一、MapReduce编程思想
学些MapRedcue主要是学习它的编程思想,在MR的编程模型中,主要思想是把对数据的运算流程分成map和reduce两个阶段:
Map阶段:读取原始数据,形成key-value数据(map方法)。即,负责数据的过滤分发。
Reduce阶段:把map阶段的key-value数据按照相同的key进行分组聚合(reduce方法)。即,数据的计算归并。
它其实是一种数据逻辑运算模型,对于这样的运算模型,有一些成熟的具体软件实现,比如hadoop中的mapreduce框架、spark等,例如在hadoop的mr框架中,对map阶段的具体实现是map task,对reduce阶段的实现是reduce task。这些框架已经为我们提供了一些通用功能的实现,让我们专注于数据处理的逻辑,而不考虑分布式的具体实现,比如读取文件、写文件、数据分发等。我们要做的工作就是在这些编程框架下,来实现我们的具体需求。
下面我们先介绍一些map task和reduce task中的一些具体实现:
二、MapTask和ReduceTask
2.1 Map Task
读数据:利用InputFormat组件完成数据的读取。
InputFormat-->TextInputFormat 读取文本文件的具体实现
-->SequenceFileInputFormat 读取Sequence文件
-->DBInputFormat 读数据库
处理数据:这一阶段将读取到的数据按照规则进行处理,生成key-value形式的结果。maptask通过调用用Mapper类的map方法实现对数据的处理。
分区:这一阶段主要是把map阶段产生的key-value数据进行分区,以分发给不同的reduce task来处理,使用的是Partitioner类。maptask通过调用Partitioner类的getPartition()方法来决定如何划分数据给不同的reduce task。
排序:这一阶段,对key-value数据做排序。maptask会按照key对数据进行排序,排序时调用key.compareTo()方法来实现对key-value数据排序。
2.2 Reduce Task
读数据:这一阶段通过http方式从maptask产生的数据文件中下载属于自己的“区”的数据。由于一个区的数据可能来自多个maptask,所以reduce还要把这些分散的数据进行合并(归并排序)
处理数据:一个reduce task中,处理刚才下载到自己本地的数据。通过调用GroupingComparator的compare()方法来判断文件中的哪些key-value属于同一组。然后将这一组数传给Reducer类的reduce()方法聚合一次。
输出结果:调用OutputFormat组件将结果key-value数据写出去。
Outputformat --> TextOutputFormat 写文本文件(会把一个key-value对写一行,分隔符为制表符
--> SequenceFileOutputFormat 写Sequence文件(直接将key-value对象序列化到文件中)
--> DBOutputFormat
下面介绍下利用MapReduce框架下的一般编程过程。我们要做的 工作就是把我们对数据的处理逻辑加入到框架的业务逻辑中。我们编写的MapReduce的job客户端主要包括三个部分,Mapper 、 Reducer和JobSubmitter,三个部分分别完成MR程序的map逻辑、reduce逻辑以及将我们编写的job程序提交给集群。下面分别介绍这三个部分如何实现。
三、Hadoop中MapReduce框架下的一般编程步骤
Mapper:创建类,该类要实现Mapper父类,复写read()方法,在方法内实现当前工程中的map逻辑。
Reducer:创建类,继承Reducer父类,复写reduce()方法,方法内实现当前工程中的reduce逻辑。
jobSubmitter:这是job在集群上实际运行的类,主要是通过main方法,封装job相关参数,并把job提交。jobsubmitter内一般包括以下操作
step1:创建Configuration对象,并通过创建的对象对集群进行配置,同时支持用户自定义一些变量并配置。这一步有些像我们集群搭建的时候对$haoop_home/etc/hadoop/*下的一些文件进行的配置。
step2:获得job对象,并通过job对象对我们job运行进行一些配置。例如,设置集群运行的jar文件、设置实际执行map和reduce的类等,下面列出一些必要设置和可选设置。
Configuration conf = new Configuration(); //创建集群配置对象。 Job job = Job.getInstance(conf);//根据配置对象获取一个job客户端实例。 job.setJarByClass(JobSubmitter.class);//设置集群上job执行的类 job.setMapperClass(FlowCountMapper.class);//设置job执行时使用的Mapper类 job.setReducerClass(FlowCountReducer.class);//设置job执行时使用的Reducer类 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileInputFormat.setInputPaths(job, new Path("I:\hadooptest\input")); FileOutputFormat.setOutputPath(job, new Path("I:\hadooptest\output_pri")); //设置maptask做数据分发时使用的分发逻辑类,如果不指定,默认使用hashpar job.setPartitionerClass(ProvincePartitioner.class); job.setNumReduceTasks(4);//自定义的分发逻辑下,可能产生n个分区,所以reducetask的数量需要是n boolean res = job.waitForCompletion(true); System.exit(res ? 0:-1);
一般实践中,可以定义一个类,其中添加main方法对job进行提交,并在其中定义静态内部类maper和reduce类。
四、MapReduce框架中的可自定义项
<不小心删除以后就没有再补充了,挺重要的。。。。补上吧。。。。>
总结,你要把bean写到文本吗?重写toString方法
要传输吗?实现Writable接口
要排序吗?实现writablecompareble接口
遇到一些复杂的需求,需要我们自定义实现一些组件
2.1 自定义序列化数据类型
MapReduce框架为我们提供了基本数据类型的序列化类型,如String的Text类型,int的IntWritalbe类型,null的NullWritable类型等。但是有时候会有一些我们自定义的类型需要我们在map和reduce之间进行传输或者需要写到hdfs上。hadoop提供了自己的序列化机制,实现自定义类型的序列化和反序列化将自定义的类实现hadoop提供的Writable接口。
自定义类实现Writable接口,实现readFields(in) 和write(out)方法。
同时,重写toString()方法,可以自定义在写到文件系统时候写入的字段内容。


* hadoop系统在序列化该类的对象时要调用的方法 */ @Override public void write(DataOutput out) throws IOException { out.writeInt(upFlow); out.writeUTF(phone); out.writeInt(dFlow); out.writeInt(amountFlow); } /** * hadoop系统在反序列化该类的对象时要调用的方法 */ @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readInt(); this.phone = in.readUTF(); this.dFlow = in.readInt(); this.amountFlow = in.readInt(); } @Override public String toString() { return this.phone + ","+this.upFlow +","+ this.dFlow +"," + this.amountFlow; }
2.2 自定义排序规则
MapReduce中提供了一个排序机制,map worker 和reduce worker ,都会对数据按照key的大小来排序,所以map和reduce阶段输出的记录都是经过排序的(按照key排序)。我们在实践中有时候需要对计算出来的结果进行排序,比如一个这样的需求:计算每个页面访问次数,并按照访问量倒序输出。我们可以在统计了每个页面访问次数之后进行排序,但是我们还可以直接应用MR自身的排序特性,在MR处理的时候按照我们的需求进行排序。这时候就需要我们自定义排序规则。
自定义类,实现WritableComparable接口,实现其中的compareTo()方法,在其中自定义排序的规则。同时一般还要实现readFields(in) 和write(out)和toString()方法。
public class PageCount implements WritableComparable<PageCount>{ private String page; private int count; public void set(String page, int count) { this.page = page; this.count = count; } public String getPage() { return page; } public void setPage(String page) { this.page = page; } public int getCount() { return count; } public void setCount(int count) { this.count = count; } @Override public int compareTo(PageCount o) { return o.getCount()-this.count==0?this.page.compareTo(o.getPage()):o.getCount()-this.count; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(this.page); out.writeInt(this.count); } @Override public void readFields(DataInput in) throws IOException { this.page= in.readUTF(); this.count = in.readInt(); } @Override public String toString() { return this.page + "," + this.count; } }
总结:
实现Writable接口,是为了bean能够传输,能够写到文件系统中。
实现WritableComparable还为了bean能够按照你定义的规则进行排序。
2.2 自定义分区规则
我们知道,map计算出来的结果会分发给不同的reduce任务去进一步处理。MR中提供了一个默认的数据分发规则,会按照map的输出中的key的hashcode,然后模除reduce task的数量,模除的结果就是数据的分区。我们可以通过自定义map数据分发给reduce的规则,实现把数据按照自己的需求记录到不同的数据中。比如实现这样的需求,有一个通话记录的文件,按照归属地分别存储数据。
自定义类,继承Partitioner父类(类的泛型为MapTask的输出的key,value的类型),重写 getPartition(<>key, <>value, int numPartitions) 方法,在其中自定义分区的规则,方法返回计算出来的分区数。MapTask每处理一行数据都会调用getPartition方法。因此最好不要在方法中创建可以给很多数据行共同使用的对象。在jobsubmitter中,设置maptask在做数据分区时使用的分区逻辑类, job.setPartitonerClass(your.class) ,同时注意设置reduceTask的任务数量为我们在分区逻辑中定义的规则下回产生的分区数量, job.setNumReduceTasks(numOfPartition);
/** * 本类是提供给MapTask用的 * MapTask通过这个类的getPartition方法,来计算它所产生的每一对kv数据该分发给哪一个reduce task * @author ThinkPad * */ public class ProvincePartitioner extends Partitioner<Text, FlowBean>{ static HashMap<String,Integer> codeMap = new HashMap<>(); static{ codeMap.put("135", 0); codeMap.put("136", 1); codeMap.put("137", 2); codeMap.put("138", 3); codeMap.put("139", 4); } @Override public int getPartition(Text key, FlowBean value, int numPartitions) { Integer code = codeMap.get(key.toString().substring(0, 3)); return code==null?5:code; } }
public class JobSubmitter { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(JobSubmitter.class); job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 设置参数:maptask在做数据分区时,用哪个分区逻辑类 (如果不指定,它会用默认的HashPartitioner) job.setPartitionerClass(ProvincePartitioner.class); // 由于我们的ProvincePartitioner可能会产生6种分区号,所以,需要有6个reduce task来接收 job.setNumReduceTasks(6); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); FileInputFormat.setInputPaths(job, new Path("F:\mrdata\flow\input")); FileOutputFormat.setOutputPath(job, new Path("F:\mrdata\flow\province-output")); job.waitForCompletion(true); } }
2.3 自定义分组规则
MapTask每调用一次map就会产生一个k-v,多次调用后,生成多个k-v,具有相同key的的记录称为一组,会存入一个partition中,注意一个patition可以包含多个组。
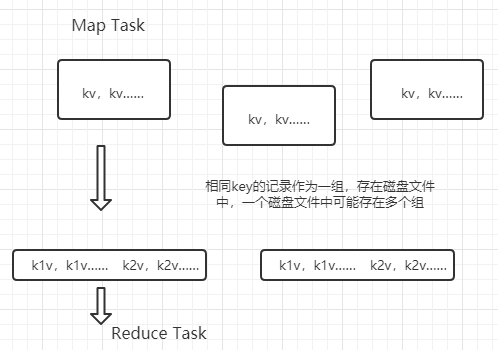
一个ReduceTask处理一个partition,在处理的时候 ,按照key的顺序进行。调用一次reduce会聚合一组数据,就是reduce方法中传入的一个Itetor。为了确认一个分区中的两条记录是不是同一个组,会调用一个工具类GroupingCompatator的compare(01,02)方法,用来判断两个key是否相同,如果两个key相等,则为同一组。利用这样的机制,我们可以自定义一个分组规则。
自定义类,实现 WritableComparator 类,实现 compare 方法,在其中告知MapTask如何判断两个 记录是不是属于同一个组。调用父类构造函数,指定比较的类。
public class OrderIdGroupingComparator extends WritableComparator { pbulic OrderIdGroupingComparator(){ //通过构造函数指定要比较的类 super(OrderBean.class, true);// } @Override public int compare(WritableComparable a, WritableComparable b) { //参数中将来会传入我们自定义的继承了WritableComparable的bean,把a、b向下转型为我们自定义类型的bean,才能比较a和b OrderBean o1 = (OrderBean)a; OrderBean o2 = (OrderBean)b; return o1.getOrderId().compareTo(o2.getOrderID);//id相同就是同一组 } }
在jobSubmiter中指定分组规则,
job.setGroupingComparatorClass(OrderIdGroupingComparator.class);
注意:关于区分分区和分组:
分区比分组的范围更加大。分区是指,在map task结束之后,中间结果数据会被分给哪些reduce task,而分组是指,同一个分区中(即一个reduce task处理的数据中)数据的分组。在默认的计算分区的方法中,不同key的hash code对reduce task取模计算出来的结果可能相同,这样的数据会被分到同一个分区;这一个分区中的key的haashcode不同,这样就在一个区中分了不同组。
那么什么时候使用分区,什么时候使用分组呢?
再如在计算每个订单中总金额最大的3笔中的案例中,可以考虑进行倒序排序,然后取前三;按照id进行倒序排序吗?不现实,因为订单id太多,不可能启动那么多的reduce task。那么就要把多个订单的数据存储到第一个分区中,同时保证同一个订单的数据全部在一个分区中,这时候,就需要自定义分区规则(保证同一订单中的数据在同一个分区),但是又要分组排序,所以这时候就需要自定义分组规则(保证该分区中同一订单在一组,不同订单在不同组)
2.3自定义MapTask的局部聚合规则
默认情况下,map计算的结果逐条保存到磁盘中,传输给reduce之后也是分条的记录,这样可能造成一个问题就是如果某个分区下的数据较多,而有的分区下数据较少,就导致出现reduce task之间任务量差距较大,即出现数据倾斜的情况。一个解决办法是在形成map结果文件的时候进行一次局部聚合。
使用Combiner组件可以实现在每个MapTask中对数据进行一次局部聚合。这个局部聚合的逻辑其实和Reducer的逻辑是一样的,都是对map计算出的kv数据进行聚合,只不过如果是maptask来调用我们定义的Reducer实现类,则聚合的是当前这个maptask运行的结果,如果是reducetask来调用我们定义的Reducer实现类,则聚合的是全部maptask的运行结果。
定义类局部聚合类XXCombationer,继承Rducer,复写reduce方法,在方法中实现具体的聚合逻辑;在jobSubmitter的job中设置mapTask端的局部聚合类为我们定义的类 job.setCombinerClass(XXCombiner.class) 。
2.4 控制输入输出格式。。。

五、MR程序的调试、执行方式

5.1 提交到linux运行
5.2 Win本地执行