2019-11-25
22:44:42
BigData
4.1.What is Big Data?
大数据非常庞大,结构松散,无法应对传统存储
4.2. Human Generated Data and Machine Generated Data
人工生成的数据是电子邮件,文档,照片和推文。
我们生成这些数据的速度比
曾经。
试想一下,上传到You Tube和推文的视频数量在不断增加。
该数据可以
也成为大数据。
机器生成的数据是一种新的数据。
此类别包括传感器数据和生成的日志
通过“机器”,例如电子邮件日志,点击流日志等。机器生成的数据为数量级
比人类生成的数据大。
在“ Hadoop”出现之前,机器生成的数据通常被忽略而不捕获。
它是
因为无法处理体积或成本效益不高。
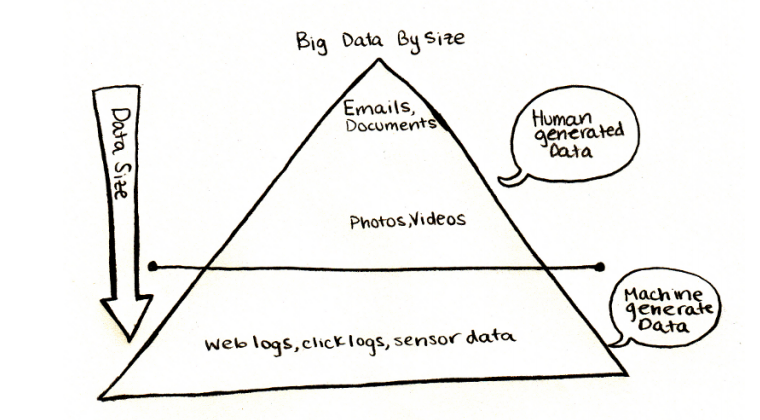
4.3. Where does Big Data come from
原始的大数据就是网络数据-就像整个Internet一样!
请记住,Hadoop是为索引网络。
如今,大数据来自多种来源。
•Web数据-仍然是大数据
•社交媒体数据:Facebook,Twitter,LinkedIn等网站生成大量数据
•点击流数据:当用户浏览网站时,将记录点击次数以进行进一步分析(例如导航模式)。
点击流数据对于在线广告和电子商务非常重要
•传感器数据:嵌入道路中的传感器,用于监控交通和杂项。
其他应用程序产生很大数据量
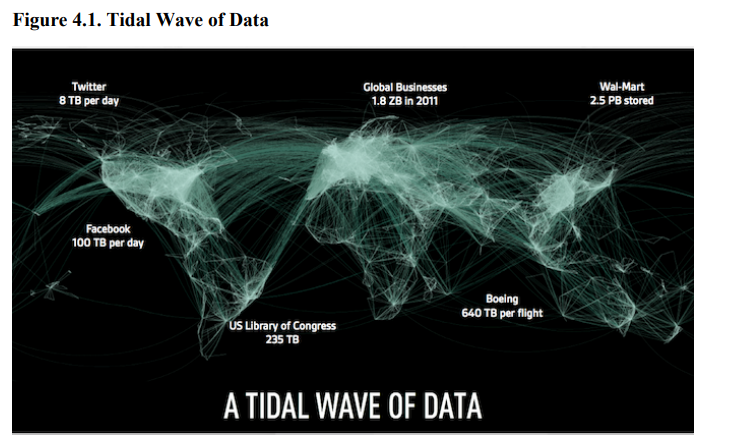
4.4. Examples of Big Data in the Real world
•Facebook:拥有40 PB的数据并每天捕获100 TB
•Yahoo:60 PB数据
•Twitter:每天8 TB
•eBay:40 PB数据,每天捕获50 TB
4.5. Challenges of Big Data
Sheer size of Big Data
大数据是...嗯...大数据!
构成大数据的数据量不是很明确。
所以让我们不要
在这场辩论中陷入困境。
对于习惯于处理千兆字节数据的小型公司,10TB的存储空间
数据将是大的。
但是对于像Facebook和Yahoo这样的公司来说,Peta字节很大。
只是大数据的大小,就不可能(或至少在成本上不允许)存储在传统存储中
例如数据库或常规文件管理器。
我们正在谈论存储千兆字节数据的成本。
使用传统的存储文件管理器可能会花费很多钱
存储大数据。
Big Data is unstructured or semi structured
许多大数据是非结构化的。
例如,点击流日志数据可能看起来像时间戳,
user_id,页面,referrer_page
缺乏结构使得关系数据库不适合存储大数据。
此外,没有多少数据库可以应付数十亿行数据的存储需求。
No point in just storing big data, if we can't process it
存储大数据是游戏的一部分。
我们必须对其进行处理以挖掘其中的情报。
传统存储
系统非常“笨”,因为它们只存储位-它们不提供任何处理能力。
传统的数据处理模型将数据存储在“存储集群”中,然后将其复制到
“计算群集”进行处理,并将结果写回到存储群集。
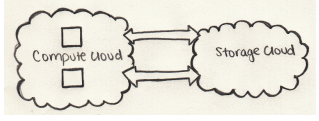
但是,此模型不适用于大数据,因为将大量数据复制到计算中
集群可能太耗时或不可能。
所以答案是什么?
一种解决方案是“就地”处理大数据-就像在存储集群中将其作为计算集群的两倍一样。
4.6. How Hadoop solves the Big Data problem
Hadoop clusters scale horizontally
通过向Hadoop群集添加更多节点,可以实现更多的存储和计算能力。
这消除了购买越来越强大和昂贵的硬件的需求。
Hadoop can handle unstructured / semi-structured data
Hadoop不会对其存储的数据强制执行“模式”。
它可以处理任意文本和二进制数据。
所以
Hadoop可以轻松地“消化”任何非结构化数据。
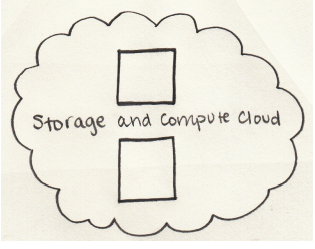
Hadoop clusters provides storage and computing
我们看到了拥有单独的存储和处理集群并不是最适合大数据的方式。
Hadoop的
集群提供了存储和分布式计算的一体。