上一篇是基于内存存储的,这次的例子是基于本地存储索引库。
上一次的代码稍微修改,代码如下:
//创建词法分析器 Analyzer analyzer = new StandardAnalyzer(); //索引库路径 Path path = new File("D:\123").toPath(); //确定索引文件的位置,方式如下为 本地文件存储 Directory directory = FSDirectory.open(path); //索引文件的写入 IndexWriterConfig config = new IndexWriterConfig(analyzer); IndexWriter iwriter = new IndexWriter(directory, config); //目标资源文件 File docFile = new File("F:\API文档"); for(File f : docFile.listFiles()){ Document document = new Document(); System.out.println("path------"+f.getPath()); Field field = new Field("path", f.getPath(),TextField.TYPE_STORED); document.add(field); iwriter.addDocument(document); } iwriter.close(); System.out.println("----"); //索引目录流对象创建 DirectoryReader ireader = DirectoryReader.open(directory); //创建搜索对象 IndexSearcher isearcher = new IndexSearcher(ireader); //查询解析器,第一个参数是默认的搜索域 QueryParser parser = new QueryParser("path", analyzer); Query query = parser.parse("Java"); //模糊查询 Term term = new Term("path","Java"); FuzzyQuery fuzzyQuery=new FuzzyQuery(term); //执行搜索,取前一百条符合记录的数据 TopDocs top = isearcher.search(fuzzyQuery, 100); ScoreDoc[] hits = top.scoreDocs; System.out.println(hits.length); for (int i = 0; i < hits.length; i++) { Document hitDoc = isearcher.doc(hits[i].doc); System.out.println("[Document="+hitDoc+",file:"+hitDoc.get("path")+"]."); System.out.println("查询出的结果是:"+hitDoc.get("path")); } ireader.close(); directory.close();
运行结果如下:
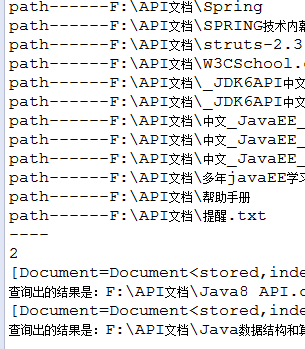
代码执行,会在所指的本地索引目录下生成索引文件:
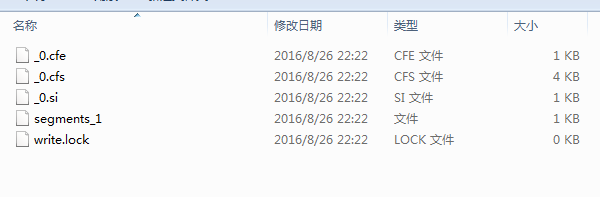
注意:程序每执行一次就会重复增加索引文件进去,会出现重复搜索结果,所以将来肯定是用定时器去生成索引的。
将来使用到Luence,会实际业务需求需要怎么使用,就要具体情况具体分析了,万变不离其宗,总是用到最基础的那些东西。
如有不正确之处,欢迎指正。