神经网络模型的构成:神经元

如图是一个神经元模型,这里a1-an代表输入的各个分量。w1-wn代表神经网络的各个突触的权值。b表示一个偏置。f:传递函数,常是非线性函数。t:神经元的输出。
用数学表示为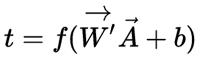 ,其中
,其中
为权向量,
为
为输入向量
为偏置
为传递函数
意义为求得输入向量与权向量的內积后,经过非线性函数的传递得到一个标量。
一个简单是神经网络模型:
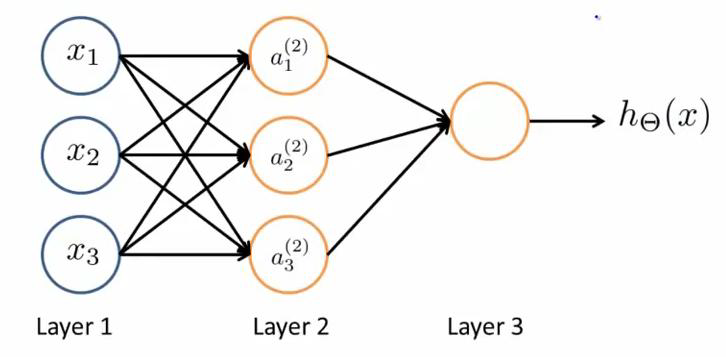
layer1是输入层,我们将原始数据输入给它们
layer2是隐藏层(激励层),它们负责将数据进行处理,然后呈递到下一层
layer3是输出层,它负责计算h(x)。
ai(j)代表第j层的第i个神经元,θ(j)表示波形矩阵,用来控制第j层。
对于上图所示的模型,激活单元和输出的分别表达为:
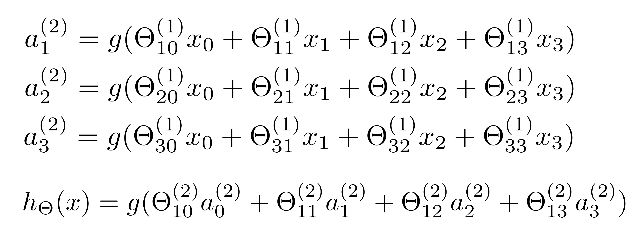
相对使用循环来编码,使用向量化会是的计算变的更方便。以上面的两个神经网络为例,试着计算二层的值的,
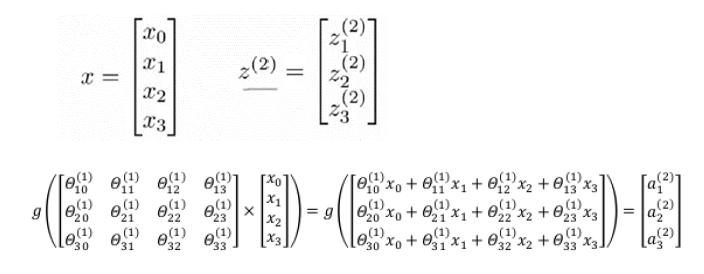
我们令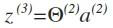 ,则
,则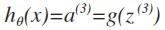 。
。
这只是训练集中一个训练实例的计算,如果我们要对整个训练集计算,需要将特训集特征矩阵进行转置,使得同一个实例的特征都在同一列里。
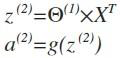
其实,右半部分就像之前我们所认识的逻辑回归中的h, 其中hθx =
其中hθx =
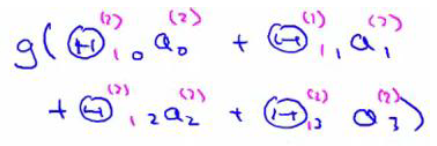
我们还可以把a0,a1,a2,a3看成一个更高级的特征值,也就是x0,x1,x2,x3的进化,并且由x决定,因为是梯度下降的,所以a是变化的,并且变化越来越快,所以这些更高级的特征值远比x的次方厉害,也就可以更好的预测新的数据。这就是神经网络相对于逻辑回归和线性回归的优势所在。