本组囊括字符串相关题目,难度不等。
3. Longest Substring Without Repeating Characters
题目描述:中等

想到的第一种思路是暴力解法,遍历数组每次去找最长不重复子串,最后这些子串比长短。时间复杂度太高O(n²)。
此题的模式识别一:看到不含有重复,即只出现一次,一旦涉及出现次数,想到使用散列表
一般来说对于字符串,都是让字符作为键, 出现次数作为值来构建散列表。
模式识别二:字符串涉及子串,考虑滑动窗口解法。
具体做法:以一个左指针从0开始,是指滑动窗口的左边界,依次遍历完字符串,目的是找到每一个以当前字符串为头的最长不重复子串,最后可做比较;
以一个右指针从-1开始,在定了左边界后不断往右滑动,直到出现和窗口中某一数字重复的情况。
在上面的流程中,我们还需要使用一种数据结构来判断是否有重复的字符,常用的数据结构为哈希集合(即 C++ 中的 std::unordered_set,Java 中的 HashSet,Python 中的 set, JavaScript 中的 Set)。在左指针向右移动的时候,我们从哈希集合中移除一个字符,在右指针向右移动的时候,我们往哈希集合中添加一个字符。
解法(二):滑动窗口
1 class Solution: 2 def lengthOfLongestSubstring(self, s: str) -> int: 3 sub = set() 4 ans = 0 5 n = len(s) 6 # 左指针为i,右指针为rk 7 rk = -1 8 for i in range(n): 9 if i != 0: 10 sub.remove(s[i-1]) 11 while rk+1 < n and s[rk+1] not in sub: 12 sub.add(s[rk+1]) 13 rk += 1 14 ans = max(ans, rk-i+1) # 长度为rk-i+1,右边界-左边界+1 15 return ans
14. Longest Common Prefix
题目描述:简单
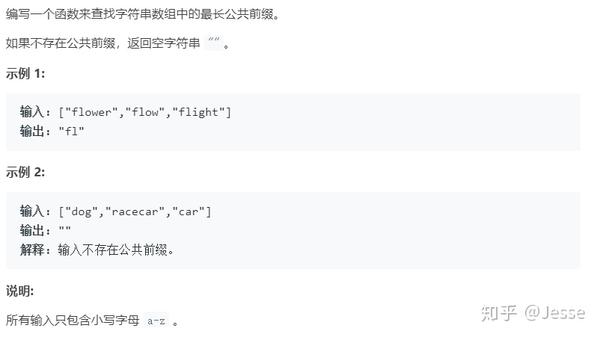
解法(一):横向扫描
采用分治的思想,也就是官方解法一的水平扫描,从左到右依次比较第一个str和下一个str的最长公共前缀;
单独写一个找两个字符串的最长公共前缀的函数,然后递归调用。

1 class Solution: 2 def longestCommonPrefix(self, strs: List[str]) -> str: 3 if len(strs) == 0: 4 return "" 5 elif len(strs) == 1: 6 return strs[0] 7 else: 8 prefix = strs[0] 9 for i in range(1, len(strs)): 10 prefix = self.__twoStringCommonPrefix(prefix, strs[i]) 11 if prefix == "": 12 return prefix 13 14 return prefix 15 16 def __twoStringCommonPrefix(self, s1, s2): 17 n = min(len(s1), len(s2)) 18 for i in range(0, n): 19 if s1[i] != s2[i]: 20 return s1[0:i] # 这里也是包头不包尾 记住! 21 # 注:如果s1[0] != s2[0], 那么返回的s1[0:0]就为""! 22 return s1[0:n]
时间复杂度:O(m*n),其中 m 是字符串数组中的字符串的平均长度,n 是字符串的数量。最坏情况下,字符串数组中的每个字符串的每个字符都会被比较一次。
空间复杂度:O(1)。使用的额外空间复杂度为常数。
解法(二):纵向扫描
方法一是横向扫描,依次遍历每个字符串,更新最长公共前缀。另一种方法是纵向扫描。纵向扫描时,从前往后遍历所有字符串的每一列,比较相同列上的字符是否相同,如果相同则继续对下一列进行比较,如果不相同则当前列不再属于公共前缀,当前列之前的部分为最长公共前缀。
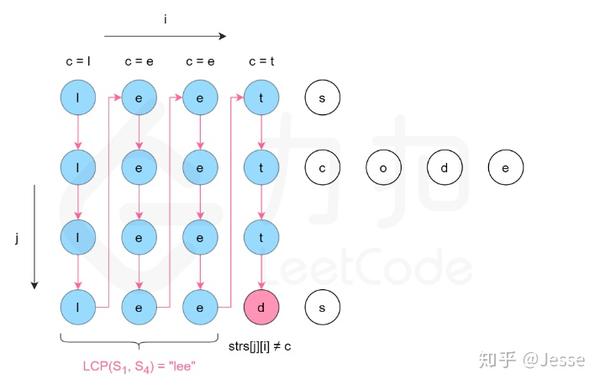
1 class Solution: 2 def longestCommonPrefix(self, strs: List[str]) -> str: 3 if not strs: 4 return "" 5 6 length, count = len(strs[0]), len(strs) 7 for i in range(length): 8 c = strs[0][i] 9 if any(i == len(strs[j]) or strs[j][i] != c for j in range(1, count)): 10 return strs[0][:i] 11 12 return strs[0]
时间复杂度:O(m*n),其中 m 是字符串数组中的字符串的平均长度,n 是字符串的数量。最坏情况下,字符串数组中的每个字符串的每个字符都会被比较一次。
空间复杂度:O(1)。使用的额外空间复杂度为常数。
13. Roman to Integer
题目描述:简单

首先考虑映射问题,可使用哈希表来保存罗马数字对应的十进制数值,以罗马数字为键;
发现规律:从左到右看下罗马数字,可以发现如果右边的数字小于等于左边的数字,则直接加上左边的数字,如果右边数字大于左边的数字,则减去左边的数字,遍历字符串即可,由于最后一位数字右边没有数了,最后直接加上最后一位数字即可。
解法(一):
1 class Solution: 2 def romanToInt(self, s: str) -> int: 3 sum = 0 4 hashmap = {'I':1, 'V':5, 'X':10, 'L':50, 'C':100, 'D':500, 'M':1000} 5 for i in range(len(s)-1): 6 num1 = hashmap[s[i]] 7 num2 = hashmap[s[i+1]] 8 if num2 > num1: 9 sum -= num1 10 else: 11 sum += num1 12 13 sum += hashmap[s[-1]] # 最后一位右边没有数了,直接加上即可 14 return sum