
--------------------
创建正则表达式:

验证匹配的两个方法

1 //正则表达式测试 2 /* 3 var p=new RegExp("Box","i");//i表示忽略大小写 4 var str="this is box"; 5 alert(p.test(str));//页面打印true 如果没有i这个参数 表示不忽略大小写 那么就是会打印false 6 */ 7 /* 8 var p=/Box/i; 9 var str="This is box"; 10 alert(p.test(str));//打印true 11 */ 12 // alert(/Box/i.test("this is box")); 13 alert(/Box/i.exec("this is box"));//页面将会打印box 表示在忽略大小写的情况下 Box和this is box匹配的结果为 box
正则表达式.test("将要验证的内容"); test返回boolean值 exec方法返回的是匹配的内容
-----------------------------------------------

match方法:
1 //String中提供的验证方法 2 var p=/box/ig;//忽略大小写 并且全局匹配 3 var str="this is a box,this is a Box"; 4 alert(str.match(p));//该方法需要注意 因为是string提供的方法 所以这里调用的是str.方法名(正则) 而且该方法返回的是一个数组

因为匹配的是全局,所以能够打印所有的匹配内容,修改代码:
var p=/box/i;//忽略大小写 没有进行全局匹配
var str="this is a box,this is a Box";
alert(str.match(p));//

可以看到只匹配了第一个box
如果没有匹配的内容 ,那吗就返回null
--------------------------------
search方法
var p=/box/ig;//忽略大小写 进行全局匹配 var str="this is a box,this is a Box";//从零开始 空格也算一个位置 alert(str.search(p));//打印10 说明第一个匹配的位置是从10开始的


只会返回第一个匹配的位置
如果找不到 那么返回-1
var p=/xox/ig;
var str="this is a box,this is a Box";
alert(str.search(p));//找不到 返回-1

-------------------------------------
replace方法
var p=/box/ig;//开启全局 不区分大小写
var str="this is a box,this is a Box";
alert(str.replace(p,"tom"));//这个方法返回替换之后的str内容 第一个参数是将要被替换的内容规则 第二个参数是实际替换的值

如果不开启全局,那么只会替换第一个

------------------------------------------------
split方法:
var p=/ /ig;//开启全局 不区分大小写
var str="this is a box,that is a Box";
alert(str.split(p));//拆分的方法 返回的是一个数组 根据正则表达式中的拆分规则进行拆分 此处按照空额进行拆分
alert(str.split(p).length);//打印拆分之后数组的长度


--------------------------------------------------
RegExp的属性(没啥屌用 了解一下)


------------------------------------------------
匹配正则表达式规则: /匹配规则/
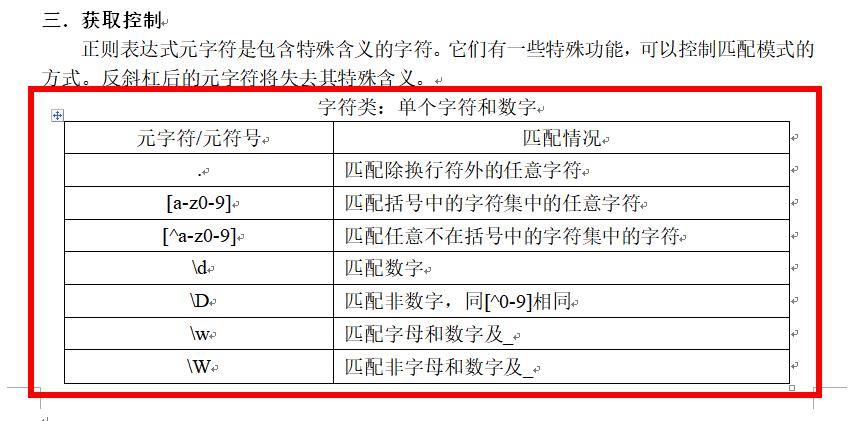


--------------------------------------
贪婪模式转换懒惰模式

对贪婪、惰性模式的理解:
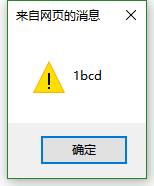
不使用贪婪,不使用全局
var pattern=/[a-z]/;//最初效果 不使用全局 只匹配了第一个字母 a
var str="abcd";
//alert(pattern.test(str));
alert(str.replace(pattern,"1"));//把匹配的字母替换为数字1 因为只匹配了第一个字母 所以效果为1bcd
不使用贪婪,使用全局
var pattern=/[a-z]/g;//匹配一个字母 但是使用了全局
var str="abcd";
//alert(pattern.test(str));
alert(str.replace(pattern,"1"));//把匹配的字母替换为数字1 因为使用了全局
// 在匹配第一个字母之后 仍然会继续匹配后面符合条件的内容 就造成把所有的匹配内容都做替换 所以效果为1111

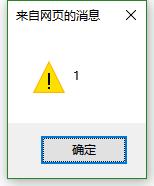
贪婪模式,不使用全局
var pattern=/[a-z]+/;//贪婪模式 不使用全局
var str="abcd";
//alert(pattern.test(str));
alert(str.replace(pattern,"1"));//[a-z]+的匹配内容为至少一个以上a-z的字母 所以就把abcd都匹配了 然后把匹配的内容替换为1 所以最终效果就是1
贪婪模式,使用全局
var pattern=/[a-z]+/g;//贪婪模式 使用全局
var str="abcd";
//alert(pattern.test(str));
alert(str.replace(pattern,"1"));//贪婪模式并且使用了全局 [a-z]+的匹配内容是把所有符合条件的字符进行匹配 无论是否全局 都会把abcd都进行匹配

懒惰模式,不使用全局
var pattern=/[a-z]+?/;//懒惰模式 不使用全局
var str="abcd";
//alert(pattern.test(str));
alert(str.replace(pattern,"1"));//惰性模式 [a-z]+?的匹配内容为0个或者1个a-z的字母 所以就只会匹配第一个字母a 然后把匹配的内容替换为1 所以最终效果就是1bcd

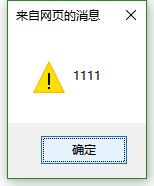
懒惰模式,使用全局
var pattern=/[a-z]+?/g;//惰性模式 使用全局
var str="abcd";
//alert(pattern.test(str));
alert(str.replace(pattern,"1"));//惰性模式并且使用了全局 [a-z]+?的匹配内容是只匹配0个或1个符合条件的字符 匹配成功之后 就不会继续向后匹配
// 但是使用了全局 就会在匹配第一个成功之后 仍然继续向下进行匹配(执行替换时,替换一个之后 ,继续向下把符合条件的内容进行替换) 所以最终效果就是1111
总结:
//全局的效果是在执行替换的时候才发挥作用,作用是匹配到一个符合条件的内容之后 继续向后找 否则就不向后找
// /[a-z]/g 效果1111 /[a-z]+/ 效果是1 第一个是只匹配一个a-z字母 但是使用了全局 就会在执行替换成功之后
// 继续向下进行寻找 因为使用了全局嘛 找到最后为止(执行效果:1bcd 11cd 111d 1111)
// 而第二个是执行之前 就已经匹配了所有 [a-z]+的意思不就是1个以上的a-z字母吗 即/[a-z]+/完全匹配abcd 所以替换的时候把所以的字母替换成了1
----------------------------------
分组匹配:

//使用分组匹配
var pattern=/^([a-z]+)s([0-9]{4})$/;
var str="google 2012";
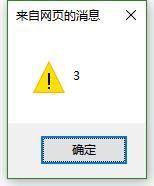
alert(pattern.exec(str).length);//查看返回的数组的长度
alert(pattern.exec(str));//输出数组中的全部内容 中间使用逗号分隔
// 第一个元素是匹配到的整个字符串 第二个元素:匹配到的第一个分组的字符串 第三个元素:匹配到的第二个分组的字符串
//下面分别打印观察结果:
var result=pattern.exec(str);
alert("匹配到的整个内容:"+result[0]);
alert("匹配到的第一个分组的字符串:"+result[1]+",即RegExp.$1的值:"+RegExp.$1);
alert("匹配到的第二个分组的字符串:"+result[2]+",即RegExp.$2的值:"+RegExp.$2);
运行效果:




----------------------------------------------
去除字符串的前后空格问题:
//取出前后的空格:第一种 分批去除空格
var pattern=/^s*/;
var str=" goo gle "//最后的效果 goo gle前后空格都要去掉
var result=str.replace(pattern,'');
alert("|"+result+"|");//此处已经去除了前面的空格了
pattern=/s*$/;
result=result.replace(pattern,'');
alert("|"+result+"|");


------------
//取出前后的空格:第二种 一个正则表达式 之前一次性把前后都去掉
var pattern=/^s*(.*?)s*$/;//这里需要注意了 如果是贪婪模式.*那么就是把之后的空格也都给匹配了[goo gle ]
// 惰性模式的时候 ^s*匹配前边 s*$匹配后边 所以中件的部分只会匹配到[goo gle] 而正好中间的部分使用了分组
// 在执行了exec方法之后 RegExp.$1中的值就是我们需要的(第一个分组中匹配的内容)
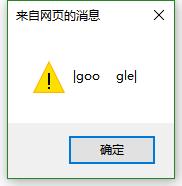
var str=" goo gle "//最后的效果 goo gle前后空格都要去掉
//alert(pattern.test(str));
alert("|"+pattern.exec(str)+"|");//上面使用了分组 所以返回的时候 第1个元素是匹配全部的内容 第二个元素是分组中匹配到的内容
var result=str.replace(pattern,RegExp.$1);//使用RegExp.$1时 必须先执行一下exec方法
alert("|"+result+"|");

alert("|"+pattern.exec(str)+"|");这句代码打印的内容就是上面的内容 这个方法返回的是一个数组 第一个元素是 匹配的全部内容[ goo gle ]
数组中第二个元素即下标为1的那个元素 就是第一个分组匹配到的内容[goo gle] ,显然最后需要得到的内容就是第一个元素的内容 RegExp.$1
----------------------------------
域名匹配小练习
//匹配域名
//jay123.com@djif.com
// var pattern=/([a-zA-Z0-9.\_]+)@([a-zA-Z]+).([a-zA-Z]{2,4})/;
var pattern=/^[w.-]+@[w-]+.[a-zA-Z]{2,4}/; // w是不包括.的 包括下化线 使用分组的时候就是加上了括号 加不加都不影响执行的效果
//如果需要获取匹配对应的内容的时候 加上分组然后调用里边的$1 $2.。就能分别获得第一个分组 第二个分组中的内容 比如上面的去前后空格的程序就是一个利用加括号巧妙使用分组的练习 例如下面的练习
var str="jay123.com@dj-if.com";
alert(pattern.test(str));
获取字符串中的指定位置的内容:
//获取域名中的对应内容 比如通过用户提供的字符串信息 从而得到它的用户名 @之后的内容 .之后的内容
var pattern=/([w.-]+)@([w-]+).([a-zA-Z]{2,4})/;
//上面的正则表达式中使用了3个分组 下面就得到这些分组的对应内容
var str="Joke666.com@mail.cn";
//运行exec方法(这样才可以使用RegExp.$x) 可以看到数组中的所有内容
alert("它的长度为:"+pattern.exec(str).length);
alert("它的内容为:"+pattern.exec(str));
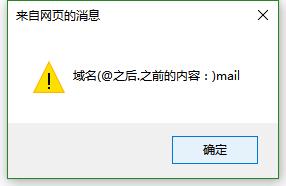
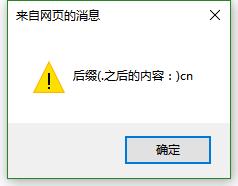
alert("用户名(@之前的内容:)"+RegExp.$1);
alert("域名(@之后.之前的内容:)"+RegExp.$2);
alert("后缀(.之后的内容:)"+RegExp.$3);


var result=pattern.exec(str);
上面第一个方框中的内容是:全部匹配的内容(result[0]), 第二个方框:第一个分组匹配的内容(result[1]) 第三个方框:第二个分组匹配到的内容(result[2]) 第四个方框:第三个分组中匹配到的内容(result[3])

-----------------------------------------------
捕获性分组:就是把所有的分组匹配内容都返回 非捕获性分组:在不想返回该分组匹配的内容的分组前使用 ?:那么将来在返回的的数组中就不能使用RegExp.$x得到该正则分组返回的内容

前瞻性捕获:(?=限制尾部的内容)

//前瞻捕获
//var pattern=/goo/;
//var str="goobb";
//alert(pattern.test(str));//匹配成功 打印true
//alert(pattern.exec(str));//返回goo 没有使用分组 所以这里只有匹配成功的一个数据 数组的长度也是1
//但是我想做的功能是啥呢 是尾部只能是gle的才匹配
var pattern=/goo(?=gle)/;//注意这里可是没有使用分组 这里的()作用就是限定尾部的内容只能是gle的才匹配
var str="google";
alert(pattern.exec(str));//匹配成功打印goo 注意这里是打印goo 而不是google
str="goobb";
alert(pattern.exec(str));//匹配失败 打印null


---------------------------