初识kafka心中有太多的疑惑,什么是kafka ? 它是用来做什么的 ?
一、Kafka的优势如下:
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒;
可扩展性:kafka集群支持热扩展;
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
容错性:允许集群中节点故障(若副本数量为n,则允许n-1个节点故障);
高并发:支持数千个客户端同时读写。
二、kafka机制
1) 消息传输流程

Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个Topic下的消费者和生产者的数量并不是对应的。
2) kafka服务器消息存储策略
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
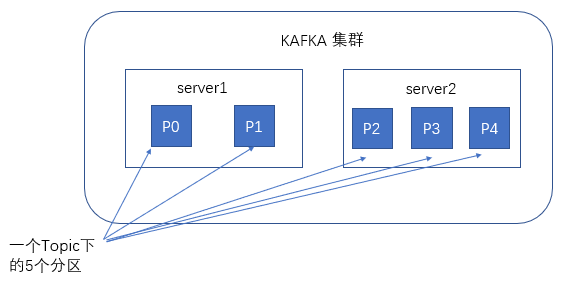
在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
3) 与生产者的交互

生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
4)与消费者的交互

在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
三、Kafka适合以下应用场景:
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer;
消息系统:解耦生产者和消费者、缓存消息等;
用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到数据库;
运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告;
流式处理:比如spark streaming和storm。
参考地址: