一、基本概念
1、什么是 ElasticSearch
ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。支持通过HTTP使用JSON进行数据索引。
2、主要术语
节点 node
它指的是Elasticsearch的单个正在运行的实例。单个物理和虚拟服务器容纳多个节点,这取决于其物理资源的能力,如RAM,存储和处理能力。它是群集的一部分,可以存储数据,并参与群集的索引和搜索功能。
集群 cluster
它是一个或多个节点的集合。 集群为整个数据提供跨所有节点的集合索引和搜索功能。
分片 shards
索引被水平细分为分片。这意味着每个分片包含文档的所有属性,但包含的数量比索引少。水平分隔使分片成为一个独立的节点,可以存储在任何节点中。主分片是索引的原始水平部分,然后这些主分片被复制到副本分片中。
一个分片是一个底层的工作单元,它仅保存全部数据中的一部分,它是一个Lucence实例 (一个lucene索引最大包含2,147,483,519 (= Integer.MAX_VALUE - 128)个文档数量)
副本 replicas
Elasticsearch允许用户创建其索引和分片的副本。用于保障数据安全与分担检索压力。
索引 index
它是不同类型的文档和文档属性的集合。索引还使用分片的概念来提高性能。
类型/映射 type
它是共享同一索引中存在的一组公共字段的文档的集合。
文档 document
它是以JSON格式定义的特定方式的字段集合。每个文档都属于一个类型并驻留在索引中。每个文档都与唯一标识符(称为UID)相关联。
数据恢复 recovery
代表数据恢复或叫数据重新分布,节点加入或退出时会根据负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
数据源River
从其它存储方式(如:数据库)同步数据到es的一个方法,读取river中的数据并把它索引到es。
网关 gateway
持久化存储方式索引存放到内存中,当内存满了时再持久化到硬盘。
3.ElasticSearch 与 MySQL 的相关术语比较
|
ElasticSearch |
MySQL |
|
索引Index |
数据库Database |
|
类型Type [7.0 可不用,8.0废弃] |
表Table |
|
文档 |
记录(行)row |
|
字段Field |
数据列Column |
|
映射Mapping |
模式Schema |
|
Query DSL(查询专用语言) |
SQL(结构化查询语言) |
4、基本原理及架构
① ES集群的简单结构

② ElasticSearch 架构图
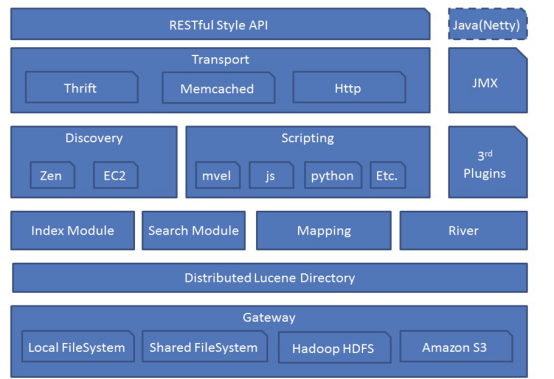
解释:
Gateway代表ElasticSearch索引的持久化存储方式。在Gateway中,ElasticSearch默认先把索引存储在内存中,然后当内存满的时候,再持久化到Gateway里。当ES集群关闭或重启的时候,它就会从Gateway里去读取索引数据。比如LocalFileSystem和HDFS、AS3等。
Distributed Lucene Directory,它是Lucene里的一些列索引文件组成的目录。它负责管理这些索引文件。包括数据的读取、写入,以及索引的添加和合并等。
River,代表是数据源。是以插件的形式存在于ElasticSearch中。
Mapping,映射的意思,非常类似于静态语言中的数据类型。声明存储数据类型, 如何来索引数据,以及数据是否被索引到等。
Search Moudle,搜索模块
Index Moudle,索引模块
Disvcovery,主要是负责集群的master节点发现。比如某个节点突然离开或进来的情况,进行一个分片重新分片等。这里有个发现机制。发现机制默认的实现方式是单播和多播的形式,即Zen,同时也支持点对点的实现。另外一种是以插件的形式,即EC2。
Scripting,即脚本语言。包括很多,这里不多赘述。如mvel、js、python等。
Transport,代表ElasticSearch内部节点,代表跟集群的客户端交互。包括 Thrift、Memcached、Http等协议
RESTful Style API,通过RESTful方式来实现API编程。
3rd plugins,代表第三方插件。
Java(Netty),是开发框架。
JMX,是监控。