问题
什么是离散化?在SQL Server Analysis Services中如何使用离散化?它的优点和缺点是什么?查看此技巧以了解更多信息。
解
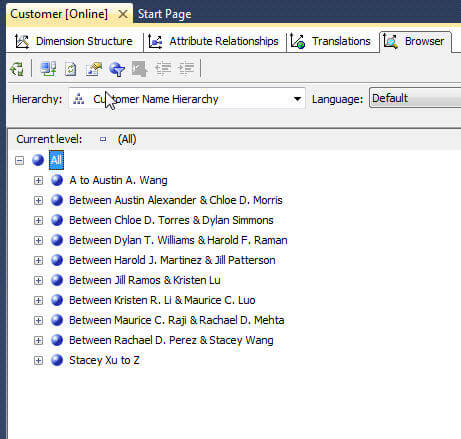
离散化是帮助SSAS开发人员的灵巧工具,尤其是在处理具有大量成员的维属性时。离散化是离散的派生,基本上意味着基于连续的一组值创建离散的一组值。离散化过程允许开发人员获取大量值,并将它们分为定义好的开始值和结束值的不同集合。出现这种情况的一个很好的例子是,从AZ到大批客户。客户列表可以有20,000个不同的客户名称;例如,尝试从20,000个客户的属性成员列表中进行选择可能会导致性能问题,并且仅从列表中进行选择也会有问题。使用离散化可以通过客户名称的首字母将客户划分为不同的组。因此,我们可以有AD,EH,IP,QS和TZ组。现在,选择列表将更易于管理。
对于SSAS,我们可以轻松地使用四个可能的值设置离散化方法属性:1)无,2)自动,3)等面积或4)聚类。自动方法使用相等的面积或群集,并选择SSAS认为是最佳方法。等面积方法尝试将成员列表分为几组,每组中成员数相等。最后,聚类方法使用定义的算法期望最大化(EM)将成员划分为一组通讯组。聚类方法使用一组采样数据点来遍历可能值的列表。即使这样,该方法通常也将需要更多的处理时间。此外,群集方法仅适用于数字列。
此外,如果将离散化方法设置为三个离散化值中的任何一个,则可以设置DiscretizationBucketCount值。DiscretizationBucketCount属性定义了您希望将值分为多少个组。因此,如果将该属性设置为10,将创建10个组。最后,创建的属性组对属性名称使用默认的命名约定。但是,开发人员实际上可以更改默认命名模板,以使用各种可能的替代方法。当然,查看离散化的最佳方法是通过示例。对于本技巧中的示例,我们将使用AdventureWorks 2012 MultiDimensional数据库,该数据库可从Codeplex下载:http : //msftdbprodsamples.codeplex.com/releases/view/55330。
SSAS等面积离散化方法
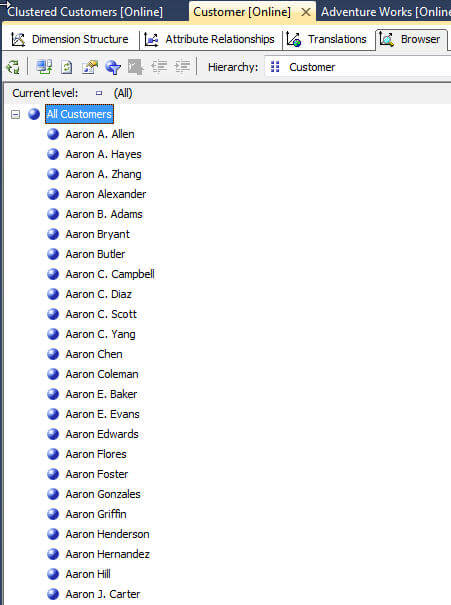
用于离散化的SQL Server Analysis Services等面积方法会将维度属性成员划分为大致相等的组;在AdventureWorks SSAS数据库中使用离散化的一个很好的例子是客户维度,客户属性。看一下下面的屏幕打印,其中显示了客户列表的某些成员。直到浏览器最终要求“查找值”为止,列表还在A内不断出现。不用说,这个列表很大。但是,我们可以使用离散化来调整列表。
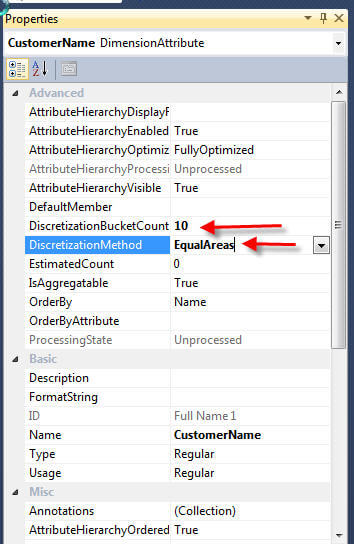
在下面的示例中,我们将离散化方法设置为相等的面积,并将存储桶数设置为10。
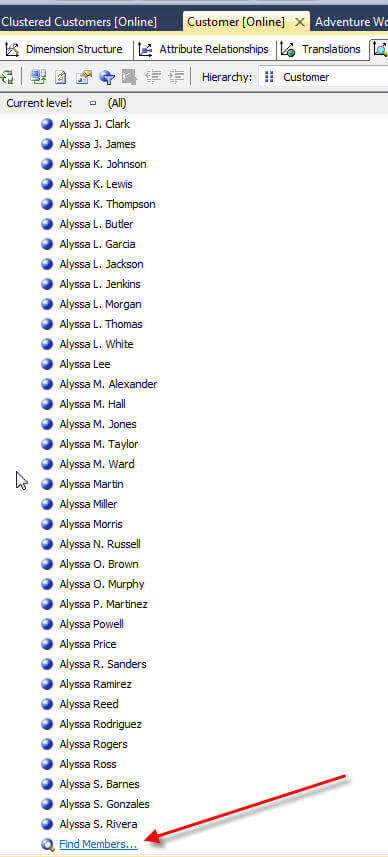
现在我们有一组10个桶。由于客户名称的总数约为18,000,因此每个组包括大约1,800个成员。突围无疑将有助于导航客户名,但是,您可能会说我的详细客户名去了哪里?离散化方法实际上是“接管”属性。为了深入了解各个客户名称,必须再次添加客户全名字段作为新属性,如下所示。
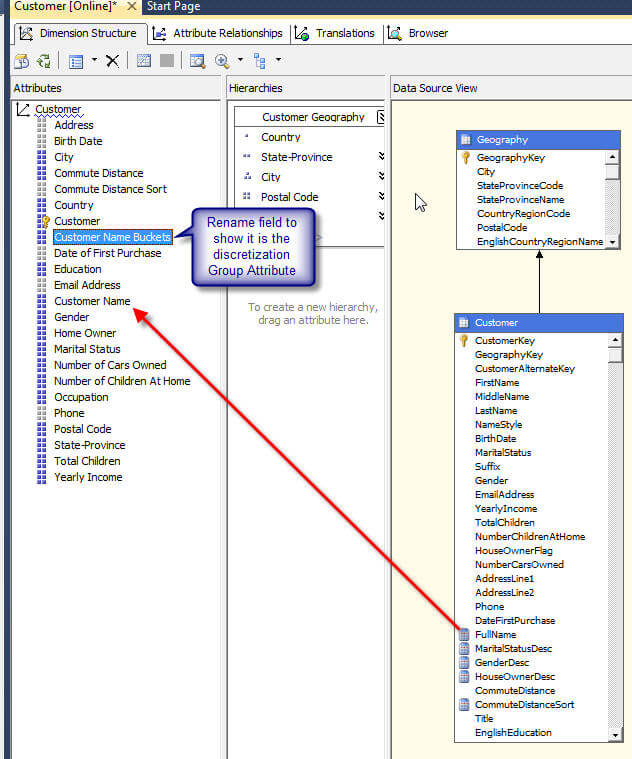
但是,这种设置只能使我们回到最初的问题,因为现在我们有了一个按客户名称分组的属性,以及一个包含所有客户名称的单独属性。为了完成设置过程,我们需要创建一个层次结构,其中组属性位于最高级别,然后将客户名称作为第二级别。该过程如下所示;确保注意通过在“属性关系”选项卡上创建直接关系来解决关系警告。
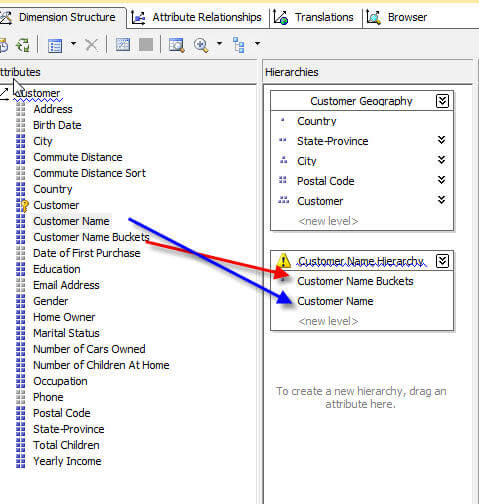
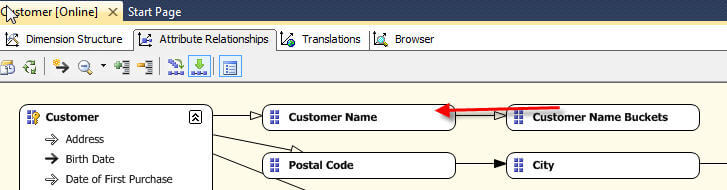
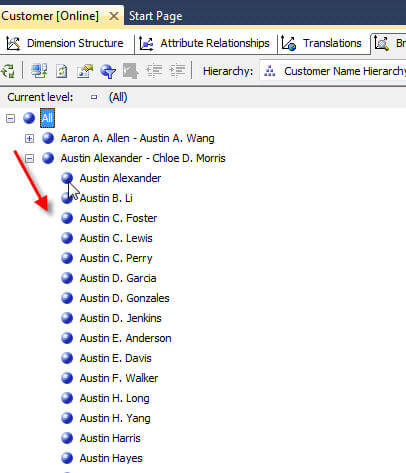
现在,我们可以浏览层次结构,首先浏览到“ Bucket”组,然后浏览到各个客户名称,如下所示。
我们可以为Bucket属性调整的另一项是使用的默认名称。我们可以选择通过调整默认命名格式来调整在组的“从和到”名称中实际显示的内容。为了进行此调整,我们需要首先选择“离散化”属性,在本示例中为“客户名称存储桶”。接下来,在属性窗口中,我们需要在Source Category下展开NameColumn属性。接下来,在format属性中,我们可以添加以下格式字符串:A到%{Last Bucket member};在%{First Bucket成员}和%{Last Bucket成员}之间;%{First Bucket member}到Z。此字符串告诉SSAS:1)将第一个范围命名为“ A到第一个组中的结尾名称” 2)将所有中间组命名为“范围和名称之间
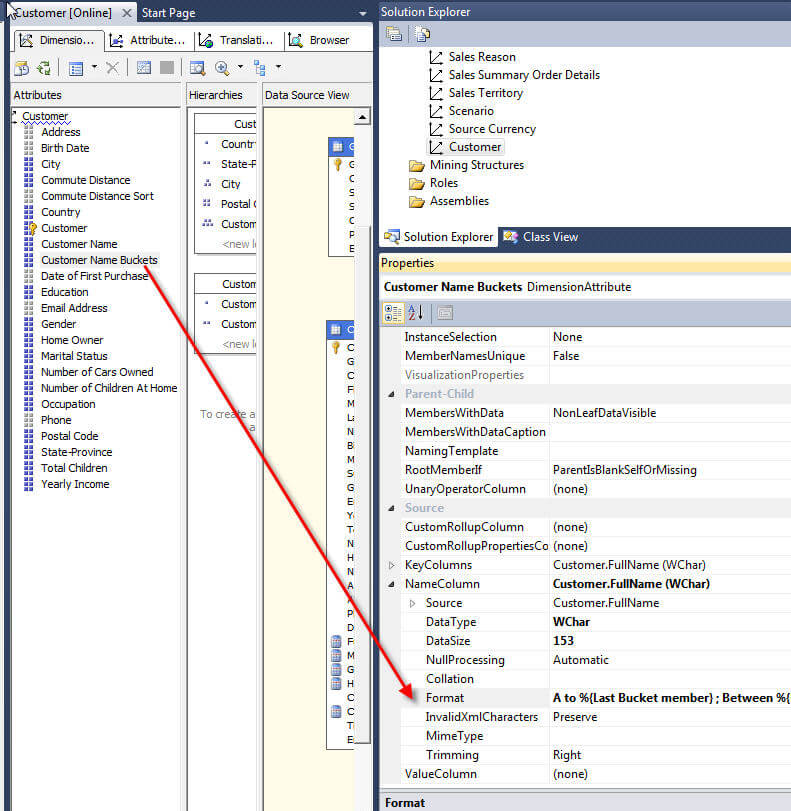
命名格式导致以下分组。请注意,如果默认情况下实际上是通过键设置名称,则实际上是在KeyColumn属性下而不是NameColumn属性下更改了格式(这种情况通常在名称和键相同时发生,因此该属性仅显示键)。
离散化的SSAS聚类方法
用于离散化的SQL Server Analysis Services群集方法使用一种更高级的方法来排列哪些成员属于哪个组。通常,如果您具有复杂的成员值分布,则群集方法可能会对您有所帮助;类似地,对于某些实现,聚类方法可以创建更多的“逻辑”分组。由于此方法只能在数字列上使用,因此在本示例中,我们将切换为使用“年收入”属性。在下面的示例中,我们将离散化方法设置为cluster(聚类),bucket count为10。
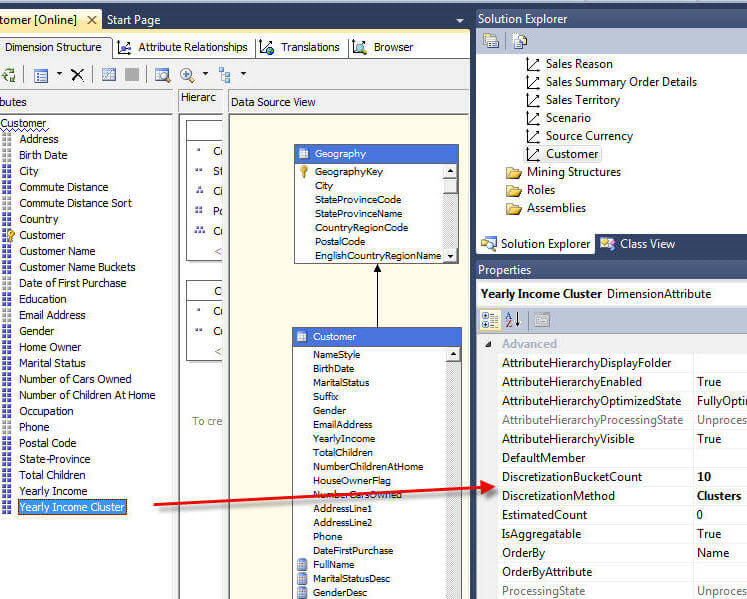
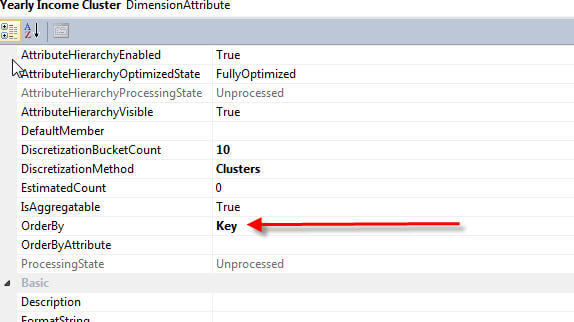
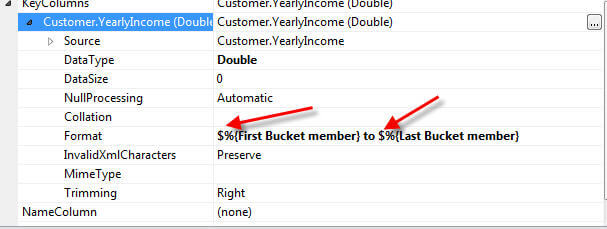
为了完成我们的集群设置,对两个附加属性(如下所示)进行了调整,以更好地反映年收入桶组。首先,要使组保持正确的顺序,将属性OrderBy属性设置为Key。其次,调整命名格式以在组范围名称前面显示一个美元符号。
这些设置将导致接下来显示“年收入群集”组。
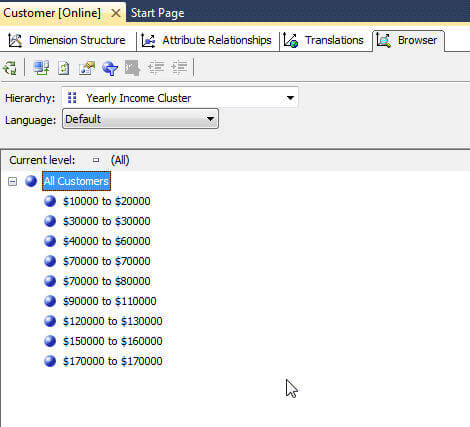
对于收入示例,可能没有必要向下钻取每个收入成员值,因此不会创建从组到详细的层次结构。当然,如果需要,可以创建此层次结构。
SQL Server Analysis Services自动离散化方法
自动离散化方法选择了SSAS认为是最好的方法。设置过程与其他两种方法相同,因此我不会向您展示完整的过程。即便如此,下面的屏幕打印仍显示当年收入群集属性从群集更改为自动并且DiscretizationBucketCount属性设置为0时生成的组。将DiscretizationBucketCount设置为0告诉SSAS确定最合适的分组数。
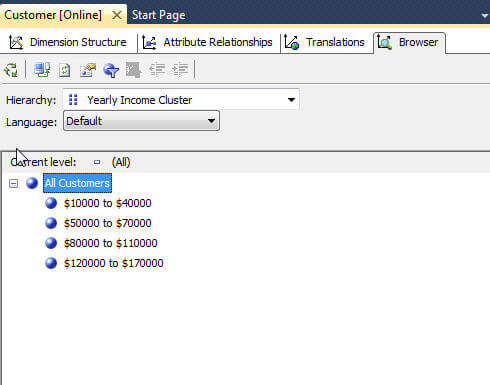
您可以看到SSAS使组的数量非常少。有时,最好让SSAS做出其中一些决定。但是,随着新值的添加,分组当然可以更改。注意第一组和第二组之间的$ 10,000差额。当增加年收入$ 45,000时,该组名将更改。此外,该更改仅在使用“处理完整”处理尺寸时才会发生,这意味着您的多维数据集也将需要重新处理。
结论
SSAS离散化是有用的属性,可用于对包含大量值(例如客户名称)或具有广泛连续值范围(例如收入或财产成员值)的属性进行拆分或分组。离散化过程可以使用聚类方法,等面积方法或自动方法来实现。此外,当使用其中一种方法时,DiscretizationBucketCount字段使我们可以定义要创建的组数。相反,将该值设置为0会告诉SSAS决定最佳的组数。创建我们的组后,可以使用KeyColumn或NameColumn格式属性元素来调整用于组的名称。最后,对于某些组,我们可能仍希望看到详细成员,但是只想将成员分成逻辑组,以便于选择和查看。通过为明细成员添加第二个属性,然后创建一个层次结构,其中离散化属性位于顶层,然后将明细成员属性作为下一级别,可以实现此结果。