安装: pip install selenum
下载 chromedriver 下载链接: https://chromedriver.chromium.org/downloads
注意:下载文件要与chrome版本相兼容(可以在Google的帮助中查看Google的版本)
注意:64位浏览器对应32位chromedriver
**坑 安装版本比匹配的chromedriver 在使用webdriver.Chrome()可以打开浏览器,但是使用get方法访问网站出错
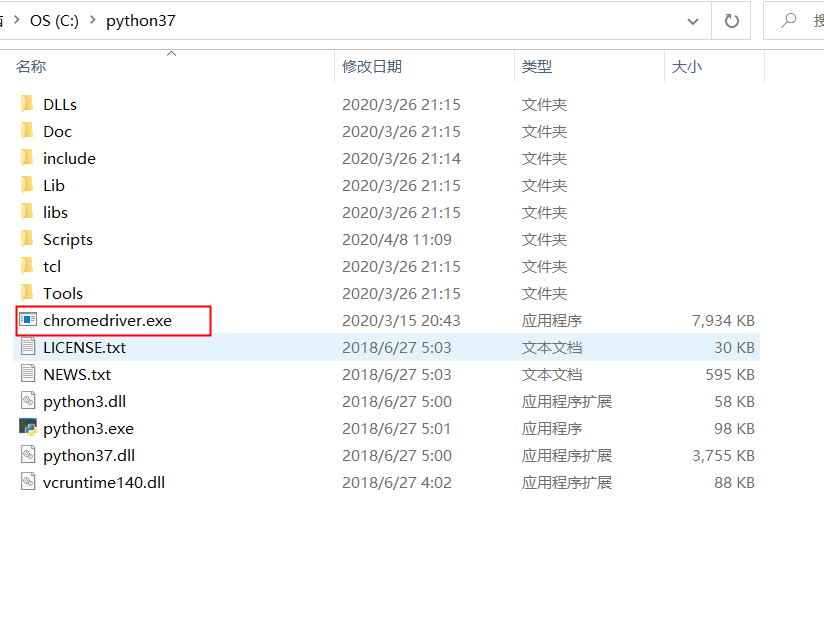
配置chromedriver:
将下载的chromedriver放置到python目录 或者放置到chrome的安装目录(优先python目录)
给浏览器设置代理:
from selenium import webdriver
proxy = '127.0.0.1:808'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + proxy)
chrome = webdriver.Chrome(chrome_options=chrome_options)
导包: from selenium import webdriver
选择浏览器:webdriver.Chrome()
访问网页:webdriver.Chrome().get('url')
返回上一层:webdriver.Chrome().back()
关闭浏览器:webdriver.Chrome().close()
最大化:webdriver.Chrome().close()
获取源码:page_source()
页面源码: webdriver.Chrome().page_source()
获取节点内容:webdriver.find_element_by_xpath().text
获取节点属性值:webdriver.find_element_by_xpath().get_attribute('属性')
节点选择:
通过xpath语法选择:webdriver.find_element_by_xpath()
通过标签选择器选择和模拟点击节点:webdriver.find_element_by_id().click()
清楚选择节点的内容:chrome.find_element_by_xpath('//*[@id="identify_email"]').clear()