参考:https://blog.csdn.net/chang384915878/article/details/86747419
一、准备知识
这里只是简单的介绍,详情可以看我的另一篇博客:https://www.cnblogs.com/JimShi/p/11309651.html
elasticsearch设计的理念就是分布式搜索引擎,底层实现还是基于Lucene的,核心思想是在多态机器上启动多个es进程实例,组成一个es集群。了解几个概念:
1、接近实时
es是一个接近实时的搜索平台,这就意味着,从索引一个文档直到文档能够被搜索到有一个轻微的延迟
2、集群(cluster)
一个集群有多个节点(服务器)组成,通过所有的节点一起保存你的全部数据并且通过联合索引和搜索功能的节点的集合,每一个集群有一个唯一的名称标识
3、节点(node)
一个节点就是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群和搜索功能,一个节点可以通过配置特定的名称来加入特定的集群,在一个集群中,你想启动多少个节点就可以启动多少个节点。
4、索引(index)
一个索引就是还有某些共有特性的文档的集合,一个索引被一个名称唯一标识,并且这个名称被用于索引通过文档去执行搜索,更新和删除操作。
5、类型(type)
type 在6.0.0已经不赞成使用
为什么不使用?https://www.cnblogs.com/JimShi/p/11309651.html
6、文档(document)
一个文档是一个基本的搜索单元
二、如何实现分布式
1、分片
Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因是为了保证分布式环境下的高可用,同时也扩大了存储空间。es也是master-slave架构,在 es 中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。值得注意的是,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
具体就是你先建立一个索引,这个索引可以拆分成多个 shard,每个 shard 存储部分数据。这个shard 的数据实际是有多个备份,就是说每个 shard 都有一个 primary shard,负责写入数据,但是还有几个 replica shard。primary shard 写入数据之后,会将数据同步到其他几个 replica shard 上去。
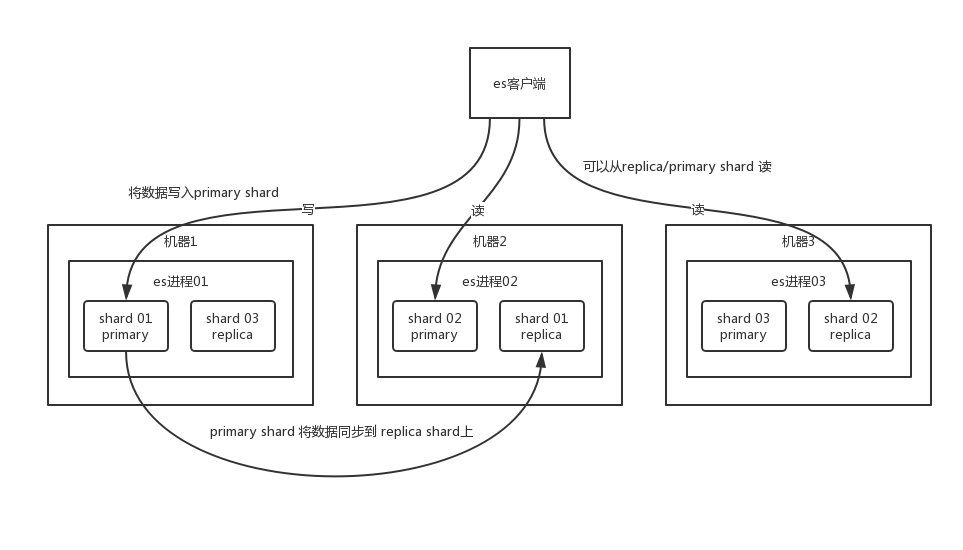
通过这个 replica 的方案,每个 shard 的数据都有多个备份,如果某个机器宕机了,没关系啊,还有别的数据副本在别的机器上呢。高可用了吧。
es 集群多个节点,会自动选举一个节点为 master 节点,这个 master 节点其实就是干一些管理的工作的,比如维护索引元数据、负责切换 primary shard 和 replica shard 身份等。要是 master 节点宕机了,那么会重新选举一个节点为 master 节点。如果是非 master节点宕机了,那么会由 master 节点,让那个宕机节点上的 primary shard 的身份转移到其他机器上的 replica shard。接着你要是修复了那个宕机机器,重启了之后,master 节点会控制将缺失的 replica shard 分配过去,同步后续修改的数据之类的,让集群恢复正常。说得更简单一点,就是说如果某个非 master 节点宕机了。那么此节点上的 primary shard 不就没了。那好,master 会让 primary shard 对应的 replica shard(在其他机器上)切换为 primary shard。如果宕机的机器修复了,修复后的节点也不再是 primary shard,而是 replica shard。
其实上述就是 ElasticSearch 作为分布式搜索引擎最基本的一个架构设计。