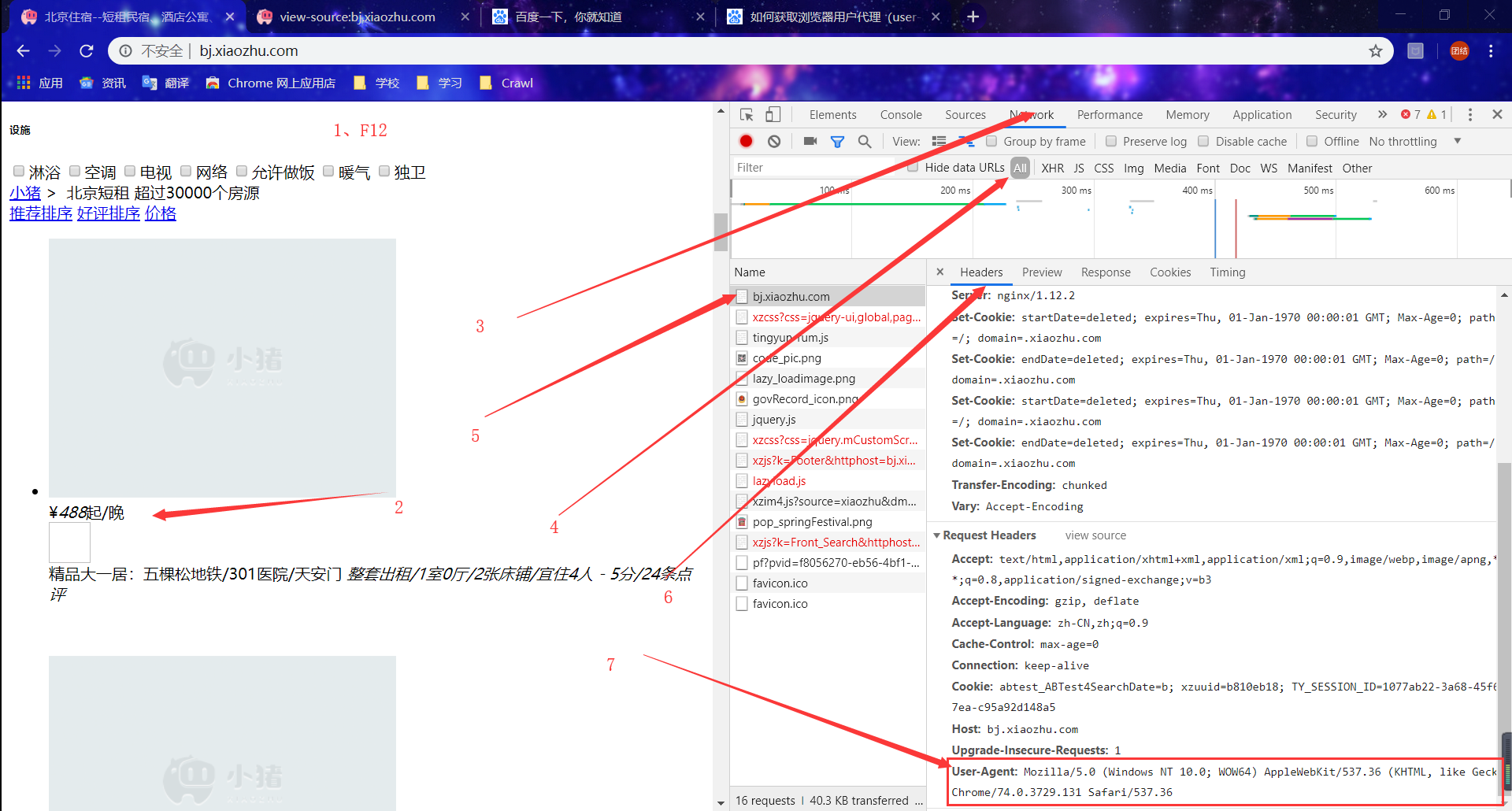
在开发工具内获取“请求头”来伪装成浏览器,以便更好地抓取数据
!/usr/bin/env python -*- encoding:UTF-8 -*- import requests headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' } res = requests.get('http://bj.xiaozhu.com/',headers=headers) # get方法加入请求头 try: print(res.text) except ConnectionError: print('拒绝连接') # 通过BeautiSoup库解析得到的Soup文档是标准结构化数据比上面的更好 import requests from bs4 import BeautifulSoup headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' } res = requests.get('http://bj.xiaozhu.com/',headers=headers) # get方法加入请求头 try: soup = BeautifulSoup(res.text, 'html.parser') print(soup.prettify()) except ConnectionError: print('拒绝连接')
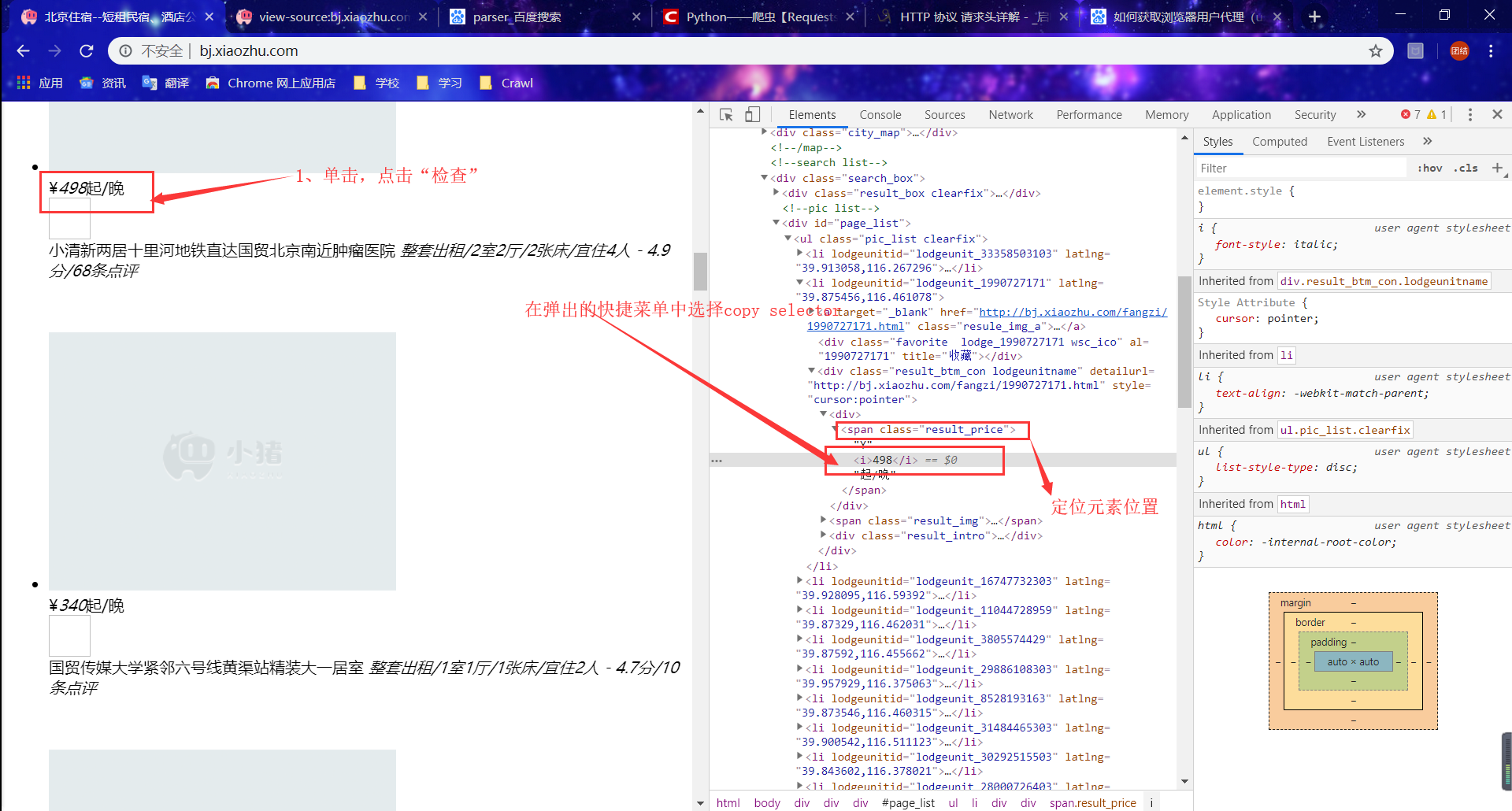

更新后:
price = soup.select('#page_list > ul > li:nth-child(1) > div.result_btm_con.lodgeunitname > div:nth-child(1) > ' 'span.result_price > i')
完整代码
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 ' 'Safari/537.36 ' } res = requests.get('http://bj.xiaozhu.com/', headers=headers) # get方法加入请求头 soup = BeautifulSoup(res.text, 'html.parser') # 定位元素位置并通过selector方法提取 prices = soup.select( '#page_list > ul > li > div.result_btm_con.lodgeunitname > div:nth-child(1) > span.result_price > i') for price in prices: print(price.get_text())
# print(prince) 带有标签
爬取北京地区短租房信息:
import random import requests from bs4 import BeautifulSoup import time # 加入请求头伪装成浏览器 headers = { # 通过Chrome浏览器复制User-Agent 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36' } # 定义判断用户性别的函数 def judgment_sex(class_name): if class_name == ['member_ico1']: return '女' else: return '男' # 获取详细页URL函数 def get_links(url): try: wb_date = requests.get(url, headers) except ConnectionAbortedError: print('拒绝连接') soup = BeautifulSoup(wb_date.text, 'lxml') links = soup.select('#page_list > ul > li > a') for link in links: herf = link.get("href") get_info(herf) # 获取网页信息函数 def get_info(url): wb_date = requests.get(url, headers) soup = BeautifulSoup(wb_date.text, 'lxml') # 通过浏览器copy selector tittles = soup.select('div.pho_info > h4') addresses = soup.select('span.pr5') prises = soup.select('#pricePart > div.day_l > span') images = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img') names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h6 > a') sexs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div') for tittle, address, prise, image, name, sex in zip(tittles, addresses, prises, images, names, sexs): date = { 'tittle': tittle.get_text().strip(), 'address': address.get_text().strip(), 'price': prise.get_text(), 'image': image.get("src"), 'name': name.get_text(), 'sex': judgment_sex(sex.get("class")) } print(date) if __name__ == '__main__': urls = ['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in range(1, 14)] for single_url in urls: get_links(single_url) # 休眠十秒,防止被封IP time.sleep(random.randint(10, 13)) # 缺点:缺少IP管理,采用休眠方法,效率低
爬取酷狗top1.0版:
#!/usr/bin/env python # -*- encoding:UTF-8 -*- from bs4 import BeautifulSoup import requests import time,random headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' } def get_info(url): """获取信息函数""" wb_data = requests.get(url,headers) soup = BeautifulSoup(wb_data.text,'lxml') ranks = soup.select('span.pc_temp_num') titles =soup.select('div.pc_temp_songlist>ul>li>a') times = soup.select('span.pc_temp_tips_r>span') for rank,title,time in zip(ranks,titles,times): data = { 'rank':rank.get_text().strip(), 'singer':title.get_text().split('-')[0], 'song':title.get_text().split('-')[1], 'time':time.get_text().strip() } print(data) if __name__ == '__main__': """主程序入口""" urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html'.format(i) for i in range(1,25)] for url in urls: get_info(url) time.sleep(random.randint(3,5))
爬取酷狗top1.1版:
#!/usr/bin/env python # -*- encoding:UTF-8 -*- from bs4 import BeautifulSoup import requests import time,random headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36' } def get_info(url): """获取信息函数""" wb_data = requests.get(url,headers) soup = BeautifulSoup(wb_data.text,'lxml') ranks = soup.select('span.pc_temp_num') titles =soup.select('a.pc_temp_songname') times = soup.select('span.pc_temp_time') for rank,title,time in zip(ranks,titles,times): data = { 'rank':rank.get_text().strip(), 'singer':title.get_text().split('-')[0], 'song':title.get_text().split('-')[1], 'time':time.get_text().strip() } print(data) if __name__ == '__main__': """主程序入口""" urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html'.format(i) for i in range(1,25)] for url in urls: get_info(url) time.sleep(random.randint(3,5))
爬取价格:
import re import requests res = requests.get('http://bj.xiaozhu.com/') prices = re.findall('<span class="result_price">¥<i>(.*?)</i>起/晚</span>', res.text) for price in prices: print(price)
注意:
<span class="result_price">¥<i>488</i>起/晚</span>
¥ 和 ¥等价,但爬取时,不能出现¥