一、什么是Hbase
一种特殊的数据库,nosql(非关系型数据库)、分布式。
数据的最终持久化存储基于HDFS,存储容量支持在线扩容。
支持实时操作数据:增删改查
是一种基于列的数据库
二、Hbase特性
2-1 表的逻辑结构
Hbase表包括:表名 行键(rowkey) 列族
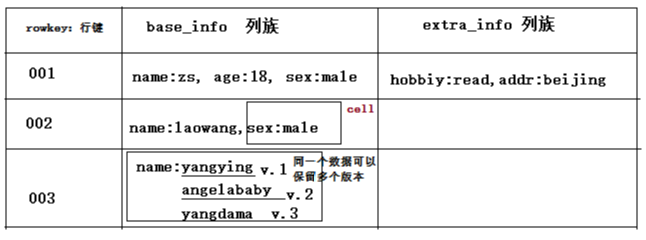
rowkey决定了哪一行,列族决定了哪几列。
列族中数据以key-value形式存储,一个键值对称一个cell
同一个列族中的可以包含的列的数量和列的key都不固定。
同一个数据可以保留多个版本
2-2 Hbase工作机制及存储结构
Hbase是一种分布式数据库,服务器搭建在集群之上,多个请求被分配到不同的服务器上。请求的划分是通过region来区分的。
Hbase服务器仅仅负责完成增删改查的逻辑,不负责数据存储。一个hbase服务器叫一个region server,一个regionserver可以管理多个region。
Hbase集群中的角色:
region server :管理自己所负责的region数据的读写,负责接收并执行数据的增删改查请求,读写hdfs,受master调度。可以有多个,视region的数量和数据量而定。
除了存储表中数据,还存储表的元数据(如哪个region存在哪个region server上,即索引信息)。这个元数据也存储在一个meta_region中,这个meta_region在哪个region server中呢?zk记录。
master:负责调度和存储region与region server的对应关系,监控region server健康状态。不负责接受请求进行查询(不与请求客户端节点通信)。例如,如果有region server宕机,则把其负责的region分配给其他region server。master节点存在单点故障问题,通过HA进行解决,一个active ,一个standby。Admin职能:创建、删除、修改Table的定义。实现DDL操作(namespace和table的增删改,column familiy的增删改等)。管理namespace和table的元数据(实际存储在HDFS上)
zookeeper:master通过zk监控region server的状态。
HDFS:负责数据的存储
HDFS中表的存储结构
Hbase的数据存储在HDFS中,数据存储按照列族来分,一个存储目录示例:
/hbase/库目录/表目录/region1/列族1/数据文件
…… /列族2/数据文件
/region2/
数据的存储类型:存储的是二进制数组byte[] ,包括了rowkey、key、value、列族、表名等。
Hbase中的数据是有序的,先按rowkey排序,然后按照列名的key的字典序排序。
数据的存储过程:
每个region在region server中先存入内存,缓存写满时持久化到HDFS。其实,如果数据量较小的话,会在region server中存储一些热数据(最近访问)。
如果宕机,数据还没持久化到HDFS怎么办?在写数据的时候会把数据操作写到日志中,一旦宕机,通过日志进行恢复。
那么又要如何区分数据是否已经持久化到HDFS中了呢?
参考另一篇,布隆过滤器。
数据查询时的路由过程:
1、客户端先到zk上查询meta 表所在的 redion server
2、到meta 表查询自己需要的数据所在的region server
3、到目标region server请求自己的数据。
客户端查询数据时经过zk 和 region server,与master无关。
布隆过滤器:
从爬虫说起,为防止爬去重复url,通过hash算法,把urlbian'cehng
判断是否已经爬过,如果1的位置相同,可能爬过,位置不同,一定没有爬过,
三、操作HBase
3-1 建表
create 't_表名','列族1','列族2'
3-2 插入数据
进入hbase命令行
put 't_表名','rowkey','列族1:key','value'
eg:
hbase(main):011:0> put 't_user_info','001','base_info:username','zhangsan' 0 row(s) in 0.2420 seconds hbase(main):012:0> put 't_user_info','001','base_info:age','18' 0 row(s) in 0.0140 seconds hbase(main):013:0> put 't_user_info','001','base_info:sex','female' 0 row(s) in 0.0070 seconds hbase(main):014:0> put 't_user_info','001','extra_info:career','it' 0 row(s) in 0.0090 seconds
3-3 数据查询
1、scan 扫描表
hbase(main):017:0> scan 't_user_info' ROW COLUMN+CELL 001 column=base_info:age, timestamp=1496567924507, value=18 001 column=base_info:sex, timestamp=1496567934669, value=female 001 column=base_info:username, timestamp=1496567889554, value=zhangsan 001 column=extra_info:career, timestamp=1496567963992, value=it 002 column=base_info:username, timestamp=1496568034187, value=liuyifei 002 column=extra_info:career, timestamp=1496568008631, value=actoress 2 row(s) in 0.0420 seconds
2、get 获取单行数据
hbase(main):020:0> get 't_user_info','001' COLUMN CELL base_info:age timestamp=1496568160192, value=19 base_info:sex timestamp=1496567934669, value=female base_info:username timestamp=1496567889554, value=zhangsan extra_info:career timestamp=1496567963992, value=it 4 row(s) in 0.0770 seconds
3-4
3-1DDL 数据定义
- 创建表
1、构造与Hbase配置对象,以配置文件为参数构造Hbase连接对象(这个连接对象可以是公用的
2、从连接中构造一个DDL操作器Admin类对象
3、创建表定义描述对象HTableDescriptor类对象、
4、创建列族定义描述对象HColumnDescriptor ,通过列族定义描述对象可以设置数据的最大版本数等(最大默认是1)
5、将列族添加到表中
6、用DDL操作器对象admin,来建表
7、关闭admin,关闭conn
- 删除表
3-2 DML 数据操作
1、构造与Hbase配置对象,以配置文件为参数构造Hbase连接对象(这个连接对象可以是公用的
2、从连接中构造一个DDL操作器Admin类对象
3、停用表
4、删除表
- 修改表定义(新增一个列族)
1、构造与Hbase配置对象,以配置文件为参数构造Hbase连接对象(这个连接对象可以是公用的
2、从连接中构造一个DDL操作器Admin类对象
3、取出表的定义信息
4、新构造一个列族定义
并通过列族定义设置该列族的布隆过滤器类型
5、将列族定义添加到表定义对象
6、将修改过的表定义交给admin提交


public void testAlterTable() throws Exception{ Admin admin = conn.getAdmin(); // 取出旧的表定义信息 HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("user_info")); // 新构造一个列族定义 HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("other_info"); hColumnDescriptor.setBloomFilterType(BloomType.ROWCOL); // 设置该列族的布隆过滤器类型 // 将列族定义添加到表定义对象中 tableDescriptor.addFamily(hColumnDescriptor); // 将修改过的表定义交给admin去提交 admin.modifyTable(TableName.valueOf("user_info"), tableDescriptor); admin.close(); conn.close(); }
补充:布隆过滤器