一、Zookeeper是什么?
Zookeeper是一种高效可靠的协同工作系统,它是一个基础组件,是一种服务组件,可以应用于各种场景。它可以提供的功能主要包括两个:
1、为Zookeeper的客户端(即任意使用zk的用户)管理少量数据,它存储的数据是<key, value>形式,key的格式类似目录结构,eg. /aa "hello" /aa/test "world"
2、为客户端监听指定数据节点的状态,并在数据节点发生变化时,把变化通知给客户端。
知道了它可以提供的功能,要用它做什么全看你怎么用。
二、Zookeeper可以怎么用?
2-1 集群管理
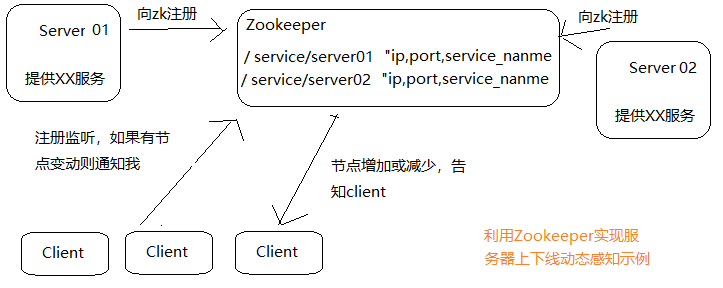
一个典型的应用就是服务器的上下线动态感知:在一个Server/Client的系统中,客户端向一个服务端发起请求,如果请求过多,一个服务进程不能满足需求,那就需要增加服务,并告知Client感知服务增加。一个解决方案:
利用Zookeeper,服务端程序向Zookeeper进行注册;客户端在向服务器发起请求前,先去Zookeeper查询可用的服务,根据可用服务信息再去发起请求。另外,客户端可以向Zookeeper注册监听,告诉Zookeeper对节点进行监听,如果有子节点发生了改变,就通知客户端
2-2 配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
注,这里只是列出几个使用思路,并不是zk提供的全部功能。
三、zookeeper的数据存储机制
3-1 数据的存储形式
Zookeeper的数据存储采用的是结构化存储,结构化存储是没有文件和目录的概念,里边的目录和文件被抽象成了节点(node),zookeeper里可以称为znode。
zookeeper中对用户的数据采用kv形式存储,只是zk有点特别:
key:是以路径的形式表示的,意味着,各key之间有父子关系,比如
/ 是顶层key
用户建的key只能在/ 下作为子节点,比如建一个key: /aa 这个key可以带value数据
也可以建一个key: /bb
也可以建key: /aa/xx
zookeeper中,对每一个数据key,称作一个znode
综上所述,zk中的数据存储形式如下:

3-2 znode类型
zookeeper中的znode有多种类型:
1、PERSISTENT 持久的:创建者就算跟集群断开联系,该类节点也会持久存在与zk集群中
2、EPHEMERAL 短暂的:创建者一旦跟集群断开联系,zk就会将这个节点删除
3、SEQUENTIAL 带序号的:这类节点,zk会自动拼接上一个序号,而且序号是递增的
组合类型:
PERSISTENT :持久不带序号
EPHEMERAL :短暂不带序号
PERSISTENT 且 SEQUENTIAL :持久且带序号
EPHEMERAL 且 SEQUENTIAL :短暂且带序号
四、zookeeper的监听机制
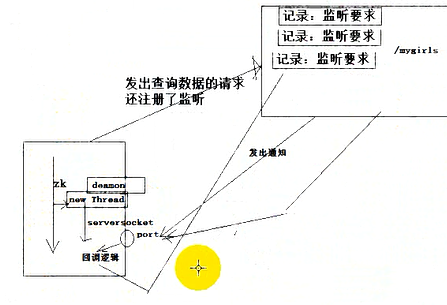
创建zk对象的时候启动两个线程,一个线程用于收发数据 +一个线程用于监听(守护线程)(实际是一个serversocket)。
客户端对zk查数据的时候,如果注册了监听;zk记录监听要求;当节点发生变化时,zk向客户端监听线程的端口发出通知(一次注册监听仅通知一次);zk客户端调用回调逻辑(watcher)。
五、Zookeeper怎么部署?
5-1 部署
1、官网下载zookeeper放到机器上,解压
2、复制$zookeeperhome/conf下zoo_sample.cfg为zoo.cfg,并修改内容
cp zoo_sample.cfg zoo.cfg vi zoo.cfg
修改文件中内容:
dataDir=/tmp/zookeeper,修改为你想要存储数据的位置,我的修改成了 dataDir=/home/zkdata
文件末尾添加集群中的机器以及机器ip port,如:
server.0=hadoop-0:2888:3888 server.1=hadoop-1:2888:3888 server.2=hadoop-2:2888:3888
3、将配置过的安装包拷贝给集群中节点
4、到每个机器上创建目录(刚才配置的dataDir)并在文件夹中创建文件myid,文件内容分别为0.1.2(与zoo.cfg文件末尾中添加的server.0等一致)
5、启动zookeeper集群:
bin/zkServer.sh start
此时查看进程,虽然有QuorumPeerMain但是还没正常工作,因为只启动了一个节点
[root@hadoop-0 zookeeper]# jps 6305 DataNode 11382 Jps 6216 NameNode 11336 QuorumPeerMain 6889 NodeManager 6795 ResourceManager
查看状态
[root@hadoop-0 zookeeper]# bin/zkServer.sh status JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Error contacting service. It is probably not running.
[root@hadoop-0 zookeeper]# ./bin/zkServer.sh status JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Mode: leader
注,为避免重复操作,可以写脚本登陆到其他节点进行配置。
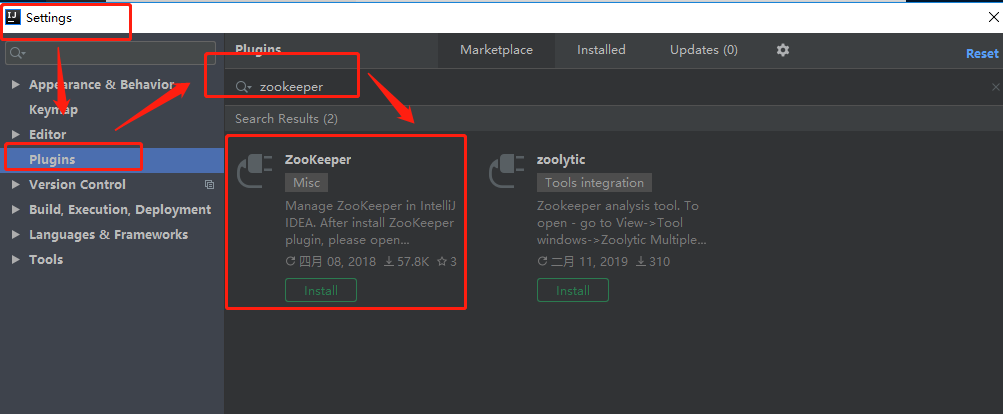
5-2 idea可视化插件安装
Zookeeper使用
Zookeeper客户端提供两种zk的访问方式:命令行方式 和 java api方式