在JDK的并发包中,除了常用的哈希表外,还有一种有趣的数据结构—跳表。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们的相同点都是可以对元素进行快速的查找。但有一个很重要的差别:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样导致的结果就是,在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全,对于跳表,你只需要局部加锁即可。这样,就导致了跳表在高并发的情况下拥有更好的性能。
跳表的本质是同时维护了多个链表,并且链表是分层的,如下图所示:
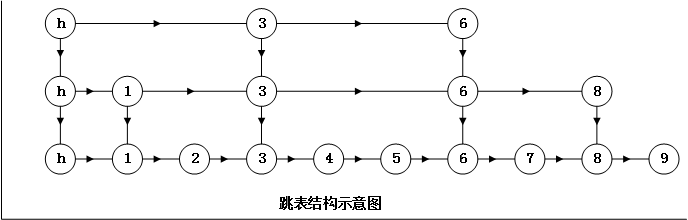
如上图所示,最低层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集,一个元素插入哪些层是完全随机的。因此,跳表还是有可能会有很糟糕的结构出现的概率的。但是在实际中,跳表的表现是非常好的。
还可以看出跳表内的所有链表的元素都是排序的,可以得出,跳表是一种空间换时间的算法。
跳表的查找方式:
跳表查找时,可以从顶级链表开始找,一旦发现被查找的元素大于当前链表中的取值,就会转入下一层开始查找。也就是说,在查找中,搜索是跳跃式的。
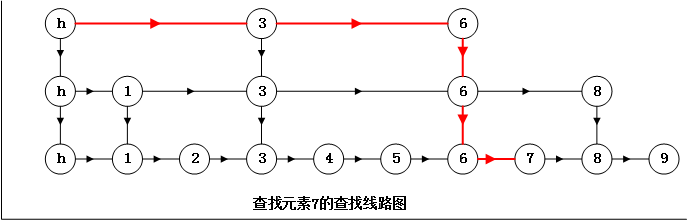
举例说明:从上述跳表结构中查找元素7,查找从顶层的头部索引节点开始。由于顶层的元素少,可以快速的跳跃那些小于7的元素。很快,查找过程就能到元素6,这时转入第二层,由于元素8大于7,故无法在第二层找到元素7,所以转入最低层开始查找,并且很快就能根据元素6找到元素7,这个查找元素的过程要比从元素1开始查找逐个搜索快很多,整个过程如下图红线所示:
在JDK中采用跳表结构的并发容器有:ConcurrentSkipListMap和ConcurrentSkipListSet;
ConcurrentSkipListMap:
ConcurrentSkipListMap和ConcurrentHashMap的不同之处不仅仅在于底层结构一个是跳表结构,一个是哈希算法结构;还有一个不同之处在于,哈希不会保存元素的顺序,而跳表内所有的元素都是有序的。因此,遍历跳表时,会得到一个有序的结果。所以,当你的应用需要有序性时,跳表就是你的不二选择。
先举例看看跳表Map(ConcurrentSkipListMap)的简单使用:
1 public static void main(String[] args){ 2 Map<Integer,Integer> map = new ConcurrentSkipListMap<Integer, Integer>(); 3 for (int i = 0;i < 10;i++){ 4 map.put(i,i); 5 } 6 for (Map.Entry<Integer,Integer> entry : map.entrySet()){ 7 System.out.println(entry.getKey()); 8 } 9 }
输出结果:
0 1 2 3 4 5 6 7 8 9
可以从输出结果看出,ConcurrentSkipListMap遍历输出是有序的。,并且使用的方式跟哈希Map的用法一致。
接下来通过源码来探究ConcurrentSkipListMap的底层实现:
首先是Node:
1 static final class Node<K,V> { 2 final K key; 3 volatile Object value; 4 volatile Node<K,V> next; 5 6 Node(K key, Object value, Node<K,V> next) { 7 this.key = key; 8 this.value = value; 9 this.next = next; 10 }
可以看出Node是由静态内部类实现的,一个Node就是一个节点,里面含有三个元素,key和value(就是Map的key和value),每个Node会指向下一个Node,next就是干这事的。value和next是关键字volatile修饰的,这保证了在并发环境下,线程对于value和next的可见性。对Node的操作,都是使用的CAS方法:
1 boolean casValue(Object cmp, Object val) { 2 return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val); 3 } 4 5 boolean casNext(Node<K,V> cmp, Node<K,V> val) { 6 return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); 7 }
casValue()是用来设置value的值的方法,casNext()则是用来设置next的字段。
数据结构Index:
index表示索引,看它的内部实现:
final Node<K,V> node; final Index<K,V> down; volatile Index<K,V> right;
上述时Index的类的变量定义,Index是一个ConcurrentSkipListMap的静态内部类,它包含了Node,还有向下和向右的引用。整个跳表就是根据Index进行全网的组织的。
此外,对于每一层的表头,还需要记录当前处于哪一层。所以,还有一个数据结构HeadIndex,表示链表头部的第一个Index,它继承于Index:
1 static final class HeadIndex<K,V> extends Index<K,V> { 2 final int level; 3 HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) { 4 super(node, down, right); 5 this.level = level; 6 } 7 }
level表示第几层,这样一个index包含有Node,向下的引用,向右的引用,第几层,通过这些条件就能准确的定位元素的位置了。对于跳表的所有操作,就是组织好这些Index之间的连接关系。
跳表的特点:
❤ 跳表的查询时间复杂度是O(log n);
❤ 随机算法;
❤ 跳表内所有链表的元素都是排序的;
❤ 采用CAS算法,保证线程安全。
参考:《Java高并发程序设计》 葛一鸣 郭超 编著: