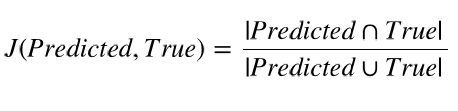参考资料:Mastering Machine Learning with scikit-learn
注:代码不可直接运行
- 广义线性回归模型之逻辑回归(logistic regression)—分类任务
- 分类任务的目标是找一个函数,把观测值匹配到相关的类和标签上。在二元分类(binary classification)中,分类算法必须把一个实例配置两个类别;多元分类中,分类算法需要为每个实例都分类一组标签。
- 逻辑回归处理二元分类
线性回归假设解释变量值的变化会引起响应变量值的变化,如果响 应变量的值是概率的,这条假设就不满足了。广义线性回归去掉了这条假设,用一个联连函数(link function)来描述解释变量与响应变量的关系。
在逻辑回归里,响应变量描述了类似于掷一个硬币结果为正面的概率。如果响应变量等于或超过了指定的临界值,预测结果就是正面,否则预测结果就是反面。
from sklearn.linear_model.logistic import LogisticRegression classifier = LogisticRegression() classifier.fit(X_train, y_train) predictions = classifier.predict(X_test)
- 二元分类效果评估方法
二元分类的效果评估方法有很多,常见的包括准确率(accuracy), 精确率(precision)和召回率(recall)三项指标,以及综合评价指标(F1 measure), ROC AUC 值(Receiver Operating Characteristic ROC,Area Under Curve,AUC)。
- 混淆矩阵(Confusion matrix),也称列联表分析(Contingency table)
import itertools import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties font = FontProperties(fname=r"C:UsersLenovoDesktopdata_setmsyh.ttc", size=10) from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt y_test = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] y_pred = [0, 1, 0, 0, 0, 0, 0, 1, 1, 1] confusion_matrix = confusion_matrix(y_test, y_pred) print(confusion_matrix) plt.matshow(confusion_matrix) plt.title('混淆矩阵',fontproperties=font) plt.colorbar() plt.ylabel('实际类型',fontproperties=font) plt.xlabel('预测类型',fontproperties=font) for i, j in itertools.product(range(confusion_matrix.shape[0]), range(confusion_matrix.shape[1])): plt.text(j, i, format(confusion_matrix[i, j]), horizontalalignment="center", ) plt.show()
- 准确率(accuracy)
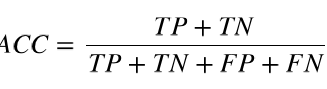
准确率是分类器预测正确性的评估指标。scikit-learn提供了accuracy_score来计算:
from sklearn.metrics import accuracy_score y_pred, y_true = [0, 1, 1, 0], [1, 1, 1, 1] print(accuracy_score(y_true, y_pred))
如果分类的比例在样本中严重失调,准确率并非一 个有效的衡量指标。
- 精确率(precision:被判别为正类的样本中,真正为正类的样本所占的比例
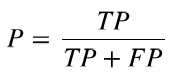
- 召回率(recall):被判别为正类的样本占所有正类样本的比例
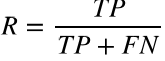
- 计算综合评价指标
综合评价指标(F1 measure)是精确率和召回率的调和均值(harmonic mean),或加权平均值, 也称为F-measure或fF-score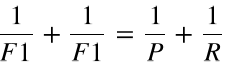
即: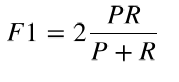
from sklearn.linear_model.logistic import LogisticRegression from sklearn.cross_validation import train_test_split, cross_val_score classifier = LogisticRegression() classifier.fit(X_train, y_train)
#X_train_raw, X_test_raw, y_train, y_test = train_test_split(df) precisions = cross_val_score(classifier, X_train, y_train, cv=5, scoring= 'precision') print('精确率:', np.mean(precisions), precisions) recalls = cross_val_score(classifier, X_train, y_train, cv=5, scoring='re call') print('召回率:', np.mean(recalls), recalls) f1s = cross_val_score(classifier, X_train, y_train, cv=5, scoring='f1') print('综合评价指标:', np.mean(f1s), f1s)
- ROC AUC
- ROC曲线(Receiver Operating Characteristic,ROC curve)
ROC曲线画的是分类器的召回率与误警率(fall-out)的曲线,误警率也称假阳性率,是所有负类样本中分类器识别为正类的样本所占比例: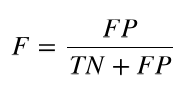
AUC是ROC曲线下方的面积,它把ROC曲线变成一个值,表示分类器随机预测的效果。scikit-learn 提供了计算ROC和AUC指标的函数
from sklearn.metrics import roc_curve, auc classifier = LogisticRegression() classifier.fit(X_train, y_train) predictions = classifier.predict_proba(X_test) false_positive_rate, recall, thresholds = roc_curve(y_test, predictions[: , 1]) roc_auc = auc(false_positive_rate, recall)
- 网格搜索
网格搜索(Grid search)就是用来确定最优超参数的方法,scikit-learn有GridSearchCV()函数解决这个问题:
#代码不可直接运行
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import precision_score, recall_score, accuracy_score
from sklearn_pandas import DataFrameMapper
feature_mapper = DataFrameMapper() pipe = make_pipeline(feature_mapper,LogisticRegression()) # pipe.get_params().keys()# 用于查看pipe中可调的超参数
pipe.set_params(logisticregression__C=1,logisticregression__penalty='l1' )
param_grid={'logisticregression__C':np.arange(0.1,2,0.3), 'logisticregression__penalty': ['l1','l2']}
grid = GridSearchCV(pipe,cv=3,param_grid=param_grid,n_jobs = 4, scoring ='accuracy')
grid.fit(Train, Trainy)
print('最佳效果:%0.3f' % grid.best_score_)
print('最优参数组合:')
best_parameters = grid.best_estimator_.get_params()
for param_name in sorted(param_grid.keys()):
print(' %s: %r' % (param_name, best_parameters[param_name]))
predictions = grid.predict(X_test)
print('准确率:', accuracy_score(y_test, predictions))
print('精确率:', precision_score(y_test, predictions))
print('召回率:', recall_score(y_test, predictions))
#n_jobs是指并发进程最大数量,设置为-1表示使用所有CPU核心进程
- 多类分类(Multi-class classification)
scikit-learn用one-vs.-all或one-vs.-the-rest方法实现多类分类,就是把多类中的每个类都作为二 元分类处理。分类器预测样本不同类型,将具有最大置信水平的类型作为样本类型。
- 多类分类效果评估
predictions = grid_search.predict(X_test)
print('准确率:', accuracy_score(y_test, predictions))
print('混淆矩阵:', confusion_matrix(y_test, predictions))
print('分类报告:', classification_report(y_test, predictions))
- 多标签分类和问题转换(multi-label classification)
- 多标签分类问题一般有两种解决方法
第一种转换方法是训 练集里面每个样本通过幂运算转换成单标签,这种幂运算虽然直观,但是并不实用,因为这样做多出来的标 签只有一小部分样本会用到。而且,这些标签只能在训练集里面学习这些类似,在测试集中依然无法使用。
第二种问题转换方法就是每个标签都用二元分类处理。
- 多标签分类效果评估
常用方法:
汉明损失函数(Hamming loss)和杰卡德相似度(Jaccard similarity)。汉明损失函数表示错误标签的平均比例,是一个函数当预测全部正确,即没有错误标签时值为0。杰卡德相似度或杰卡德相指数(Jaccard index),是预测标签和真实标签的交集数量除以预测标签和真实标签的并集数量。其值在{0,1}之 间,公式如下: