一、系统调用实验(下):
1.编辑 menu 中的 text.c 文件,给MenuOS增加 rename 和 rename_asm 命令:

make rootf 打开 menu 镜像,可以看到MenuOS菜单中新增了两条命令:
2.gdb 跟踪 sys_rename:
同第二个实验相同,先使得 CPU 静止,在 sys_rename 处设置断点,在MenuOS中执行rename命令,发现停在SyS_rename(定义在fs/namei.c中)处,用宏来实现。然后继续单步执行:
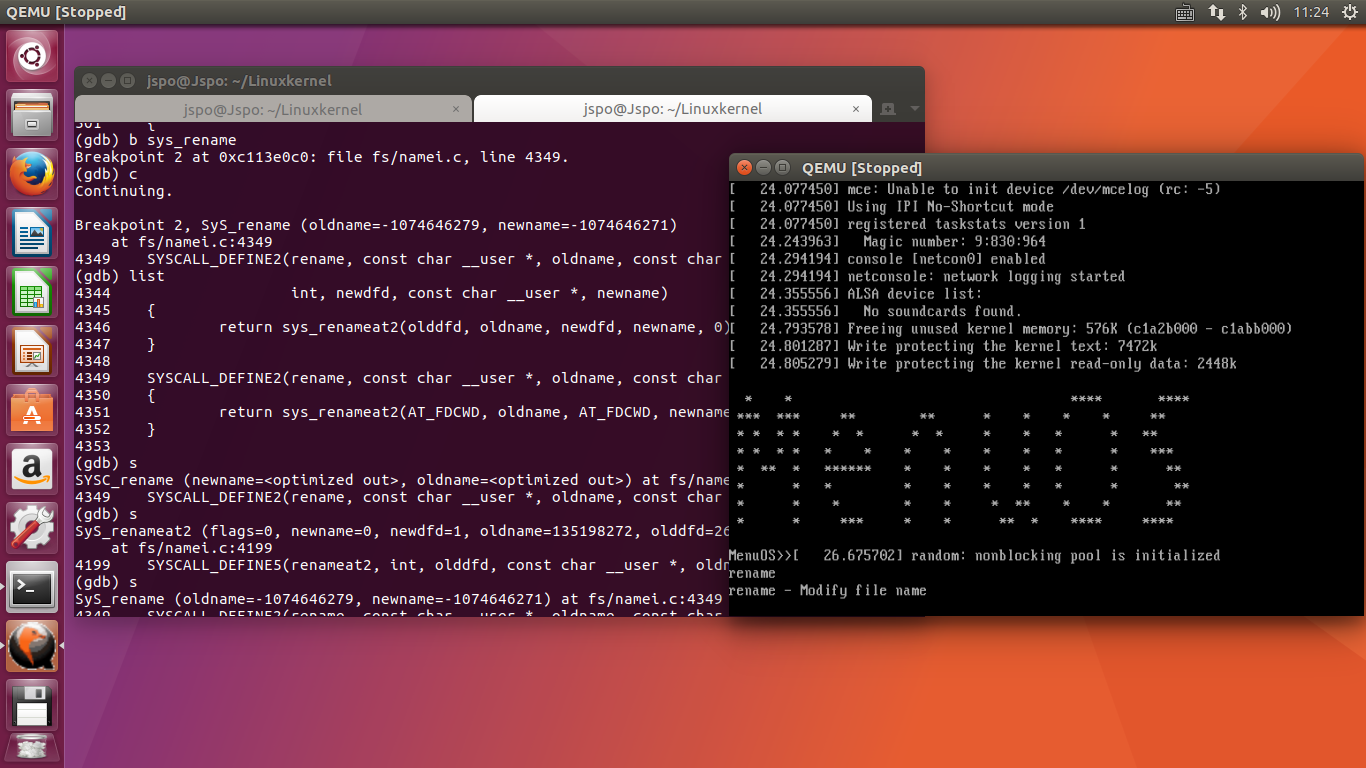
大家知道执行int 0x80,CPU就会自动跳转到 sys_call 来执行。所以为了跟踪 sys_call,在 sys_call 处设置断点,在MenuOS中执行 rename_asm 命令,依旧停在 SyS_rename 处,并没有停在所期待的 sys_call 处,这是因为 system_call 不是正常的函数,是一段特殊的汇编代码,gdb还不能进行跟踪。
3.分析系统调用的处理过程:
系统调用机制的初始化是在 start_kernel 中的 trap_init()(定义在/arch/x86/kernel/traps.c中)里进行的:
#ifdef CONFIG_X86_32
set_system_trap_gate(SYSCALL_VECTOR, &system_call); //SYSCALL_VECTOR系统调用的中断向量,&system_call是 system_call的入口,一旦执行int 0x80,CPU就会立即跳转到此处
set_bit(SYSCALL_VECTOR, used_vectors);
#endif
在 /arch/x86/include/asm/irq_vectors.h 中查看 SYSCALL_VECTOR 的值,确实是0x80:
#ifdef CONFIG_X86_32
# define SYSCALL_VECTOR 0x80
#endif
system_call 的相关代码的位置是 /arch/x86/kernel/entry_32 :
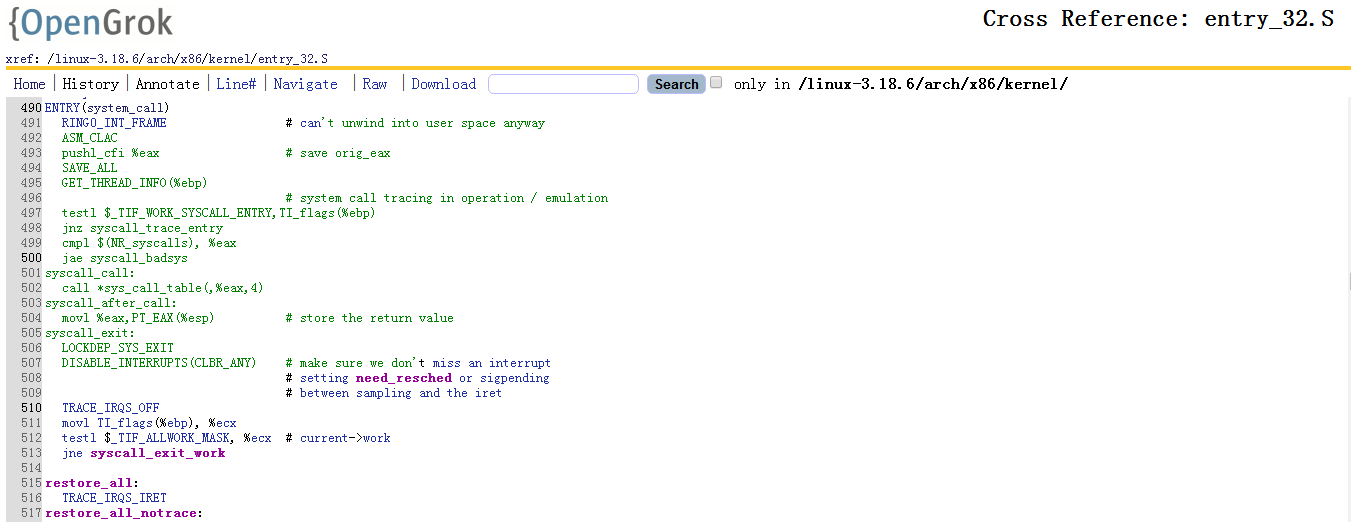
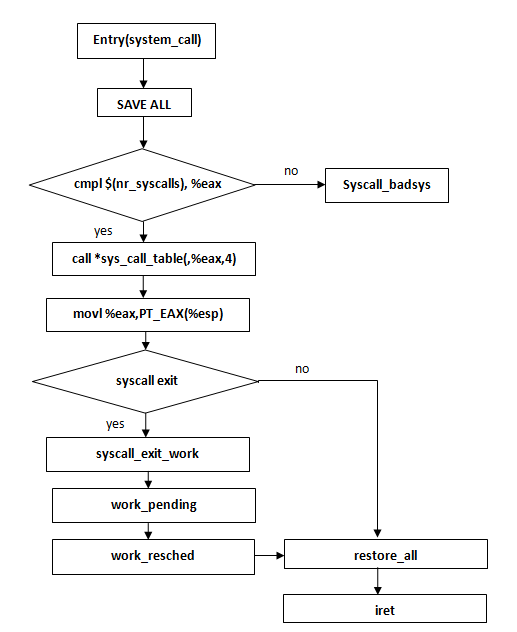
ENTRY(system_call)
RING0_INT_FRAME
ASM_CLAC
pushl_cfi %eax //保存系统调用号;
SAVE_ALL //可以用到的所有CPU寄存器保存到栈中
GET_THREAD_INFO(%ebp) //ebp用于存放当前进程thread_info结构的地址
testl $_TIF_WORK_SYSCALL_ENTRY,TI_flags(%ebp)
jnz syscall_trace_entry
cmpl $(nr_syscalls), %eax //检查系统调用号(系统调用号应小于NR_syscalls),
jae syscall_badsys //不合法,跳入到异常处理
syscall_call:
call *sys_call_table(,%eax,4) //合法,对照系统调用号在系统调用表中寻找相应服务例程
movl %eax,PT_EAX(%esp) //保存返回值到栈中
syscall_exit:
testl $_TIF_ALLWORK_MASK, %ecx //检查是否需要处理信号
jne syscall_exit_work //需要,进入 syscall_exit_work
restore_all:
TRACE_IRQS_IRET //不需要,执行restore_all恢复,返回用户态
irq_return:
INTERRUPT_RETURN //相当于iret
注:
(1)sys_call_table(,%eax,4)的理解:因为分派表中的每个表项占4个字节,所以先把系统调用号(eax)乘以4,再加上 sys_call_table 分派表的起始地址,即是所调用的服务例程。
(2)GET_THREAD_INFO 宏用于获得当前进程的thread_info结构的地址,即获取当前进程的信息。
(3)syscall_exit_work 执行了一些进程调度、消息传递的工作,如果进行了进程切换,可能要继续触发新的中断,执行新的系统调用。
画图理一下思路,方便加深印象:
4.问题及解决:
(1)起初,我直接将函数命名为 rename,报错:
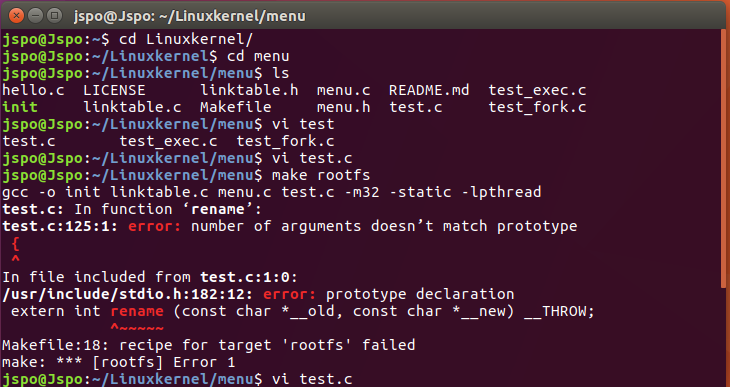
我只看到 error:prototype declaration,没有搞清楚为什么会报错。对照视频,发现视频中函数名是首字母大写,我的是小写,所以我想会不会是 MenuConfig 传值有什么要求,找到MenuConfig函数:

第三个参数只是函数指针,并没有对命名有什么要求。我尝试把 rename 改为 Rename,但没有改rename_asm, 发现编译成功。这说明和大小写没什么关系。我又回看了报错信息,终于看到参数不匹配原型,函数名定义为rename,里面又调用了rename,两次参数个数不一样,这肯定不对:

再验证一下,将函数命名为renam,编译成功。
所以,要认真看报错信息,少走弯路!
(2)参照通过系统调用分析system_call中断处理过程,我先在 sys_rename 处打上断点,通过info line entry_32.S:493 找到entry_32.S的entry所在的内存地址,并在内存地址0xc1749f47上面打了断点。输入 time_asm,停是停住了,但是显示的是 <signal handler called>,info reg eax查看eax值确实为38,一直按ni,都是 <signal handler called> ,不显示代码:
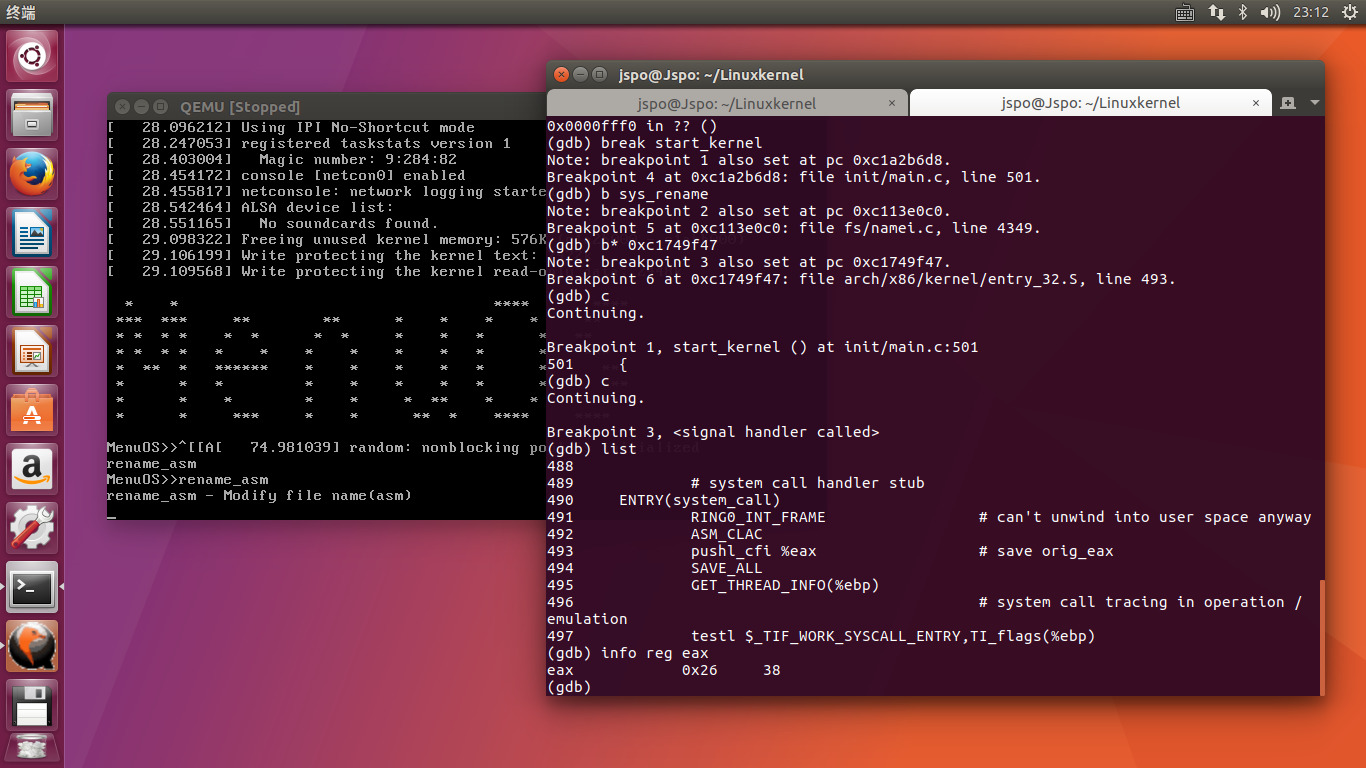
我用了display /i $pc 可以看到每一步执行,但不完全是内核源码,我也调不出原博的格式,但大致能看懂,每一步的细节地址有时间一一分析。
下图显示的是SAVE_ALL:
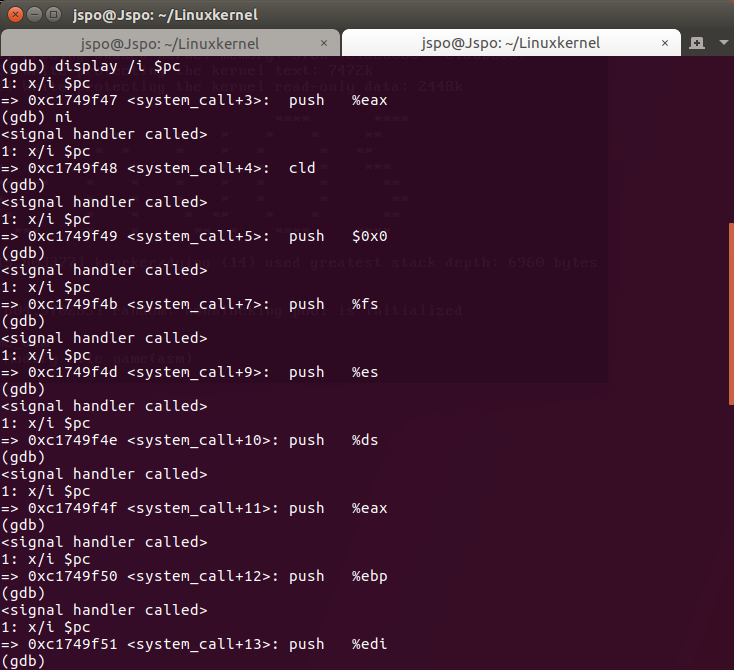
可以看到在执行完call *sys_call_table(,%eax,4) 后,寻找 sys_rename 服务例程,所以在SyS_rename处停下:
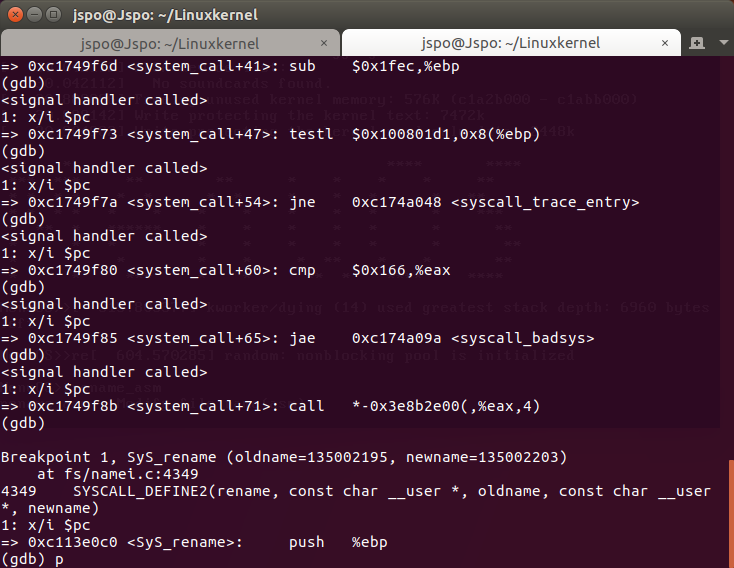
sys_call_table中38号对应 SyS_rename 函数:

SyS_rename 执行完后返回 system_call 函数中的call *sys_call_table(,%eax,4) 的后一句movl %eax,PT_EAX(%esp):

二、课本笔记:
多个执行线程同时访问和操作数据,就有可能发生各线程之间相互覆盖共享数据的情况,造成共享数据处于不一致状态。临界区是访问和操作共享数据的代码段。避免并发和防止竞争条件称为同步。并发产生的原因有中断、软中断和tasklet、内核抢占、睡眠及与用户空间的同步、对称多处理。
可以通过加锁来保护临界区资源。要给数据而不是给代码加锁。最开始设计代码的时候就要考虑加入锁。按顺序加锁、防止发生饥饿、不要重复请求同一个锁、设计力求简单对避免死锁大有帮助。加锁粒度用来描述加锁保护的数据规模。设计锁在开始阶段都很粗,但当锁的争用问题变得严重时,设计就向更加细的加锁方向发展。
内核提供两组原子操作的接口,一个针对整数,一个针对位进行操作。针对整数的原子操作只能对atomic_t类型的数据进行处理,原子位操作是对普通的指针进行的操作,可以操作任何希望的数据。
自旋锁只能被一个可执行线程持有。一个被争用的自旋锁使得请求它的线程在等待锁重新可用时处于忙循环(自旋),浪费处理器时间。信号量是一种睡眠锁,同时允许任意数量的锁持有者,只有一个持有者的信号量叫互斥信号量。一个被争用的信号量使得请求它的线程进入一个队列,然后让其睡眠,处理器就可重获自由。所以1.自旋锁的作用是在短期内进行轻量级加锁,而信号量适用于锁被长时间持有的情况;2.自旋锁可用使用在中断程序中,在中断程序中使用自旋锁前,一定要禁止本地中断,否则中断程序就会打断正持有锁的内核代码并有可能去试图争用这个已经被持有的锁,从而导致双重请求死锁;信号量不可用在中断上下文。
//加锁一个自旋锁函数
void spin_lock(spinlock_t *lock); //获取指定的自旋锁
void spin_lock_irq(spinlock_t *lock); //禁止本地中断获取指定的锁
//释放一个自旋锁函数
void spin_unlock(spinlock_t *lock); //释放指定的锁
void spin_unlock_irq(spinlock_t *lock); //释放指定的锁,并激活本地中断
struct semaphore类型用来表示信号量。down一个信号量等于获取该信号量,临界区操作完成后,up释放信号量。
down最常见函数原型:
int down_interruptible(struct semaphore *sem)
{
unsigned long flags;
int result = 0;
spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0)) //count是使用者数量,若count大于0则可获得信号量锁
sem->count--; //获得信号量减1
else
result = __down_interruptible(sem); //没有获得信号量任务会被放入等待队列,在sem的wait_list链表尾部加入一新的节点
spin_unlock_irqrestore(&sem->lock, flags);
return result; //函数返回,其调用者开始进入临界区
}
up函数原型:
void up(struct semaphore *sem)
{
unsigned long flags;
spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))//wait_list队列为空表明没有其他进程正在等待该信号量
sem->count++;
else
__up(sem); //wait_list队列不为空说明有其他进程正睡眠,调用__up(sem)删除wait_list链表中的第一个有效节点,并唤醒睡眠在该节点上的进程,唤醒同时会获得该信号量
spin_unlock_irqrestore(&sem->lock, flags);
}
在一个时刻仅允许有一个锁持有者,即count为1,这样的信号量称为互斥信号量。互斥体是一种互斥信号。互斥体用于保护共享的易变代码。struct mutex 类型用来表示互斥体。如果静态声明一个count=1的semaphore变量,可以使用DECLARE_MUTEX(name),而如果要定义一个静态mutex型变量,应该使用DEFINE_MUTEX。mutex上的P,V操作:
void mutex_lock(struct mutex *)
void mutex_unlock(struct mutex *)
互斥体和信号量的区别:
1.互斥量用于线程的互斥,信号量用于线程的同步。
互斥:是指某一资源同时只允许一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。
同步:是指在互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。
2.互斥量的加锁和解锁必须由同一线程分别对应使用,信号量可以由一个线程释放,另一个线程得到。
注:
(1)在网上看到区别二者的很有意思的说法:Semaphore是说允许公厕里面有N个人同时用,再多的人就必须排队。mutex是说厕所是属于他的。他用的时候,别人决不能进去。他不用的时候,得到他的允许,别人才能进去。他也可以选择让厕所空着。
(2)互斥无序,同步有序。返回来想想上课所提到的生产者消费者问题以及测试读写者问题,都用到了struct semaphore,生产一个,消费一个,写一个,读一个,二者都需要考虑顺序,所以才选用信号量。
三、未解决问题:
调试中和内核源码相似但不一样,不知道这种方法是否合适?