Consumer实例,并指定相关配置项,有了这个实例对象后我们才能进行其他的操作。代码示例:/** * 创建Consumer实例 */ public static KafkaConsumer<String, String> createConsumer() { HashMap<String, Object> conf = Maps.newHashMap(); // 指定Kafka服务的ip地址及端口号 conf.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.182.128:9092"); // 指定消息key的序列化器 conf.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // 指定消息value的序列化器 conf.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); // 是否开启自动提交 conf.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true"); // 自动提交的间隔,单位毫秒 conf.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000"); // 指定 GroupId,Kafka中的消费者需要在消费者组里 conf.put(ConsumerConfig.GROUP_ID_CONFIG, "test"); return new KafkaConsumer<>(conf); }
在以上代码中,可以看到设置了group.id这个配置项,这是一个Consumer的必要配置项,因为在Kafka中,Consumer需要位于一个Consumer Group里。具体如下图所示:
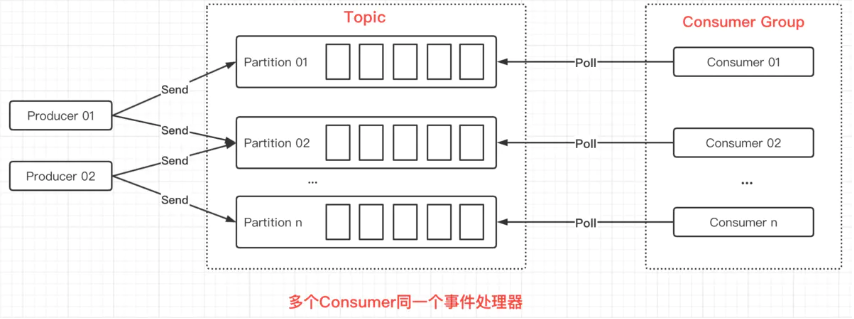
在上图中是一个Consumer消费一个Partition,是一对一的关系。但Consumer Group里可以只有一个Consumer,此时该Consumer可以消费多个Partition,是一对多的关系。如下图所示:

Consumer可以只消费一个Partition,也可以消费多个Partition,但需要注意的是多个Consumer不能消费同一个Partition:

总结一下Consumer的注意事项:
- 单个
Partition的消息只能由Consumer Group中的某个Consumer来消费 Consumer从Partition中消费消息是顺序的,默认从头开始消费- 如果Consumer Group中只有一个
Consumer,那么这个Consumer会消费所有Partition中的消息
在Kafka中,当消费者消费数据后,需要提交数据的offset来告知服务端成功消费了哪些数据。然后服务端就会移动数据的offset,下一次消费的时候就是从移动后的offset位置开始消费。
这样可以在一定程度上保证数据是被消费成功的,并且由于数据不会被删除,而只是移动数据的offset,这也保证了数据不易丢失。若消费者处理数据失败时,只要不提交相应的offset,就可以在下一次重新进行消费。
和数据库的事务一样,Kafka消费者提交offset的方式也有两种,分别是自动提交和手动提交。在本例中演示的是自动提交,这也是消费数据最简单的方式。自动提交需要在创建 Consumer 实例的时候增加如下配置:
// 是否开启自动提交 conf.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
代码如下:
/** * 消费者消费消息,自动提交 */ public static void autoCommitOffset(List<String> topicNames) { // 创建consumer实例 KafkaConsumer<String, String> consumer = createConsumer(); // 订阅一个或多个Topic consumer.subscribe(topicNames); // 轮循处理消息 while (true) { // 从Topic中拉取数据,每1000毫秒拉取一次 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); // 将records转换为可迭代对象 Iterator<ConsumerRecord<String, String>> recordIterator = records.iterator(); // 将数据遍历出来 while (recordIterator.hasNext()) { ConsumerRecord<String, String> record = recordIterator.next(); System.out.printf("topic = %s, key = %s, val = %s ", record.topic(), record.key(), record.value()); } } }
二、Consumer 手动提交
// 关闭自动提交 conf.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
关闭自动提交后,就得在代码中调用commit相关的方法来提交offset,主要就是两个方法:commitAsync和commitSync,看方法名也知道一个是异步提交一个是同步提交。这里以commitAsync为例,实现思路主要是在发生异常的时候不要调用commitAsync方法,而在正常执行完毕后才调用commitAsync方法。代码示例:
/** * 手动提交,适合一些特定的业务场景 * 比如:数据存入数据库成功则提交,失败则重新对这条数据进行消费 * 这样不会丢失消息 */ public static void manualCommitOffset(List<String> topicNames) { // 创建consumer实例 KafkaConsumer<String, String> consumer = createConsumer(); // 订阅一个或多个Topic consumer.subscribe(topicNames); // 轮训处理消息 while (true) { // 从Topic中拉取数据,每1000毫秒拉取一次 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000)); // 将records转换为可迭代对象 Iterator<ConsumerRecord<String, String>> recordIterator = records.iterator(); // 将数据遍历出来 while (recordIterator.hasNext()) { ConsumerRecord<String, String> record = recordIterator.next(); try { // 模拟将数据写入数据库 Thread.sleep(1000); System.out.println("save to db..."); System.out.printf("topic = %s, key = %s, val = %s ", record.topic(), record.key(), record.value()); } catch (Exception e) { // 写入失败则不要调用commit,这样就相当于起到回滚的作用, // 下次消费还是从之前的offset开始消费 e.printStackTrace(); } } // 写入成功则调用commit相关方法去手动提交offset consumer.commitAsync(); } }
三、SpringBoot 集成 Kafka
implementation('org.springframework.kafka:spring-kafka:2.4.3.RELEASE')
注意:该包的版本与 SpringBoot 版本有匹配性,此版本匹配 SpringBoot 的 2.2.x 的版本
2、配置 application.yml
server: port: 8899 spring: kafka: bootstrap-servers: 127.0.0.1:9092 producer: # 发生错误后,消息重发的次数。 retries: 0 #当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算。 batch-size: 16384 # 设置生产者内存缓冲区的大小。 buffer-memory: 33554432 # 键的序列化方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer # 值的序列化方式 value-serializer: org.apache.kafka.common.serialization.StringSerializer # acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。 # acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成功响应。 # acks=all :只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。 acks: 1 consumer: # 自动提交的时间间隔 在spring boot 2.X 版本中这里采用的是值的类型为Duration 需要符合特定的格式,如1S,1M,2H,5D auto-commit-interval: 1S # 该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下该作何处理: # latest(默认值)在偏移量无效的情况下,消费者将从最新的记录开始读取数据(在消费者启动之后生成的记录) # earliest :在偏移量无效的情况下,消费者将从起始位置读取分区的记录 auto-offset-reset: earliest # 是否自动提交偏移量,默认值是true,为了避免出现重复数据和数据丢失,可以把它设置为false,然后手动提交偏移量 enable-auto-commit: false # 键的反序列化方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 值的反序列化方式 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer listener: # 在侦听器容器中运行的线程数。 concurrency: 5 #listner负责ack,每调用一次,就立即commit ack-mode: manual_immediate missing-topics-fatal: false
3、Controller+主启动类


@SpringBootApplication public class KafukaSpringBootApplication { public static void main(String[] args) { SpringApplication.run(KafukaSpringBootApplication.class); } }
@RestController public class ProducerController { @Autowired private CommonProducer producer; @RequestMapping("/send") public String sendMsg(@RequestParam String msg){ producer.sendMsg(msg); return "success"; } }
4、新建 Producer
@Component @Slf4j public class CommonProducer { @Autowired private KafkaTemplate<String, String> kafkaTemplate; public void sendMsg(String msg) { ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send(KafkaConst.TOPIC_NAME, msg); future.addCallback(new ListenableFutureCallback<SendResult<String, String>>() { @Override public void onSuccess(SendResult<String, String> result) { log.info("producer send success result = {}", result.toString()); } @Override public void onFailure(Throwable throwable) { log.info("producer send failed. msg={}", throwable.getMessage()); } }); } }
5、新建 Consumer
@Slf4j @Component public class CommonConsumer { @KafkaListener(topics = KafkaConst.TOPIC_NAME, groupId = KafkaConst.GROUP_ONE) public void consumeForGroupOne(ConsumerRecord<String, String> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) { Optional<String> msgOptional = Optional.ofNullable(record.value()); if (msgOptional.isPresent()) { Object msg = msgOptional.get(); log.info("consumeForGroupOne start: topic={}, msg={}", topic, msg); ack.acknowledge(); } } @KafkaListener(topics = KafkaConst.TOPIC_NAME, groupId = KafkaConst.GROUP_TWO) public void consumeForGroupTwo(ConsumerRecord<String, String> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) { Optional<String> msgOptional = Optional.ofNullable(record.value()); if (msgOptional.isPresent()) { Object msg = msgOptional.get(); log.info("consumeForGroupTwo start: topic={}, msg={}", topic, msg); ack.acknowledge(); } } }
6、设置 Topic名和 GroupId
public interface KafkaConst { String TOPIC_NAME = "hello-kafka"; String GROUP_ONE = "test-group1"; String GROUP_TWO = "test-group2"; }
通过 HTTP 请求,我们就可以在控制台看到消息生产和发送的信息了,如下图所示:
