- 1、余弦相似度
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。

上图两个向量a,b的夹角很小可以说a向量和b向量有很高的的相似性,极端情况下,a和b向量完全重合。如下图:

如上图可以认为a和b向量是相等的,也即a,b向量代表的文本是完全相似的,或者说是相等的。如果a和b向量夹角较大,或者反方向,可以说a向量和b向量有很低的的相似性,或者说a和b向量代表的文本基本不相似。
向量a和向量b的夹角 的余弦计算如下:
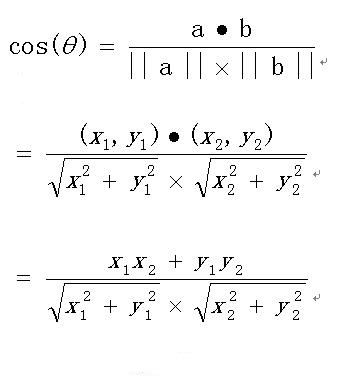
扩展,如果向量a和b不是二维而是n维,上述余弦的计算法仍然正确。假定a和b是两个n维向量,a是 ,b是 ,则a与b的夹角 的余弦等于:
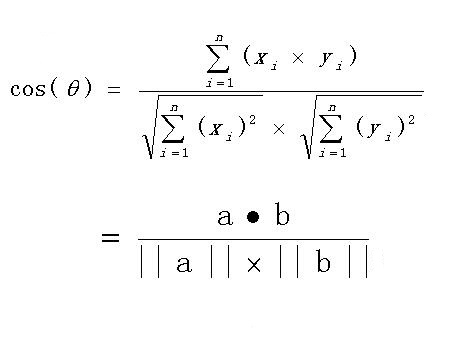
- 2、如下举例说明利用余弦计算句子相似度
句子A:这只皮靴号码大了。那只号码合适
句子B:这只皮靴号码不小,那只更合适
怎样计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:这只/皮靴/号码/大了。那只/号码/合适。
句子B:这只/皮靴/号码/不/小,那只/更/合适。
第二步,列出所有的词。
这只,皮靴,号码,大了。那只,合适,不,小,更
第三步,计算词频。(下面程序用的jieba分词工具所以结果不一样但不影响计算)
句子A:这只1,皮靴1,号码2,大了1。那只1,合适1,不0,小0,更0
句子B:这只1,皮靴1,号码1,大了0。那只1,合适1,不1,小1,更1
第四步,写出词频向量。
句子A:(1,1,2,1,1,1,0,0,0)
句子B:(1,1,1,0,1,1,1,1,1)
第五步,利用上述公式计算
- 3、python代码实现
1 # -*- coding: utf-8 -*- 2 """ 3 Created on Mon Jul 30 09:35:54 2018 4 5 @author: Administrator 6 """ 7 8 import jieba 9 import numpy as np 10 11 def get_word_vector(): 12 """ 13 w = np.ones((3,4)) 14 q = np.ones((3,4")) 15 print(w) 16 print(np.sum(w * q)) 17 """ 18 19 s1 = input("句子1:") 20 s2 = input("句子2:") 21 22 cut1 = jieba.cut(s1) 23 cut2 = jieba.cut(s2) 24 25 list_word1 = (','.join(cut1)).split(',') 26 list_word2 = (','.join(cut2)).split(',') 27 print(list_word1) 28 print(list_word2) 29 30 key_word = list(set(list_word1 + list_word2))#取并集 31 print(key_word) 32 33 word_vector1 = np.zeros(len(key_word))#给定形状和类型的用0填充的矩阵存储向量 34 word_vector2 = np.zeros(len(key_word)) 35 36 for i in range(len(key_word)):#依次确定向量的每个位置的值 37 for j in range(len(list_word1)):#遍历key_word中每个词在句子中的出现次数 38 if key_word[i] == list_word1[j]: 39 word_vector1[i] += 1 40 for k in range(len(list_word2)): 41 if key_word[i] == list_word2[k]: 42 word_vector2[i] += 1 43 44 print(word_vector1)#输出向量 45 print(word_vector2) 46 return word_vector1, word_vector2 47 48 def cosine(): 49 v1, v2 = get_word_vector() 50 return float(np.sum(v1 * v2))/(np.linalg.norm(v1) * np.linalg.norm(v2)) 51 52 print(cosine())
- 4、运行结果
