Date过滤
input {
stdin{
codec => plain
}
}
filter {
date {
match => ["message", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
}
}
output{
stdout{
codec => rubydebug{
}
}
}
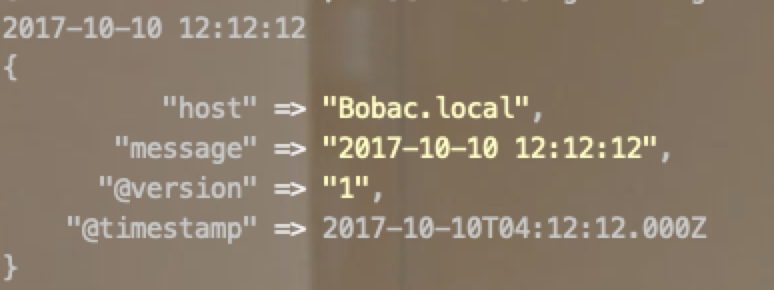
# target是覆盖写那个目标字段
# match 是匹配什么样子的
# 注意时区的时差
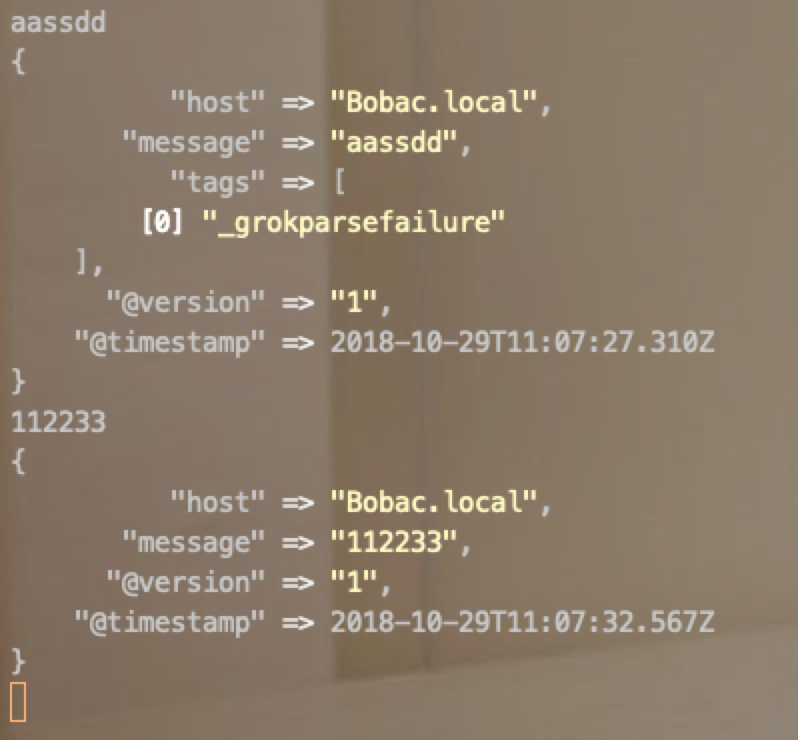
正在表达式grok
input {
stdin{
codec => plain
}
}
filter {
grok {
match => {"message" => "dddddd"}
}
}
output{
stdout{
codec => rubydebug{
}
}
}
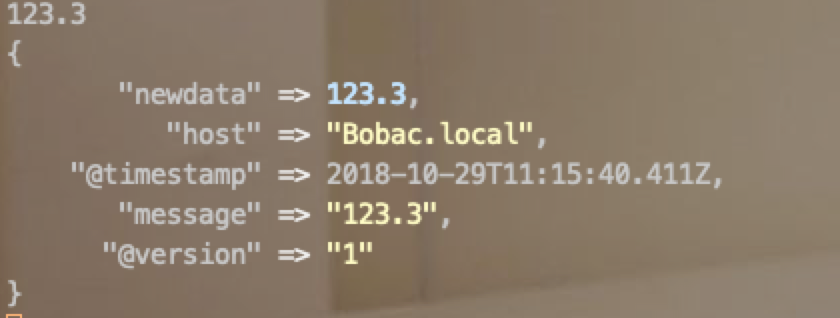
# 输出的数据类型转换(Number目前只支持float和int):
filter {
grok {
match => {
"message => "%{WORD} %{NUMBER:newdata:float} %{WORD}"
}
}
}
# 重写字段:
overwrite => ["message"]

input {
stdin{
codec => plain
}
}
filter {
grok {
match => {"message" => "%{WORD:message:text} %{NUMBER:data:float}"}
overwrite => ["message"]
}
}
output{
stdout{
codec => rubydebug{
}
}
}
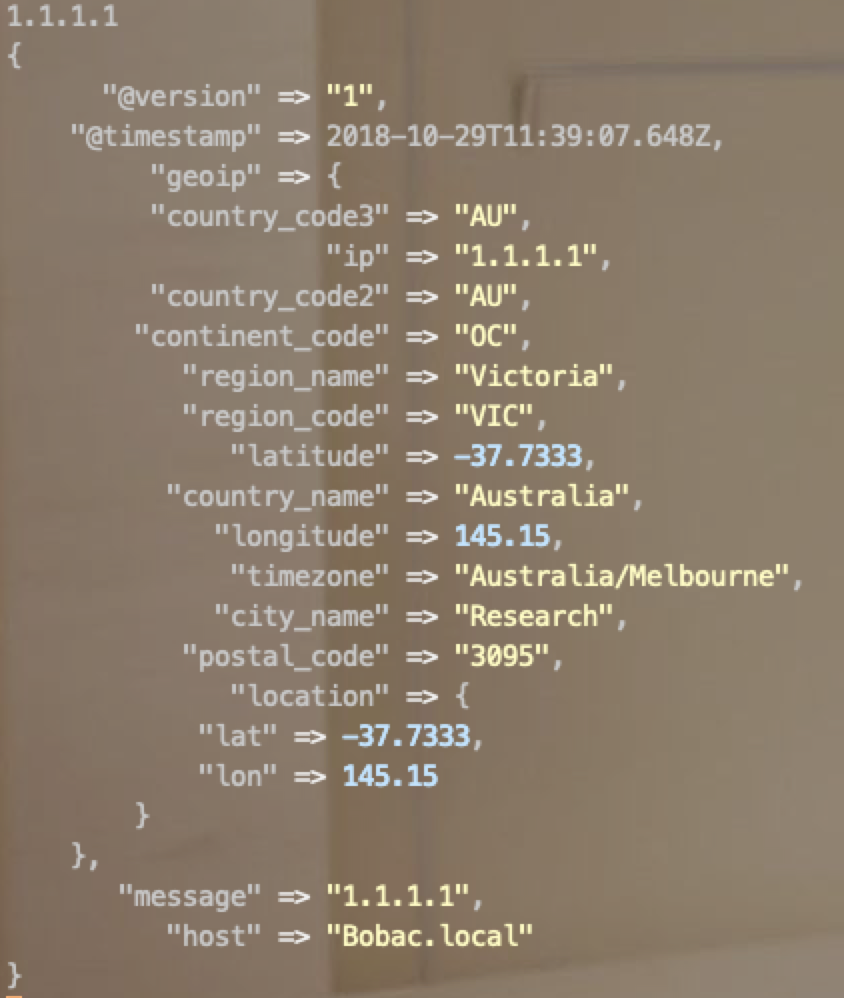
GeoIP地址查询
filter {
geoip {
source => "message"
}
}
JSON编码
filter{
json {
source => "message"
target => "jsoncontent"
}
}
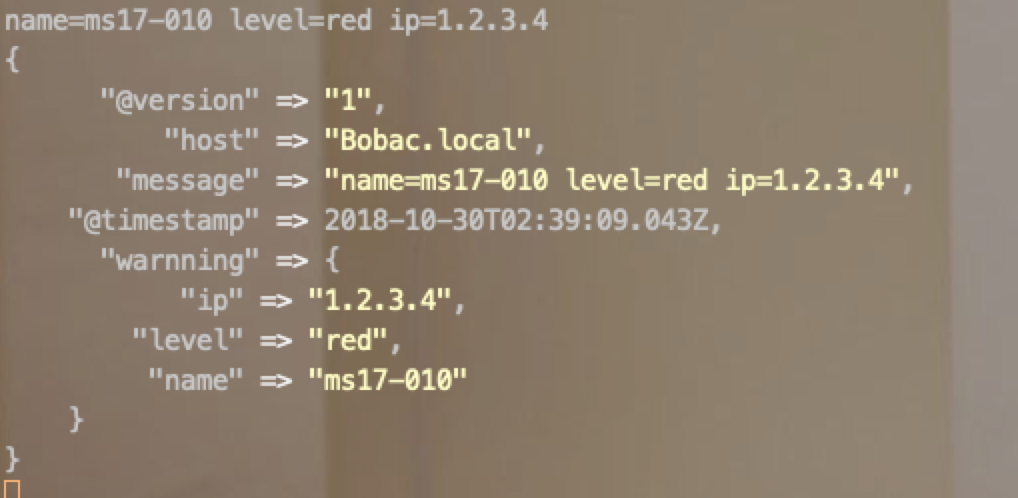
key-value切分
input {
stdin{
codec => plain
}
}
filter {
kv {
source => "message"
include_keys => ["name","ip","level"]
target => warnning
}
}
output{
stdout{
codec => rubydebug{
}
}
}
数据修改
#总格式
filter {
mutate {
...
}
}
#1、字符串处理
mudate {
gsub => ["xxx", "yyy","zzz"] #替换xxx字段中的yyy为zzz
split => ["xxx","yyy"] #把xxx字段按照yyy字符分割
join => ["xxx","yyy"] #把xxx字段按照yyy组装,之前分割的东西,用yyy作为分隔符,组装到一起
merge => ["xxx","yyy"] #合并xxx和yyy字段
strip => ["xxx"] #去掉xxx字段的前后空格
lowercase/uppercase => xxx #小写/大写
rename => ["xxx","yyy"] #xxx字段的名字换成yyy
update => ["xxx","xxx"] #更新字段,字段不存在不新建
replace => ["xxx","yyy"] #更新字段,字段不存在则新建
}