什么是包?
包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来。
需要强调的是:
1.在python3中,即使包下没有__init__.py文件,import包仍然不会报错,而在python2中,包下一定要有该文件,否则import包会报错。
2.创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块
为什么要使用包
包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起来,随着功能越写越多,我们无法将所以功能都放到一个文件中,于是我们使用模块去组织功能,而随着模块越来越多,我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性
注意事项:
包的相关导入也分为import和from...import...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边必须都是一个包,否则非法。
首次导入包:
先产生一个执行文件的名称空间
1.创建包下面的__init__.py文件的名称空间
2.执行包下面的__init__.py文件中的代码 将产生的名字放入包下面的__init__.py文件名称空间中
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
站在包的开发者: 如果使用绝对路径来管理自己的模块 那么它只需要永远以包的路径为基准依次导入模块
站在包的使用者: 你必须将包所在的那个文件夹路径添加到system path(中)
logging模块
日志模块:记录
日志分为五个等级
logging.debug() #10
logging.info() #20
logging.warning() #30
logging.error() #40
logging.critical() #50
1.logger对象:负责产生日志
2.filter对象:过滤日志(了解)
3.handler对象:控制日志输出的位置(文件/终端)
4.formmater对象:规定日志内容的格式
logging配置字典


import os import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' # 定义日志输出格式 结束 下面的两个变量对应的值 需要你手动修改 logfile_dir = os.path.dirname(__file__) # log文件的目录 logfile_name = 'a3.log' # log文件名 # 如果不存在定义的日志目录就创建一个 if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) # log文件的全路径 logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, # 过滤日志 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, # 当键不存在的情况下 默认都会使用该k:v配置 }, } # 使用日志字典配置 logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger('asajdjdskaj') logger1.debug('好好的 不要浮躁 努力就有收获')
hashlib模块
hashlib模块 加密的模块
import hashlib #传入的内容 可以分多次传入 只要传入的内容相同 那么生成的密文肯定相同 md = hashlib.md5() md.update(b'nihaoma') md.update(b'ni') md.update(b'hao') md.update(b'ma') print(md.hexdigest()) hashlib模块的应用场景 1.密码的密文存储 2.校验文件内容是否一致
1.不同的算法 使用方法是相同的
密文的长度越长 内部对应的算法越复杂
但是
1.时间消耗越长
2.占用空间更大
通常情况下使用md5算法 就可以足够了
加盐处理
加盐处理 import hashlib md = hashlib.md5() 公司自己在每一个需要加密的数据之前 先手动添加一些内容 md.update(b'oldboy.com') # 加盐处理 md.update(b'hello') # 真正的内容 print(md.hexdigest()) 动态加盐 import hashlib def get_md5(data): md = hashlib.md5() md.update('加盐'.encode('utf-8')) md.update(data.encode('utf-8')) return md.hexdigest() password = input('password>>:') res = get_md5(password) print(res)
openpyxl 比较火的操作Excel表格的模块
03版本之前 excel文件的后缀名 叫xls
03版本之后 excel文件的后缀名 叫xlsx
xlwd 写excel
xlrt 读excel
xlwd和xlrt既支持03版本之前的excel文件也支持03版本之后的excel文件
openpyxl 只支持03版本之后的 xlsx
写 from openpyxl import Workbook wb = Workbook() # 先生成一个工作簿 wb1 = wb.creat_sheet('index',0) # 创建一个表单页 后面可以通过数字控制位置 wb1.title = 'login' #后期可以通过表单页对象点title修改表单名称 wb1['A3'] = 666 wb1['A4'] = 555 wb1.cell(row=6,column=3,value=88888) wb1[A5'] = '=sum(A3:A4)' wb1.append(['username','age','hobby']) wb1.append(['jason',18,'study']) wb1.append(['tank',72,'吃生蚝']) 保存新建的文件 wb.save('test.xlsx') from openpyxl import load_workbook #读文件 wb = load_work('test.xlsx',read_only=True,data_only=True) print(wb) print(wb.sheetnames) # ['login', 'Sheet', 'index1'] print(wb['login']['A3'].value) print(wb['login']['A4'].value) print(wb['login']['A5'].value) # 通过代码产生的excel表格必须经过人为操作之后才能读取出函数计算出来的结果值
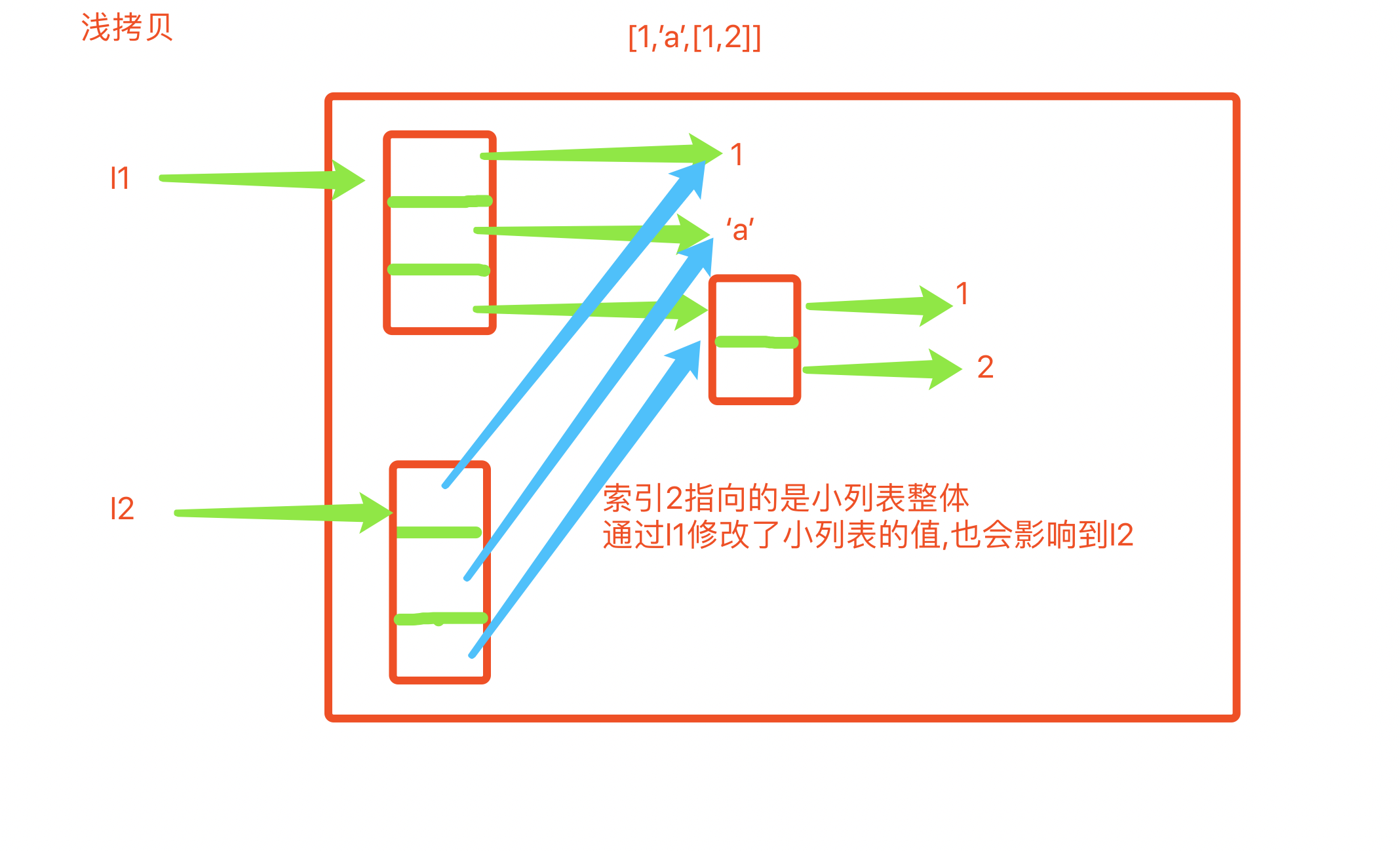
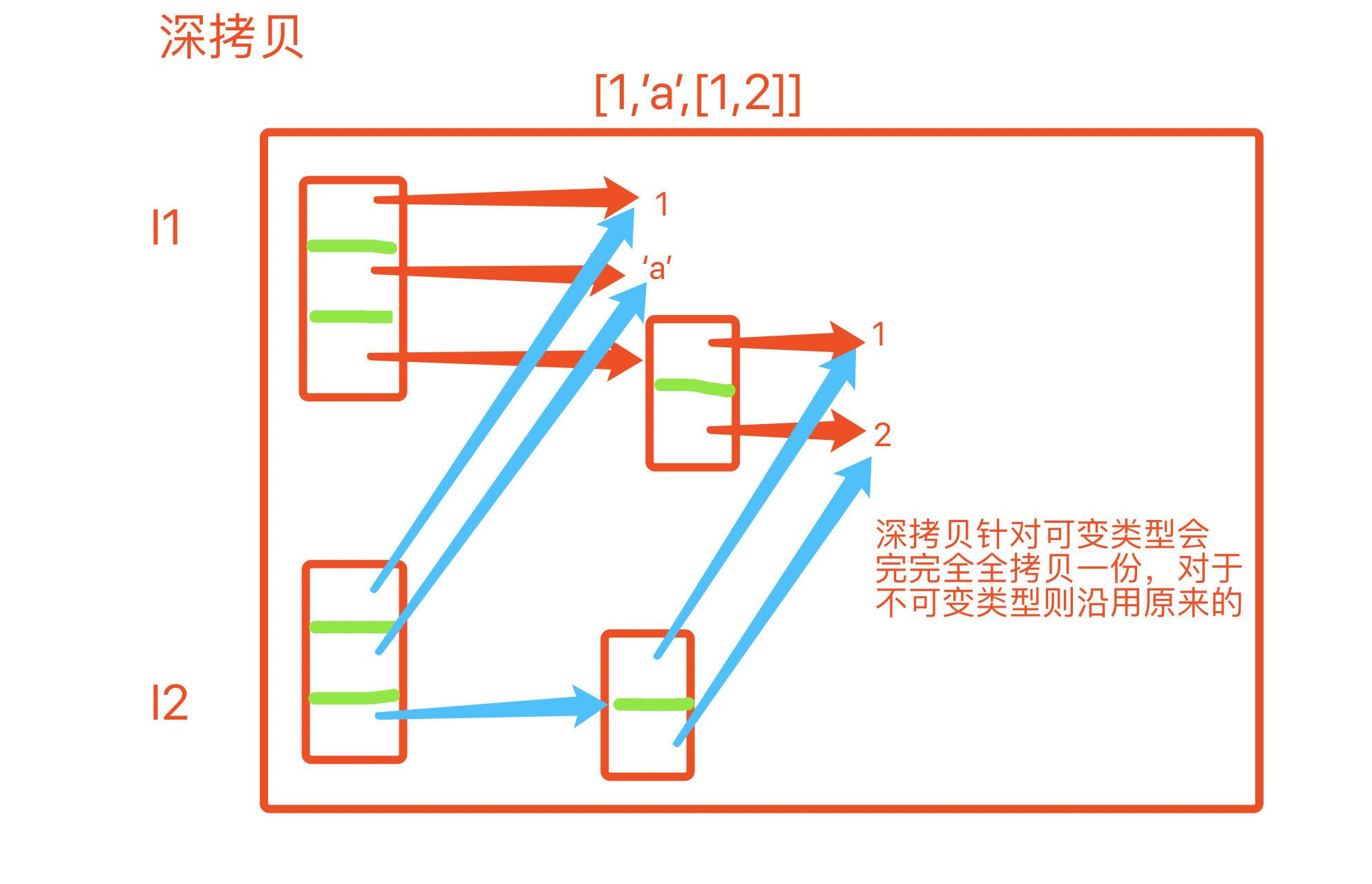
深浅拷贝
l = [1,2,[1,2]] # l1 = l # print(id(l),id(l1)) # l1 = copy.copy(l) # 拷贝一份 ....... 浅拷贝 # print(id(l),id(l1)) # # l[0] = 222 # # print(l,l1) # l[2].append(666) # print(l,l1) l1 = copy.deepcopy(l) l[2].append(666) print(l,l1)