第一章读后感
SRE之道的理解:创建软件系统来运行和替换传统的人工操作。
在实际工作中:
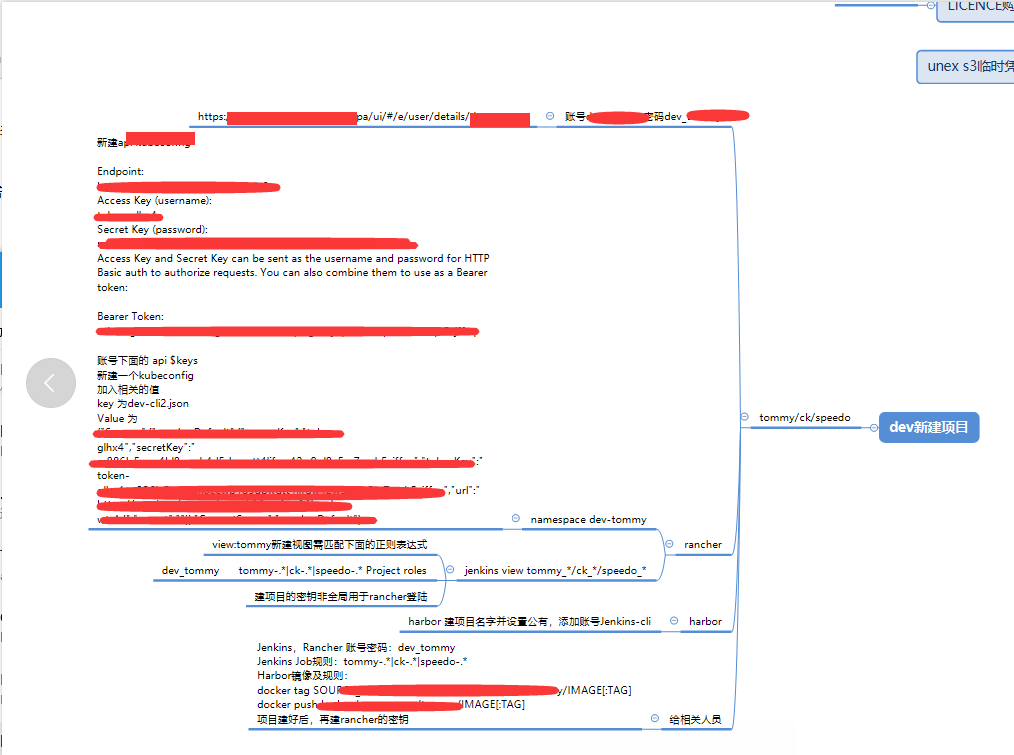
1.我们执行重复性的工作,流程话,新建项目需要那些资源,那些账号,那些权限,制作成流程,一个项目来了相关同事按照流程操作,不会遗漏细节,提高速度。
eg:
新项目流程:xmind,(一图胜万语言)
2.系统节点出现故障,自动升级docker,添加到集群节点,减少重复性工作,节省更多时间到技术学习中,和SRE核心思想和理论相符合。
3.监控系统:
首先我们的监控式蓝鲸平台:
1.能对基础资源监控,cpu,内存,磁盘使用等。
2.能自定义监控:监控我们项目的api,公共服务访问是否正常,nginx,rocket,solr服务是否正常运行,k8s集群的pod监控,node的监控。能满足我们日常业务的需要
3.能邮件报警,报警策略比较丰富,实时性,准确性高。
4.出现告警也能自愈,磁盘使用率过高,自动清理日志。以前unex系统经常异常死节点,aws上又不能看日志,所以完全没有眉目,每次挂节点后,需要手动添加节点,配置相关选项,耗时耗力。后来接入蓝鲸自愈监控磁盘,自动处理后,一直未见node挂掉的现象,一劳永逸。
第五章读后感
减少琐事:
SRE要把更多的时间放在研究项目上而非日常运维中。
首先每个公司的项目流程,基础架构基本相同,需要进行梳理,并做好相关策略(架构图,网络图,安装配置文档,配置策略备份,数据策略,注意事项):
1.基础服务的梳理:
jenkins
nexus
sonar等
这些服务的配置项,及配置的意义,其实包括所有的软件配置项,及配置的意义,都需要整理。
2.所有的服务,或者说任意一个服务挂了,会影响服务吗,恢复的时间,要恢复就要有备份,备份在哪里,怎么备份,这一套流程都需要整理。
SRE中定义了一个概念叫SLO(服务质量目标),通过SLO合理评判一个服务要达成的服务质量。工作过程中指定合理的服务质量目标,可以科学的运维。
这本书中提到服务太稳定不好:
服务太稳定,相关的依赖就很多,一旦出现问题,会影响很多,所以需要做故障演练,当真正出现问题的时候,能游刃有余。
3.最近正在整理线上的软件安装步骤及配置:
以前自己只会二进制安装k8s,但是现在需要用到kubespray,kops等工具安装,现在使用安装没有问题,kubespray已经成功加到线上节点,正常使用。KOPS自己本地已经安装成功,正准备把一个项目放到里面去运行,使aws那一套kops流程跑完,再整理线上的kops项目,梳理成文档,避免下次走这一套繁琐的过程。