一、基本概念
哈希:哈希是一种查找算法,在关键字和元素的存储地址之间建立一个确定的对应关系,每个关键字对应唯一的存储地址,这些存储地址构成了有限、连续的存储地址。
哈希函数:在关键字和元素的存储地址之间建立确定的对应关系的函数。
哈希表是一种利用哈希函数组织数据,支持快速插入和搜索的数据结构。
哈希函数步骤:
-
1.散列:将关键字映射到hashcode(.Net中为一个int类型的值),要求尽可能的平均分布,减少冲突
-
2.映射:将及其分散的hashcode转换为有序、连续的存储地址
哈希冲突的原因:
-
1.将关键字散列为特定长度的整数值时,产生冲突
-
2.在除留余数法中,取余数时产生冲突。
1.构造哈希函数的要点:
1.1.运算过程简单高效,以提高哈希表的查找、插入效率
1.2.具有较好的散列性,以降低哈希冲突的概率
1.3.哈希函数应具有较大的压缩性,以节省内存
2.哈希函数构造方法:
2.1.直接定址法:
>>>>取关键字的某个线性函数值作为哈希地址: Hash(K)=α*GetHashCode(K)+C
优点:产生冲突的可能性较小 缺点:空间复杂度可能会很高,占用大量内存
2.2.除留余数法:
>>>>取关键字除以某个常数所得的余数作为哈希地址: Hash(K)=GetHashCode(K) MOD C。
该方法计算简单,适用范围广泛,是最经常使用的一种哈希函数。该方法的关键是常数的选取,一般要求是接近或等于哈希表本身的长度,理论研究表明,该常数取素数时效果最好
3.解决哈希冲突的方法:
3.1.开放定址法:它是一类以发生哈希冲突的哈希地址为自变量,通过某种哈希函数得到一个新的空闲内存单元地址的方法,开放定址法的哈希冲突函数通常是一组;
3.2.链表法:当未发生冲突时,则直接存放该数据元素;当冲突产生时,把产生冲突的数据元素另外存放在单链表中。
以上参考:
https://zhuanlan.zhihu.com/p/63142005、https://www.lmlphp.com/user/7277/article/item/355045/、http://www.nowamagic.net/academy/detail/3008050
二、从 Dictionary<TKey, TValue> 源码解读哈希表的构建
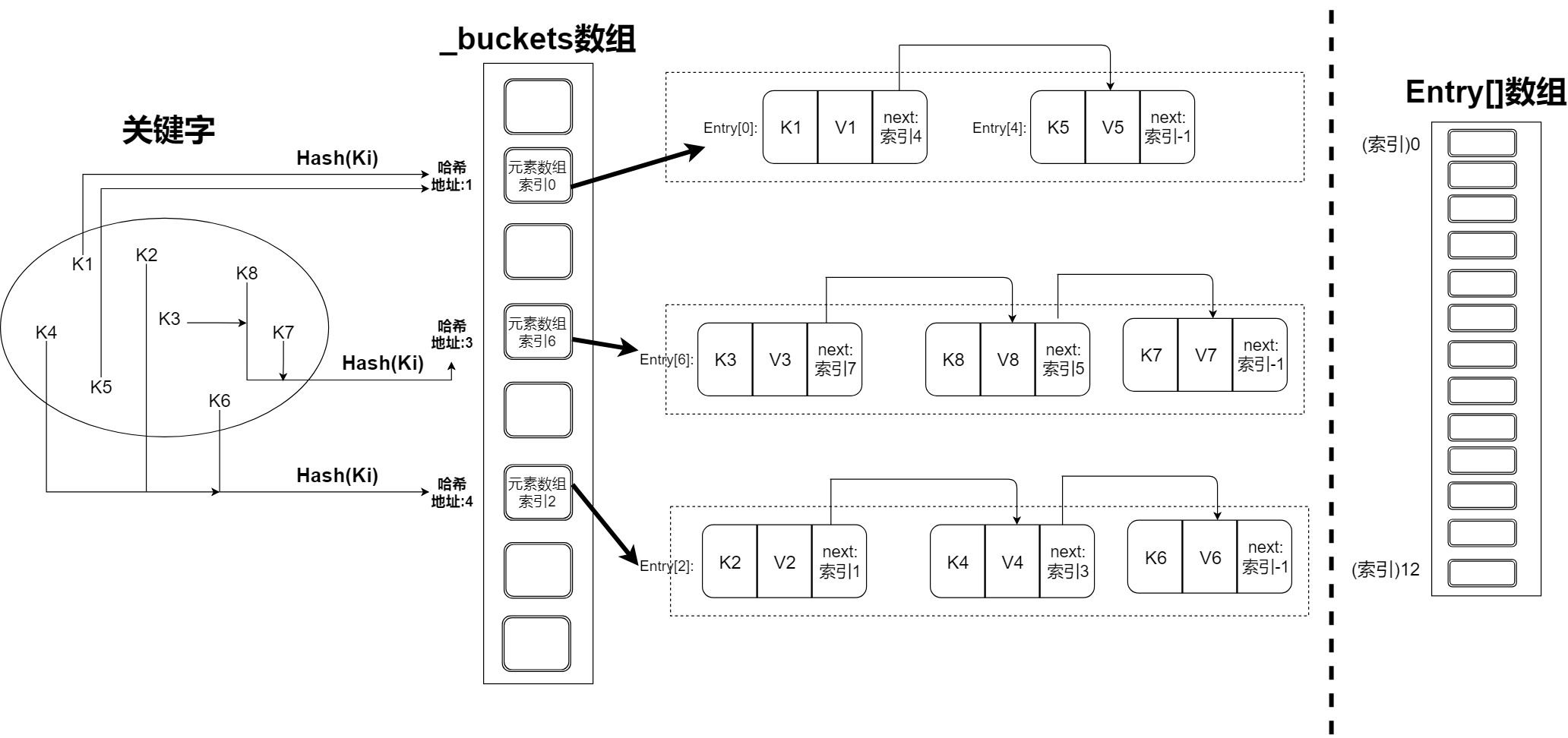
哈希表的关键思想:通过哈希函数将关键字映射到存储桶。存储桶是一个抽象概念,用于保存相同具有哈希地址的元素。
数组在所有编程语言中都是最基本的数据结构,实例化数组的时候,会在内存中分配一段连续的地址空间,用于保存同一类型的变量。对于哈希表来讲,数组就是实际存储元素的数据结构,数组索引就是其实际的存储地址,而哈希函数的功能就是将n个关键字唯一对应到到数组索引 0~m-1(m>=n)。为了兼顾性能,哈希函数是很难避免哈希冲突的,也就是说,没有办法直接将哈希地址作为元素的实际地址。
假设以下情况:
- 1.声明数组长度为13,现有8个元素需要插入到哈希表中,该8个元素对应的数组索引为[0]~[7] (实际存储地址)
- 2.通过哈希函数,可以将8个关键字映射到哈希地址(范围:0~20)
由于哈希冲突不可避免,如何通过哈希地址找到对应的实际存储地址?答案是通过数组在元素间构建单向链表来作为存储桶,将具有相同哈希地址的元素在保存在同一个存储桶(链表)中,并创建一个新的数组,数组长度为'哈希地址范围长度',该数组使用哈希地址作为索引,并保存链表的第一个节点的实际存储地址。下图展示了Dictionary<TKey, TValue> 中的实现。
了解了大概的原理之后,有两个问题需要解决:
1.如何通过数组构建单项链表:
自定义一个结构:其包含关键字、元素和next。Entry.next将具有相同哈希地址的元素构建为一个单向链表,Entry.next用于指向单向链表中的下一个元素所在的数组索引。通过哈希地址找到对应链表的第一个元素所在数组索引后,就可以找到整个单向链表,通过遍历链表对比关键字是否相等,来找到元素。
public class Dictionary<TKey, TValue>
{
private struct Entry
{
// 链表下一元素索引
// -1:链表结束
// -2:freeList链表结束
// -3:索引为0 属于freeList链表
// -4:索引为1 属于freeList链表
// -n-3:索引为n 属于freeList链表
public int next;
public uint hashCode;
public TKey key; // Key of entry
public TValue value; // Value of entry
}
private IEqualityComparer<TKey> _comparer;
//保存Entry链表第一个节点的索引,默认为零
//Entry实际索引=_buckets[哈希地址]-1
private int[] _buckets;
private Entry[] _entries;//组成了n+1个单向链表
//n:用于保存哈希值相同的元素
//1:用于保存已释放的元素
private int _freeCount;//已释放元素的个数
private int _freeList;//最新已释放元素的索引
private int _count;//数组中下一个将被使用的空位
private int _version;//增加删除容量变化时,_version++
private const int StartOfFreeList = -3;
}
2.如何将具有很多可能的关键字映射到有限的的哈希地址:
该问题分为两个步骤:
- 1.散列函数:将所有可能的关键字映射到一个有限的整数值,由于可能性非常非常多,为了减少冲突,所以该整数值范围也比较大,在.net中是一个
int类型的整数值,一般称为GetHashCode()方法 - 2.
int值的范围为-2147483648 ~ 2147483647,为了节省空间,不可能使用这么大的数组去保存单向链表头部元素的实际索引,所以需要压缩数组大小。
如何解决:
- 1.使用直接定址法:
哈希地址 = (GetHashCode(Ki)*0.000000001 +21) 取整虽然在系数取很小的情况下,达到了压缩的效果,但是哈希冲突非常高,无法实现高效的查询。如果系数取大,空间复杂度又会特别高。 - 2.使用除留余数法:
哈希地址 = GetHashCode(Ki) MOD C实际证明该方法的哈希冲突更少,在C为素数的情况下,效果更好。
在Dictionary<TKey, TValue>内部使用数组Entry[]来保存关键字和元素,使用 private int[] _buckets来保存单向链表头部元素所在的数组索引。上面提到,因为哈希冲突是不可避免的,对于有n个哈希地址的哈希表来说,Dictionary<TKey, TValue>一共构建了n+1个单向链表。另外单独的一个链表,用于保存已经释放的数组空位。
增加元素逻辑:
- 1.使用
_count来作为数组的空位指针,_count值永远指向数组中下一个将被使用的空位 - 2.使用
_freeList来保存释放链表的头部元素所在数组(_entries[])索引 - 3.如果释放链表为空的情况下,保存元素到
_entries[_count],否则保存到_entries[_freeList] - 4.根据关键字获取哈希地址,如果
_buckets[哈希地址]中的值不为-1,则将刚保存元素的next置为_buckets[哈希地址]值(将元素加到单向链表的头部)。 - 5.更新
_buckets[哈希地址]的值为_freeList或者_count
public bool TryInsert(TKey key, TValue value)
{
if (key == null)
{
throw new ArgumentNullException("TKey不能为null");
}
if (_buckets == null)
{
Initialize(0);
}
Entry[] entries = _entries;
IEqualityComparer<TKey> comparer = _comparer;
uint hashCode = (uint)comparer.GetHashCode(key);
int collisionCount = 0;//哈希碰撞次数
ref int bucket = ref _buckets[hashCode % (uint)_buckets.Length];//元素所在的实际地址
// Entry链表最新索引
// -1:链表结束
// >=0:有下一节点
int i = bucket - 1;
//统计哈希碰撞次数
do
{
if ((uint)i >= (uint)entries.Length)
{
break;
}
if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key))
{
entries[i].value = value;
_version++;
return true;
}
i = entries[i].next;
if (collisionCount >= entries.Length)
{
throw new InvalidOperationException("不支持多线程操作");
}
collisionCount++;
} while (true);
bool updateFreeList = false;
int index;
//如果FreeList链表中长度大于0
//优先使用FreeList
if (_freeCount > 0)
{
index = _freeList;
updateFreeList = true;
_freeCount--;
}
else
{
int count = _count;
//超出数组大小
if (count == entries.Length)
{
//将数组长度扩展为大于原长度两倍的最小素数
var forceNewHashCodes = false;
var newSize = HashHelpers.ExpandPrime(_count);
Resize(newSize, forceNewHashCodes);
bucket = ref _buckets[hashCode % (uint)_buckets.Length];
}
index = count;
_count = count + 1;
entries = _entries;
}
ref Entry entry = ref entries[index];
if (updateFreeList)
{
_freeList = StartOfFreeList - entries[_freeList].next;
}
entry.hashCode = hashCode;
// Value in _buckets is 1-based
entry.next = bucket - 1;
entry.key = key;
entry.value = value;
// Value in _buckets is 1-based
bucket = index + 1;
_version++;
// 如果不采用随机字符串哈希,并达到碰撞次数时,切换为默认比较器(采用随机字符串哈希)
if (default(TKey) == null && collisionCount > HashHelpers.HashCollisionThreshold && comparer is NonRandomizedStringEqualityComparer) // TODO-NULLABLE: default(T) == null warning (https://github.com/dotnet/roslyn/issues/34757)
{
_comparer = null;
Resize(entries.Length, true);
}
return true;
}
删除元素逻辑:
- 1.根据关键字获取哈希地址,链表头部元素索引=
_buckets[哈希地址]。 - 2.遍历链表,找到对应关键字的元素。
- 3.将元素赋为默认值,并加入到释放链表的头部。
- 4.构建上一个节点与下一个节点之间的指向关系
lastEle.next = nextEle.index
/// .NetCore3.0 Remove执行之后_version没有自增
public bool Remove(TKey key)
{
int[] buckets = _buckets;
Entry[] entries = _entries;
int collisionCount = 0;
if (buckets != null)
{
uint hashCode = (uint)(_comparer?.GetHashCode(key) ?? key.GetHashCode());
uint bucket = hashCode % (uint)buckets.Length;
int last = -1;//记录上一个节点,在删除中间节点时,将前后节点建立关联
int i = buckets[bucket] - 1;
while (i >= 0)
{
ref Entry entry = ref entries[i];
if (entry.hashCode == hashCode && _comparer.Equals(entry.key, key))
{
if (last < 0)
{
//删除的节点为首节点,保存最新索引
buckets[bucket] = entry.next + 1;
}
else
{
//删除节点不是首个节点,建立前后关系
entries[last].next = entry.next;
}
// 将删除节点加入FreeList头部
entry.next = StartOfFreeList - _freeList;
// 置为默认值
if (RuntimeHelpers.IsReferenceOrContainsReferences<TKey>())
{
entry.key = default;
}
if (RuntimeHelpers.IsReferenceOrContainsReferences<TValue>())
{
entry.value = default;
}
// 保存FreeList头部索引
_freeList = i;
_freeCount++;
return true;
}
// 当前节点不是目标节点
last = i;
i = entry.next;
if (collisionCount >= entries.Length)
{
// The chain of entries forms a loop; which means a concurrent update has happened.
// Break out of the loop and throw, rather than looping forever.
// ThrowHelper.ThrowInvalidOperationException_ConcurrentOperationsNotSupported();
throw new InvalidOperationException("不支持多线程操作");
}
collisionCount++;
}
}
return false;
}
三、GitHub源码地址
四、String.GetHashCode()方法
不采用随机字符串的方法:源码地址
对于某一个确定的字符串,返回确定的hashcode,缺点:容易被哈希洪水攻击。
// Use this if and only if 'Denial of Service' attacks are not a concern (i.e. never used for free-form user input),
// or are otherwise mitigated
internal unsafe int GetNonRandomizedHashCode()
{
fixed (char* src = &_firstChar)
{
Debug.Assert(src[this.Length] == '�', "src[this.Length] == '\0'"\0'");
Debug.Assert(((int)src) % 4 == 0, "Managed string should start at 4 bytes boundary");
uint hash1 = (5381 << 16) + 5381;
uint hash2 = hash1;
uint* ptr = (uint*)src;
int length = this.Length;
while (length > 2)
{
length -= 4;
// Where length is 4n-1 (e.g. 3,7,11,15,19) this additionally consumes the null terminator
hash1 = (BitOperations.RotateLeft(hash1, 5) + hash1) ^ ptr[0];
hash2 = (BitOperations.RotateLeft(hash2, 5) + hash2) ^ ptr[1];
ptr += 2;
}
if (length > 0)
{
// Where length is 4n-3 (e.g. 1,5,9,13,17) this additionally consumes the null terminator
hash2 = (BitOperations.RotateLeft(hash2, 5) + hash2) ^ ptr[0];
}
return (int)(hash1 + (hash2 * 1566083941));
}
}
采用随机字符串的方法: 源码地址
特点:
- 1.两个字符串相等,返回相同的哈希值
- 2.不同的字符串可以返回相同的哈希值
- 3.基于不同的.Net实现、.Net平台、.Net版本、应用程序域,同一个字符串可能返回不同的哈希值
- 4.哈希值决不能在创建它们的应用程序域的外部使用
public override int GetHashCode()
{
ulong seed = Marvin.DefaultSeed;
// Multiplication below will not overflow since going from positive Int32 to UInt32.
return Marvin.ComputeHash32(ref Unsafe.As<char, byte>(ref _firstChar), (uint)_stringLength * 2 /* in bytes, not chars */, (uint)seed, (uint)(seed >> 32));
}