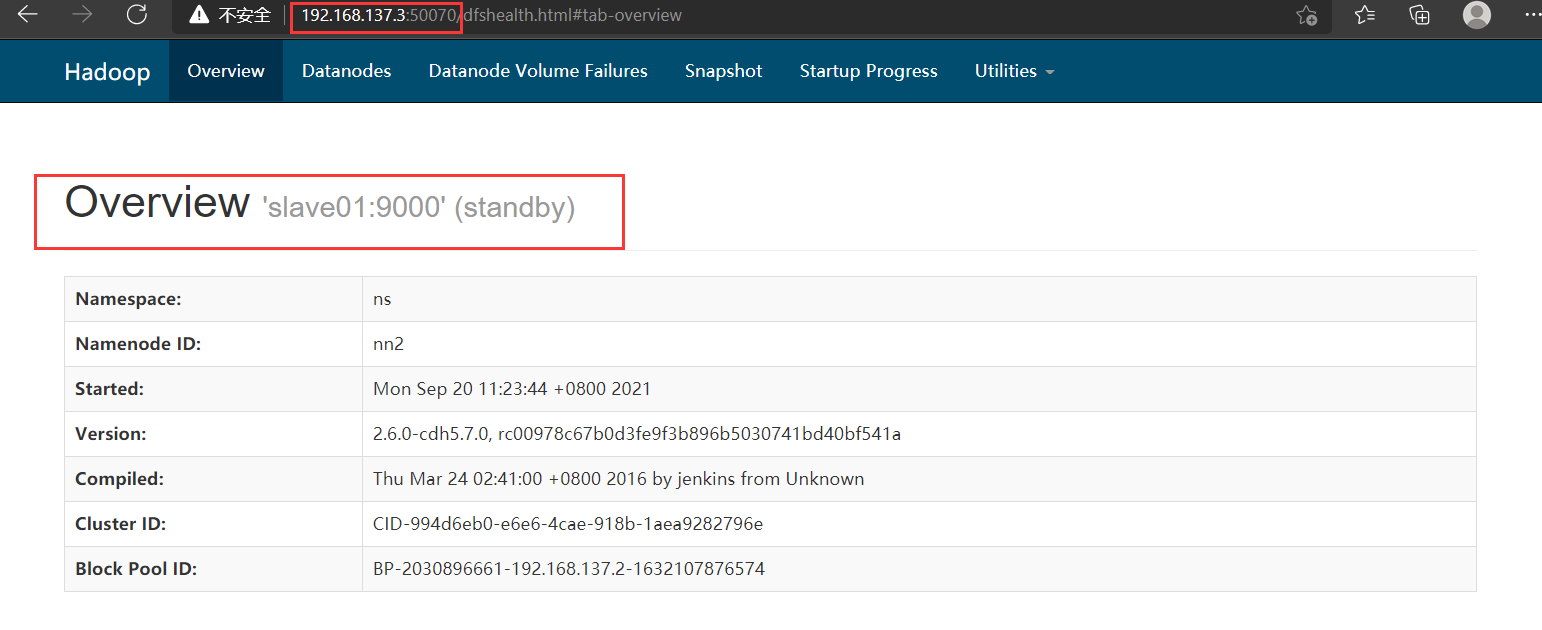
都能访问且一个是active一个是standby状态
-
访问(slave01)192.168.137.3:8088和(slave02)192.168.137.4:8088查看Yarn的Resourcemanager状态

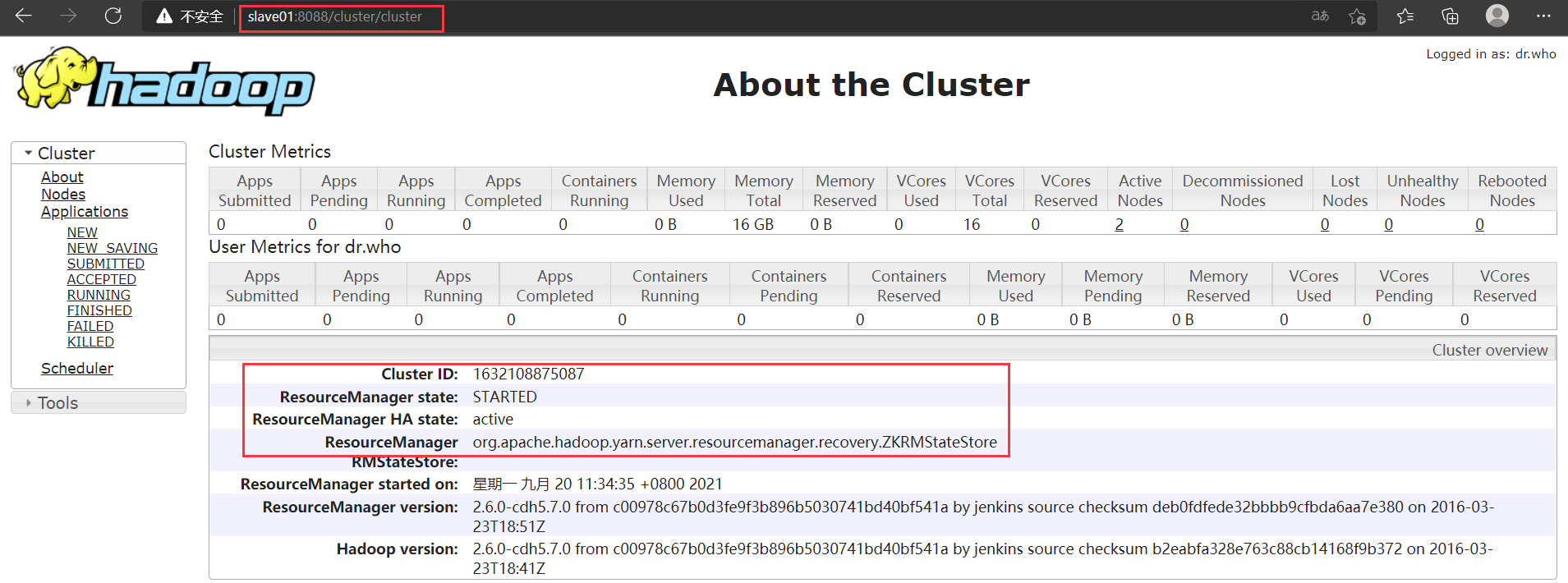
若是一个能访问,访问另一个时跳到前一个的时候并不是错误,那样是正常的 能访问的那个是active状态,若是两个都能访问则一个是active一个是standby
-
首先在master主机上想hdfs上传一个文件,然后尝试能否在slave01和slave02上查看
master节点,创建test文件,并上传到hdfs文件系统,然后在hdfs文件系统中查看文件:


slave01节点,查看hdfs文件系统中的文件:

slave02节点,查看hdfs文件系统中的文件:

-
测试是否能够热切换
在master节点,杀死namenode进程

在网页查看standby的是否变为active,从standby成功变更为active则表示成功


-
测试yarn HA高可用


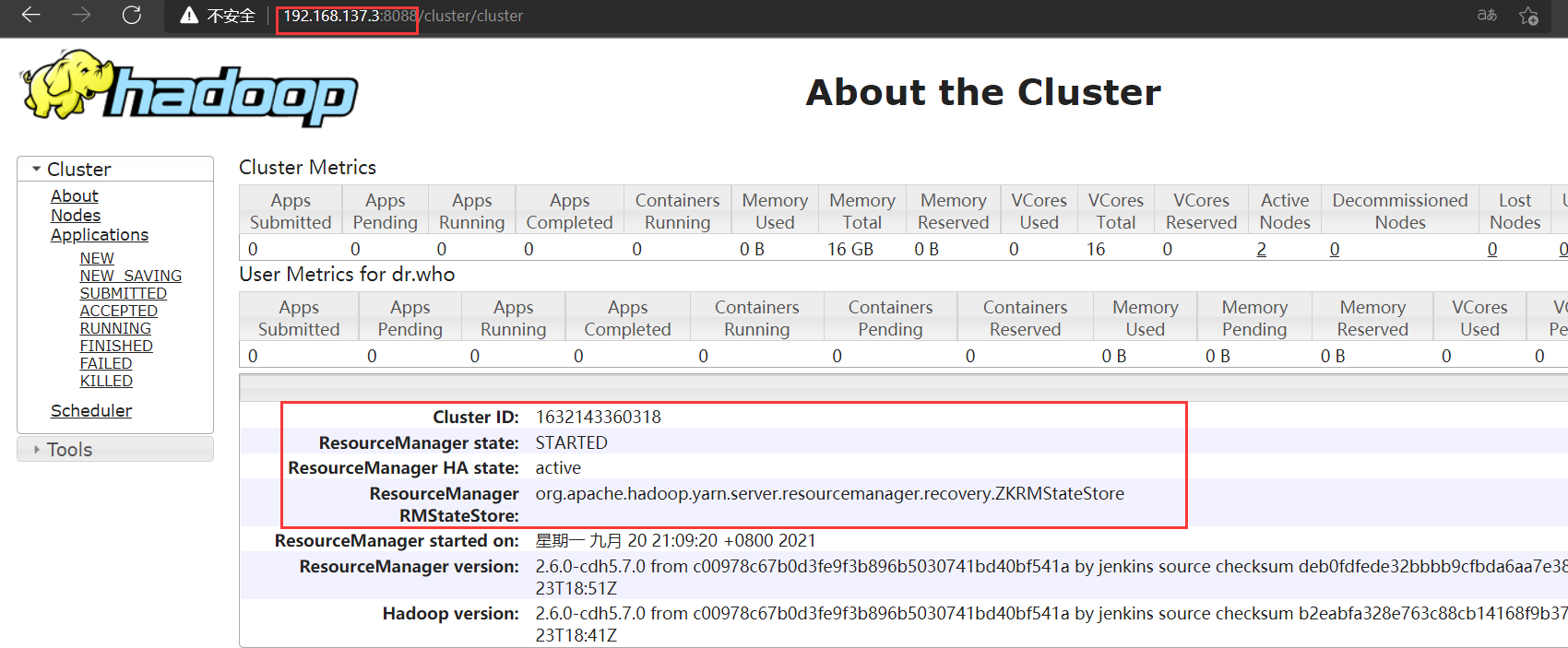
-
-
5、总结