一、HTTP概述
HTTP(hypertext transport protocol),即超文本传输协议。这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
HTTP就是一个通信规则,通信规则规定了客户端发送给服务器的内容格式,也规定了服务器发送给客户端的内容格式。客户端发送给服务器的格式叫“请求协议”;服务器发送给客户端的格式叫“响应协议”。
原理:当在浏览器中点击这个链接的时候,浏览器会向服务器发送一段文本,告诉服务器请求打开的是哪一个网页。服务器收到请求后,就返回一段文本给浏览器,浏览器会将该文本解析,然后显示出来。这段文本就是遵循HTTP协议规范的。
二、HTTP1.0和HTTP1.1的区别
HTTP1.0协议中,客户端与web服务器建立连接后,只能获得一个web资源【短连接,获取资源后就断开连接】
HTTP1.1协议,允许客户端与web服务器建立连接后,在一个连接上获取多个web资源【保持连接】
三、请求协议
(一)请求协议的格式如下:
请求首行;【描述客户端的请求方式、请求的资源名称,以及使用的HTTP协议版本号】
请求头信息;【描述客户端请求哪台主机,以及客户端的一些环境信息等】
空行;
请求体
浏览器发送给服务器的内容就这个格式的,如果不是这个格式服务器将无法解读!
(二)请求方式
请求方式有:POST,GET,HEAD,OPTIONS,DELETE,TRACE,PUT。
常用的有:POST,GET
一般来说,当我们点击超链接,通过地址栏访问都是get请求方式。通过表单提交的数据一般是post方式
可以简单理解GET方式用来查询数据,POST方式用来提交数据,get的提交速度比post快
GET方式:在URL地址后附带的参数是有限制的,其数据容量通常不能超过1K。
POST方式:可以在请求的实体内容中向服务器发送数据,传送的数据量无限制。
(三)get方式
GET /hello/index.jsp HTTP/1.1
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.5
Accept-Encoding: gzip, deflate
Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98
//这个位置虽然没有东西,但很重要,它是空行。如果有请求体,那么请求体在空行的下面
1、GET /hello/index.jsp HTTP/1.1:GET请求,请求服务器路径为/hello/index.jsp,协议为1.1;
2、Host:localhost:请求的主机名为localhost;
3、User-Agent: Mozilla/5.0 (**Windows NT 5.1**; rv:5.0) Gecko/20100101 **Firefox/5.0**:与浏览器和OS相关的信息。有些网站会显示用户的系统版本和浏览器版本信息,这都是通过获取User-Agent头信息而来的;
4、Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8:告诉服务器,当前客户端可以接收的文档类型,其实这里包含了*/*,就表示什么都可以接收;
5、Accept-Language: zh-cn,zh;q=0.5:当前客户端支持的语言,可以在浏览器的工具à选项中找到语言相关信息;
6、Accept-Encoding: gzip, deflate:支持的压缩格式。数据在网络上传递时,可能服务器会把数据压缩后再发送;
7、ccept-Charset: GB2312,utf-8;q=0.7,*;q=0.7:客户端支持的编码;
8、Connection: keep-alive:客户端支持的链接方式,保持一段时间链接,默认为3000ms;
9、Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98:因为不是第一次访问这个地址,所以会在请求中把上一次服务器响应中发送过来的Cookie在请求中一并发送去过;这个Cookie的名字为JSESSIONID
(四)post方法
POST /hello/index.jsp HTTP/1.1
Accept: image/gif, image/jpeg, image/pjpeg, image/pjpeg, application/msword, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/x-ms-application, application/x-ms-xbap, application/vnd.ms-xpsdocument, application/xaml+xml, */*
Referer: http://localhost:8080/hello/index.jsp
Accept-Language: zh-cn,en-US;q=0.5
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; InfoPath.2; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: localhost:8080
Content-Length: 13
Connection: Keep-Alive
Cache-Control: no-cache
Cookie: JSESSIONID=E365D980343B9307023A1D271CC48E7D
keyword=hello
1、Referer: http://localhost:8080/hello/index.jsp:请求来自哪个页面,例如你在百度上点击链接到了这里,那么 Referer:http://www.baidu.com;如果你是在浏览器的地址栏中直接输入的地址,那么就没有Referer这个请求头了;
2、Content-Type: application/x-www-form-urlencoded:表单的数据类型,说明会使用url格式编码数据;url编码的数据都是以“%”为前缀,后面跟随两位的16进制,例如“传智”这两个字使用UTF-8的url编码用为“%E4%BC%A0%E6%99%BA”;
3、Content-Length:13:请求体的长度,这里表示13个字节。
4、keyword=hello:请求体内容!hello是在表单中输入的数据,keyword是表单字段的名字。
Referer请求头是比较有用的一个请求头,它可以用来做统计工作,也可以用来做防盗链。
统计工作:比如一个公司网站在百度上做了广告,但不知道在百度上做广告对我们网站的访问量是否有影响,那么可以对每个请求中的Referer进行分析,如果Referer为百度的很多,那么说明用户都是通过百度找到我们公司网站的。
防盗链:比如一个公司网站上有一个下载链接,而其他网站盗链了这个地址,例如在公司网站上的index.html页面中有一个链接,点击即可下载JDK7.0,但有某个人的微博中盗链了这个资源,它也有一个链接指向我们网站的JDK7.0,也就是说登录它的微博,点击链接就可以从我网站上下载JDK7.0,这导致我们网站的广告没有看,但下载的却是我网站的资源。这时可以使用Referer进行防盗链,在资源被下载之前,我们对Referer进行判断,如果请求来自本网站,那么允许下载,如果非本网站,先跳转到本网站看广告,然后再允许下载。
注意:POST请求是可以有体的,而GET请求不能有请求体。
四、响应协议
(一)响应协议的格式如下:
响应首行;
响应头信息;
空行;
响应体
响应内容是由服务器发送给浏览器的内容,浏览器会根据响应内容来显示
响应头:
Location: http://www.it315.org/index.jsp 【服务器告诉浏览器要跳转到哪个页面】
Server:apache tomcat【服务器告诉浏览器,服务器的型号是什么】
Content-Encoding: gzip 【服务器告诉浏览器数据压缩的格式】
Content-Length: 80 【服务器告诉浏览器回送数据的长度】
Content-Language: zh-cn 【服务器告诉浏览器,服务器的语言环境】
Content-Type: text/html; charset=GB2312 【服务器告诉浏览器,回送数据的类型】
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器该资源上次更新时间】
Refresh: 1;url=http://www.it315.org【服务器告诉浏览器要定时刷新】
Content-Disposition: attachment; filename=aaa.zip【服务器告诉浏览器以下载方式打开数据】
Transfer-Encoding: chunked 【服务器告诉浏览器数据以分块方式回送】
Set-Cookie:SS=Q0=5Lb_nQ; path=/search【服务器告诉浏览器要保存Cookie】
Expires: -1【服务器告诉浏览器不要设置缓存】
Cache-Control: no-cache 【服务器告诉浏览器不要设置缓存】
Pragma: no-cache 【服务器告诉浏览器不要设置缓存】
Connection: close/Keep-Alive 【服务器告诉浏览器连接方式】
Date: Tue, 11 Jul 2000 18:23:51 GMT【服务器告诉浏览器回送数据的时间】
(二)响应码:
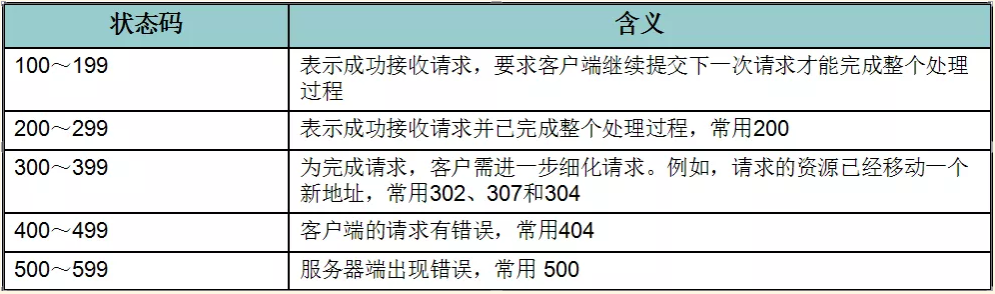
200:请求成功,浏览器会把响应体内容(通常是html)显示在浏览器中;
404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;
500:请求资源找到了,但服务器内部出现了错误;
302:重定向,当响应码为302时,表示服务器要求浏览器重新再发一个请求,服务器会发送一个响应头Location,它指定了新请求的URL地址;
304:比较If-Modified-Since的时间与文件真实的时间一样时,服务器会响应304,而且不会有响正文,表示浏览器缓存的就是最新版本下图解释了工作原理:

响应头:Last-Modified:最后的修改时间;
请求头:If-Modified-Since:把上次请求的index.html的最后修改时间还给服务器;
(三)其他响应头
1、告诉浏览器不要缓存的响应头:
Expires: -1;
Cache-Control: no-cache;
Pragma: no-cache;
2、自动刷新响应头,浏览器会在3秒之后请求指定的网址
Refresh: 3;url=http://www.itcast.cn
(四)HTML中指定响应头
在HTMl页面中可以使用<meta http-equiv="" content="">来指定响应头,例如在index.html页面中给出<meta http-equiv="Refresh" content="3;url=http://www.baidu.com">,表示浏览器只会显示index.html页面3秒,然后自动跳转到http://www.baidu.com.
Java新手,若有错误,欢迎指正!