1.PUT创建一个资源
1.2创建一个索引 my_index1
PUT /my_index1 { "settings": { "number_of_shards" : 1, "number_of_replicas" : 1 } }
- my_index:为索引名称(相当于数据库的表)
- doc :为索引的类型,可自己指定名称。
- dynamic:用于配置动态映射,当插入数据的时候遇上如果数据库字段中有,索引中没有的字段,以下三种设定值会起到不同的效果true:动态添加新的字段–缺省false:忽略新的字段(正常插入数据)strict:如果遇到新字段抛出异常设置分片number_of_shards:每个索引的主分片数,默认值是 5 。这个配置在索引创建后不能修改。number_of_replicas:每个主分片的副本数,默认值是 1 。对于活动的索引库,这个配置可以随时修改。
- id,name,sex,title,city:分别为字段名称(可根据自己的需求创建多个字段)
类型为text时表示需要对该字段进行分词, analyzer类型为keyword时表示不需要对该字段进行分词
1.3 索引下添加文档 (类似于数据库中添加一条记录),指定id,id存在则修改,版本加1,不存在就多新加一条,
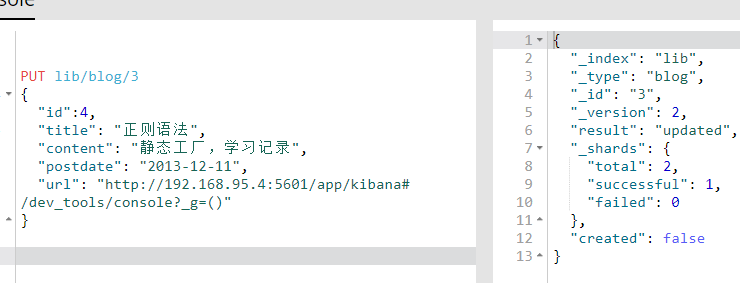
PUT lib/blog/3 { "id":4, "title": "正则语法", "content": "静态工厂,学习记录", "postdate": "2013-12-11", "url": "http://192.168.95.4:5601/app/kibana#/dev_tools/console?_g=()" }
1.4不指定id(自动生成id)
POST lib/blog/ { "id":4, "title": "正则语法", "content": "静态工厂,学习记录", "postdate": "2013-12-11", "url": "http://192.168.95.4:5601/app/kibana#/dev_tools/console?_g=()" }




2.POST修改或跟新一个资源
PUT lib/blog/2 { "id":4, "title": "python", "content": "静态工厂,学习记录", "postdate": "2013-12-11", "url": "http://192.168.95.4:5601/app/kibana#/dev_tools/console?_g=()" }

POST lib/blog/AW7pP_hpSp_vcrhFE-fx/_update { "doc":{ "title": "正则语法+使用" } }

3.DELETE删除一个资源
3.1.1 根据索引名称删除索引 DELETE my_index 3.1.2 删除my_index索引下user类型中Id等于1的文档
DELETE my_index/user/1
4.1.1 索引名称查看索引信息
get my_index1
4.1.2 查询my_index索引的user类型下的所有文档,默认情况下搜索会返回前10个结果。
get my_index/user/_search
4.1.3 根据ID去查询文件
get my_index/user/AW4QUmvsPVVF6o889z5Y
4.1.3 查看文件的部分属性
get my_index/user/AW4QUmvsPVVF6o889z5Y?_source=name,age
4.1.4 查看my_index索引的user类型下所有文件中name属性叫Helen的
GET my_index/user/_search?q=name:Helen
4.1.5 查看所有索引
get _allget *
4.1.6 查看my_index1索引的配置
get my_index1/_settings
GET /_mget { "docs":[ { "_index":"lib", "_type":"blog", "_id":2 }, { "_index":"lib1", "_type":"books", "_id":"AW7ZNiloC3UFf3ScjnLI" } ] }
GET /_mget { "docs":[ { "_index":"lib", "_type":"blog", "_id":2, "_source":["title","content","postdate"] }, { "_index":"lib1", "_type":"books", "_id":"AW7ZNiloC3UFf3ScjnLI", "_source":["title","price","date"] } ] }
GET lib/blog/_mget { "docs":[ {"_id":2}, {"_id":3} ] }
GET lib/blog/_mget { "ids":[2,3] }
bulk允许在一个请求中进行多个操作(create、index、update、delete),也就是可以在一次请求裡做很多事情
也由于这个关系,因此bulk的请求体和其他请求的格式会有点不同
5.1bulk的请求模板
分成action、metadata和doc三部份
action : 必须是以下4种选项之一
index(最常用) : 如果文档不存在就创建他,如果文档存在就更新他
create : 如果文档不存在就创建他,但如果文档存在就返回错误
使用时一定要在metadata设置_id值,他才能去判断这个文档是否存在
update : 更新一个文档,如果文档不存在就返回错误
使用时也要给_id值,且后面文档的格式和其他人不一样
delete : 删除一个文档,如果要删除的文档id不存在,就返回错误
使用时也必须在metadata中设置文档id,且后面不能带一个doc,因为没意义,他是用id去删除文档的
metadata : 设置这个文档的metadata,像是id、index、_type...
doc : 就是一般的文档格式
POST 127.0.0.1/mytest/doc/_bulk { action : { metadata } } { doc } { action : { metadata } } { doc } ....
POST my_index/books/_bulk {"index":{"_id":1}} {"title":"java","price":35} {"index":{"_id":2}} {"title":"HTML5","price":45} {"index":{"_id":3}} {"title":"php","price":25} {"index":{"_id":4}} {"title":"python","price":28}5.2.1.批量查询
GET my_index/books/_mget { "ids":[1,2,3,4 ] }
5.3批量操作
POST my_index/books/_bulk {"delete":{"_ index":"my_index","_ type":"books","_id":4}} {"create":{"_ index":"tt","_ type":"ttt","_id":100}} {"name":"lisi"} {"index":{"_ index":"tt","_type":"ttt"}} {"name":"zhaosi"} {"update":{"_ index":"my_index","t ype":"books","id":4}} {"doc":{"price":58}}5.4bulk一次能处理多大的数据量
bulk把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂你的素引以及搜索的负载。
一般议是1000-5000个文档,大小建议是5-15MB,默认不超过100M,可以在es的配文件
( $ES HOME下的 config下的elasticsearch yml)中




