梯度下降法用于求函数的极小值,不一定是最小值
考虑一个单变量的线性回归问题,其中自变量x和因变量y的值如下:
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [106000, 107200, 108400, 109600, 110800, 112000, 113200, 114400, 115600, 116800, 118000]
为了把求解线性回归转变成求解一个极小值问题,首先假设线性回归方程的两个参数为θ0和θ1,则回归方程可以写成
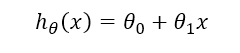
由此可以定义代价函数

可以看出代价函数实际上是每一个样本点的实际值与预测值的误差平均,这里的系数1/2只是为了后续处理方便。
计算代价函数的代码如下
def compute_cost(x_data, y_data, theta): cost = 0 for i in range(len(x_data)): cost += (theta[0] + theta[1] * x_data[i] - y_data[i]) ** 2 return cost / (2 * len(x_data))
这时我们只需要找到合理的θ0和θ1,使得代价函数的值最小即可。也即
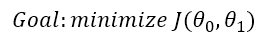
我们考虑使用迭代的方法求得这两个参数的值:首先先人为任意的给这两个参数赋值,然后让这两个值不断往梯度的反方向移动一定距离,梯度方向即沿着这个方向值能上升的最快的方向。
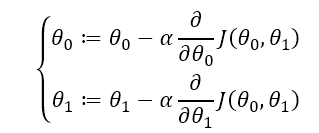
其中的α被称为学习率(learning rate),是一个人为设置的超参数,一般可以取0.01或0.03。θ0和θ1重复执行以上步骤,直到代价函数的值等于零(在编程中即要求足够小)或者达到最大的迭代次数为止。
求θ0的偏导数的过程如下
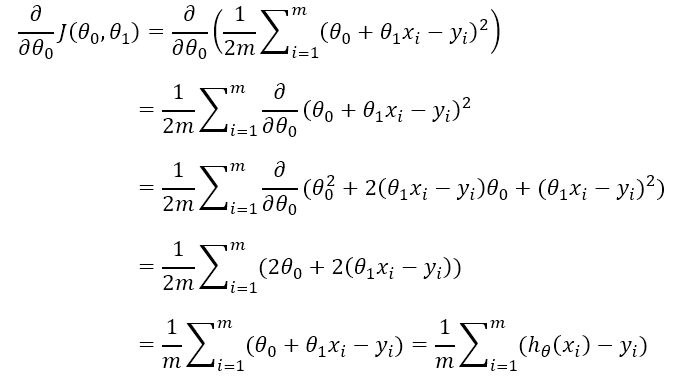
对应代码:
def compute_theta0_partial_derivative(x_data, y_data, theta): res = 0 for i in range(len(x_data)): res += theta[0] + theta[1] * x_data[i] - y_data[i] return res / len(x_data)
求θ1的偏导数的过程如下
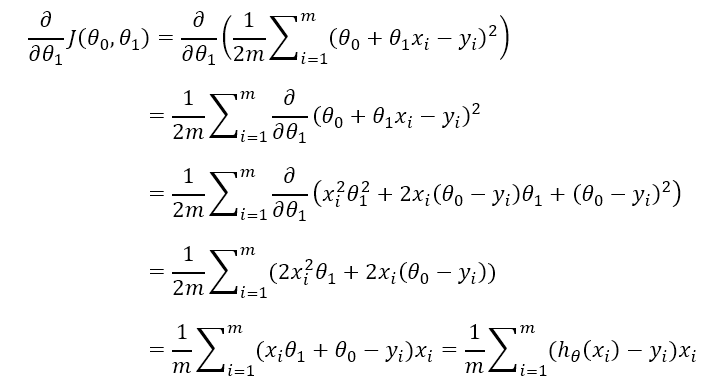
对应代码:
def compute_theta1_partial_derivative(x_data, y_data, theta): res = 0 for i in range(len(x_data)): res += (theta[0] + theta[1] * x_data[i] - y_data[i]) * x_data[i] return res / len(x_data)
最后便是梯度下降法的主体:
def batch_gradient_descent(x_data, y_data, max_iter=10000, theta=[0, 0], learning_rate=0.03): for i in range(max_iter): if compute_cost(x_data, y_data, theta) <= 0.00001: break new_theta = [0, 0] new_theta[0] = theta[0] - learning_rate * compute_theta0_partial_derivative(x_data, y_data, theta) new_theta[1] = theta[1] - learning_rate * compute_theta1_partial_derivative(x_data, y_data, theta) theta = new_theta return theta
由于这种方法在计算代价函数时遍历了所有参数,因此也被称为批量梯度下降。
上述代码计算的结果为 [105999.9916695726, 1200.0011996567646]
也即利用批量梯度下降法所求得的线性回归问题的答案约为y=106000x+1200
梯度下降法相比最小二乘法的优势在于,梯度下降法可以推广到任意元的回归问题同时代码的复杂程度几乎不变。梯度下降法不用考虑多重共线性等问题。
完整代码如下(入门为了简单连numpy库都没有用)
x = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] y = [106000, 107200, 108400, 109600, 110800, 112000, 113200, 114400, 115600, 116800, 118000] def compute_cost(x_data, y_data, theta): cost = 0 for i in range(len(x_data)): cost += (theta[0] + theta[1] * x_data[i] - y_data[i]) ** 2 return cost / (2 * len(x_data)) def compute_theta0_partial_derivative(x_data, y_data, theta): res = 0 for i in range(len(x_data)): res += theta[0] + theta[1] * x_data[i] - y_data[i] return res / len(x_data) def compute_theta1_partial_derivative(x_data, y_data, theta): res = 0 for i in range(len(x_data)): res += (theta[0] + theta[1] * x_data[i] - y_data[i]) * x_data[i] return res / len(x_data) def batch_gradient_descent(x_data, y_data, max_iter=10000, theta=[0, 0], learning_rate=0.03): for i in range(max_iter): if compute_cost(x_data, y_data, theta) <= 0.00001: break new_theta = [0, 0] new_theta[0] = theta[0] - learning_rate * compute_theta0_partial_derivative(x_data, y_data, theta) new_theta[1] = theta[1] - learning_rate * compute_theta1_partial_derivative(x_data, y_data, theta) theta = new_theta return theta print(batch_gradient_descent(x, y))