本文的作者解决的是一个无监督的开放域识别(UODR)问题,而在开放域中的源域与目标域的情况中,⭐源域是目标域的一个子集,即一个未标记的目标域T和一个仅覆盖目标域分类子集的有差异的标记源域S。而作者的任务是要对目标域中数据进行正确地分类,包括已知的类别与未知的类别。
而当目标域中存在较多的未知类别的数据集时,任务存在的问题就是域间差异变大,GCN的分类规则也将被影响扰乱而缺乏泛化能力。
作者通过语义引导匹配差异(SGMD)来度量源域与目标域之间的域间差异,并进一步设计了一个有限的平衡约束,以实现已知和未知类别的更平衡的分类输出。作者设计的非监督开放域转移网络(UODTN)借鉴后向传播分类网络以及图卷积网络(GCN),去减小SGMD,实施有限平衡约束并最小化分类的代价函数。
非监督开放域转移网络较好地保留了语义结构,并增强了所学习的领域不变视觉特征和语义嵌入之间的一致性,在识别已知和未知类别的图像方面都具有优越性。
Introduction
1.本文问题的独特性
本文所要解决的问题类型为源域中不存在unknown类型数据而目标域中存在,即源域是目标域的子集,这种情况是非常有难度的。 在partial adversarial-DA 以及 partial weighted-DA中,有人已经解决了目标域是源域子集的问题,即unknown类型只存在于源域中的情况。但是类别空间仍然被限制在由源域扩展的闭集中,而不是一个严格意义上的开集。
在开放集域适应(Open Set Domain Adaptation)中,源域与目标域中都存在unknown类别,但是其任务是只对目标域中已知类别的样本进行分类,而忽略未知类别的样本,而在本文中的非监督开放域转移网络(UODTN)中,目标域中的已知与未知类别都是要进行分类的。
而无监督的开放域识别(UODR)问题也不同于零样本学习(Zero-Shot Learning),在泛化的ZSL(generalized ZSL)中,测试时会加入训练的类别,故数据都来自同一个域,训练集与测试集之间没有域间差异,所以之前的方案在该问题上时不能直接使用的。
2.本文问题高挑战性的分析
⭐域间差异:在源域与目标域之间存在的有关内容与分布之间的差异。
1.而当大量unknown类别注入到测试中,域间差异就更难拟合,如果直接使用传统的衡量源域和目标域数据的距离公式MMD等,会造成负迁移。
2.没有标记的训练数据或任何辅助属性信息,很难对未知类别的实例进行分类。如果能掌握已知类别与未知类别的联系⭐,在UODR 中我们可以使用图卷积网络去提炼已知类别到未知类别的分类规则,但是像在泛化的ZSL中,由于训练集加入测试,迫使对unknown类别的预测进入已知类别,而且问题1说到的域间差异也会影响已知类别与未知类别的联系的提炼。
3.解决问题的关键点
从特征分布与语义两方面来最小化语义差异。
⭐在源域中已知类别的数据中,会有一些与目标域中的图像情况相似(图中的share区域),那么就可以通过减小该share类别中源域与目标域数据的域间差异来进行领域不变特征学习
1.于是作者提出语义引导匹配差异(SGMD):
首先利用实例匹配产生粗匹配对,然后再用这些粗匹配对的加权特征距离来测量差异。
加权特征距离:权重是它们的目标域分类器反馈的阈值相似性
目标域分类器:目标域的分类器的输出是一个语义级的抽象,假设具有相同类别标签的实例对具有相似的分类输出,因此,权重反映了每对语义的一致性程度。⭐(权重如何体现源域与目标域在share类别中的关系)
2.图卷积网络(GCN)可以被用来将分类规则从已知类别转递到未知类别,然后该分类规则被用来初始化主干网的分类层
设计了一个⭐有限的平衡约束:为了处理从已知类别到未知类别的语义转移,以防止未知类别的目标域样本被分类到已知类别中。
3.最终将各个组件组合,作者开发出了⭐非可视化开放域转移网络(UODTN):
通过减小语义引导匹配差异(SGMD)、实现有限的平衡、通过图卷积网络(GCN)来保存语义结构、最小化源域上的分类器的loss
Related Work
1.深度无监督领域适应(Deep unsupervised domain adaptation)
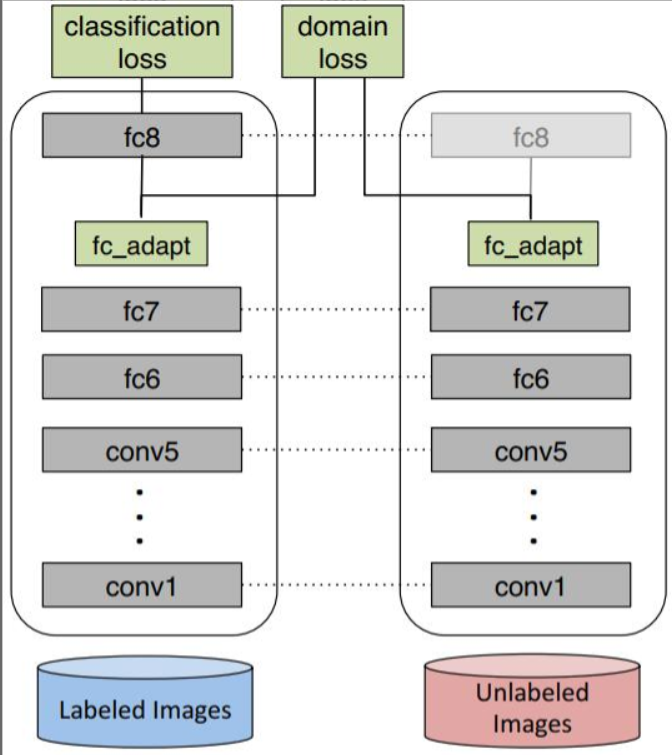
DDC:
在预训练的网络AlexNet的第七层feature层添加一个适配层,该适配层使用MMD算法来单独考察网络对源域和目标域的判别能力。如果这个判别能力很差,那么我们就认为,网络学到的特征不足以将两个领域数据区分开,因而有助于学习到对领域不敏感的特征表示。
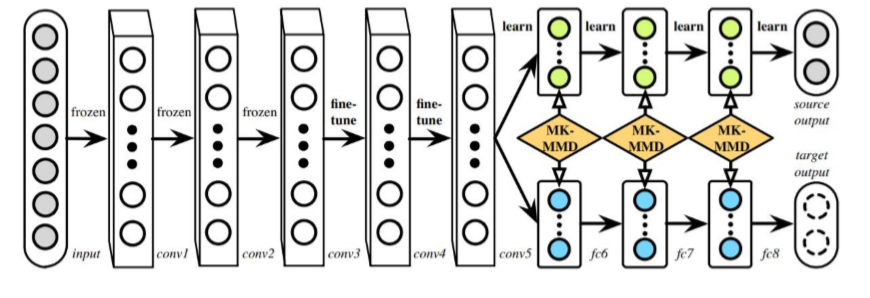
DAN:
DAN的创新点是多层适配和多核MMD
多核MMD(Multi-kernel MMD,MK-MMD):
之前的MMD是把源域和目标域用一个相同的映射映射在一个再生核希尔伯特空间(RKHS)中(通过计算核函数来实现计算无穷维的积分),然后求映射后两部分数据的均值差异,就当作是两部分数据的差异
多核MMD:我们可能不知道使用哪一个核函数效果最好,于是我们使用多个核函数进行加权,效果比单核更好
多层适配:
DAN也是基于AlexNet,但是相比于DDC只在第七层添加了一个MMD适配层,DAN分别在五层卷积层之后的三层全连接层都添加了适配,由于在五层卷积之后网络的迁移能力就开始task-specific,所以着重考虑后面的三层。
JAN(Joint Adaptation Networks):
在JAN网络中,不再单独考虑边缘分布以及条件分布,而是考虑联合分布,并且域间差异不再使用MMD来衡量,而是使用协方差来衡量
PMD :
通过最小权重图匹配来近似两个域之间的一阶瓦瑟斯坦距离。这些基于差异减少的方法只能处理S和T共享同一个标签空间的情况。
2.广义ZSL
ZSL:零次学习(Zero-Shot Learning),使用模型对其从没有见过的类别进行分类,让机器聚类推理能力,即对要分类的类别对象一次也不学习。由于训练集和测试集类别之间没有交集;所以需要借助类别的描述,来建立训练集和测试集之间的联系
广义ZSL:去学着对来自两个不同类别领域的样本进行分类:已知类别(使用传统的带标签监督训练)、未知类别(使用类似属性或自然语言的零次学习方式)
transductive 广义 ZSL:以半监督学习方式进行,源域与目标域之间没有假定的域间差异
Propagated Semantic Transfer (PST):引入语言或专家指定的信息来进行标签传播,从而利用了新类的多种结构
Unsupervised Attribute Alignment (UAA) :通过正则化稀疏编码将跨域属性关联起来,该编码强制已知和未知类别共享的属性相似
shared model space (SMS):知识可以根据属性在类间传递
Unbias ZSL :在已知和未知类别中为未标记的目标数据实施平衡分类器响应,以学习ZSL的无偏嵌入空间
3.基于知识图谱的目标识别
Salakhut-dinov使用WordNet在不同的对象分类器之间共享表示,以便具有很少训练实例的对象可以从相关对象借用统计强度。
Deng等人应用排除规则作为约束,并将对象-属性关系添加到图中,以训练用于零触发应用的对象分类器。
在论文【14】中,其作者认为过多的GCN层会导致分类器过平滑,并建议训练单层GCN。此外,在[14]中,作者使用了更密集的图结构,并微调特征空间以适应生成的语义嵌入空间。
Method
1.Common Notations
Ds:源域的训练实例个数;Dt:目标域的训练实例个数
Ls:源域中的带标签数据(有效);Lt:目标域中的带标签数据(无效)Lt-Ls:unknown类型的数据实例个数
φ(·) :特征提取器
ψS(·):源域的预处理分类器
ψT(·):目标域的分类器
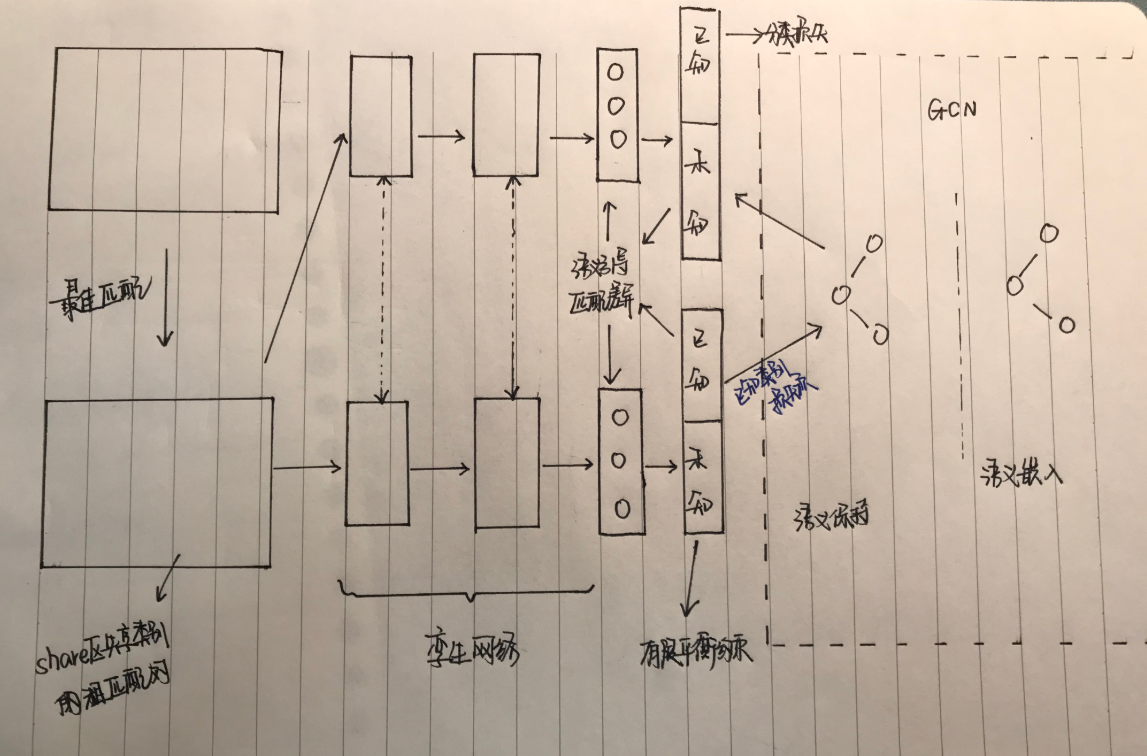
2.Framework
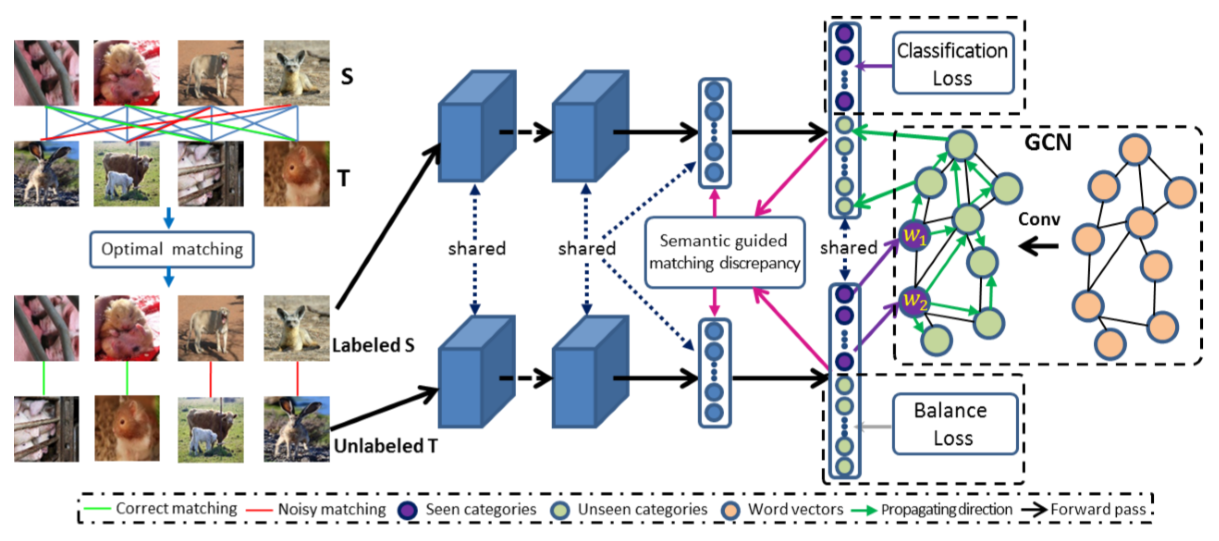
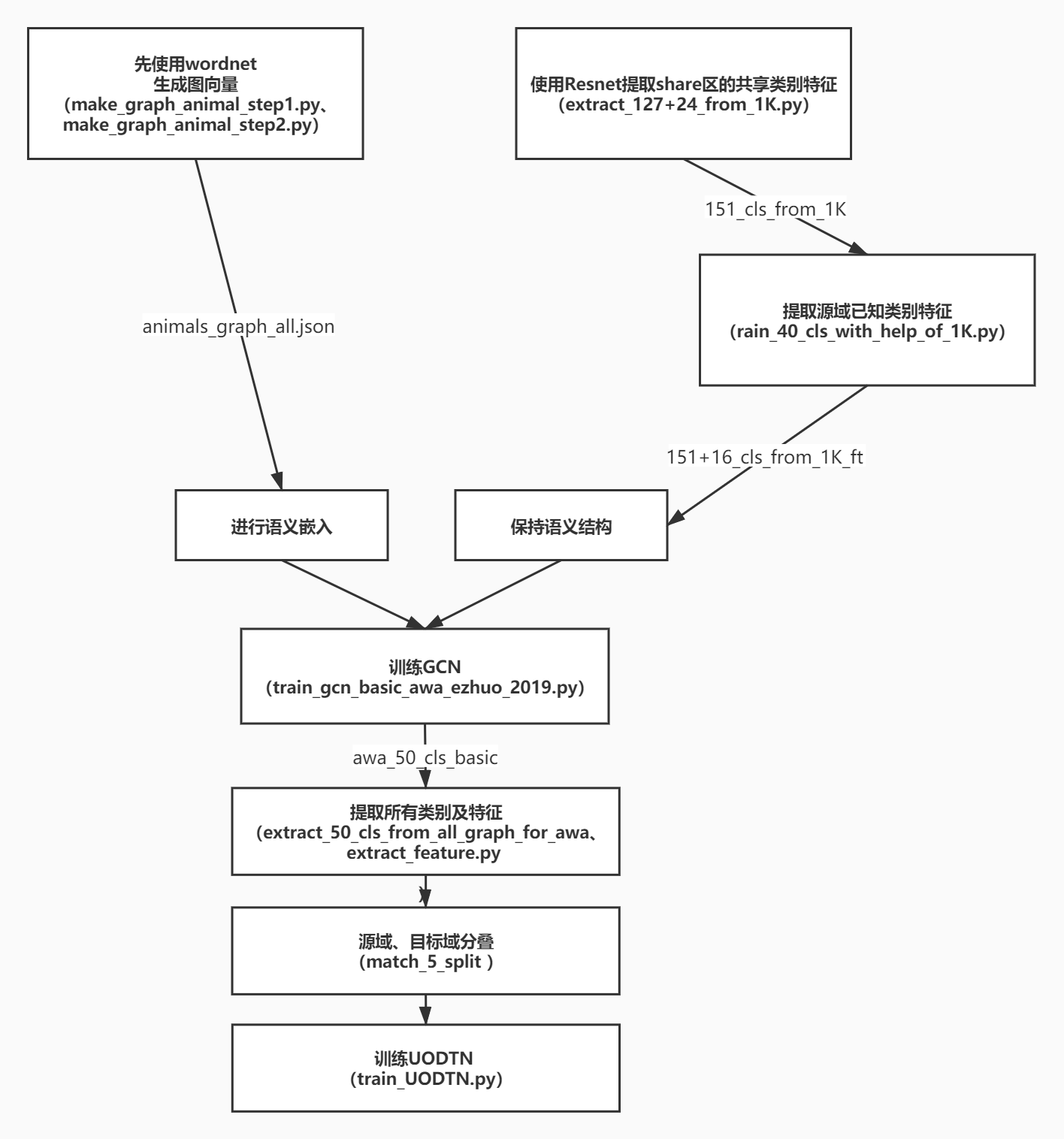
主框架:无监督开放域传输网络(UODTN)主要包括一个包含目标域中所有分类的分类器层以及一个维护目标域中所有分类的图卷积网络(GCN层)。
生成unknown类别的语义嵌入
首先使用GCN在目标数据库中生成未知类别的语义嵌入,然后通过这些语义嵌入初始化骨干分类网络的分类器层。在初始化骨干分类网络的基础上,作者进一步降低了提出的语义引导匹配的差异,加强了提出的有限平衡约束,并结合GCN来最小化UODR问题中的语义差异。骨干分类网络和GCN与GCN以端到端的方式联合训练,旨在保存编码在词向量和知识图中的语义结构。
具体步骤:
生成未知的类语义嵌入:
(1)利用在词向量中编码的辅助信息以及未知类别的知识图谱,生成邻接矩阵与连接图。作者通过图卷积网络(GCN)来实现未知类别的语义嵌入。
(2)通过训练GCN来提取已知类别的分类器权重,同时生成未知类别的分类器权重,并保留词向量和知识图中表现的语义关系。
图卷积网络的设定:
(1)先建立N个节点的图,每个节点的维度为C维:每一维表示一个类别
(2)为了将已知类别的语义嵌入传播到未知类别,需要额外的节点来构建从已知类别到未知类别的完整路径
(3)每个节点由词向量的类名进行初始化(make_graph_animal_step1.py、make_graph_animal_step2.py),各个类别之间的关系是由一个包括自环的邻接矩阵表示的。
图卷积网络的传播方式:
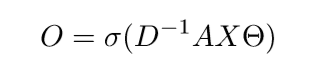
X:N个词向量 Θ:训练的权重 σ(·):非线性激活函数 D:度矩阵(度矩阵是对角阵,对角上的元素为各个顶点的度)
图卷积网络的损失:

W:从源域的预处理分类器中的权重
语义引导匹配差异
源域与目标域之间的域间差异会影响图卷积网络的转播,而传统的域间差异的度量方法(MMD)是基于源域与目标域共享相同类别的基础上的,所以作者提出语义引导匹配差异来估计域间差异
作者从源域和目标域中提取所有实例的特征,构造一个二分图,并通过匈牙利算法解决二分图的最小权重匹配问题,获得源域和目标域之间的粗糙和有噪声的匹配实例对,之后使用匹配对的语义一致性来过滤这种有噪声的匹配对
语义引导匹配差异公式:


有限平衡约束
为了防止未知类别的目标域样本被分类到已知类别中,为目标域实例的分类器响应添加平衡约束。
普通的平衡约束:

问题:目标域没有标签,该平衡约束会很大
本文的平衡约束:
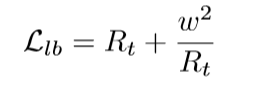

w是手动设置的常数,用于控制所有类别中未知类别的分类响应比率。这种约束强制未知类别的分类结果在所有类别中的比率处于适当的范围内。理想情况下,w可以根据所有类别中未知类别的比例来设置。
通过GCN保持语义结构
仅通过减少语义引导的匹配差异和实施有限的平衡约束,不能很好地保持词向量和知识图谱中类别之间的语义结构
所以需要GCN加入训练,但是这里与之前的不同在于此前的GCN中只是考虑了unknown类别的语义嵌入,而现在的GCN是要将目标域中所有类别的语义嵌入都在损失项中考虑(train_gcn_basic_awa_ezhuo_2019.py extract_50_cls_from_all_graph_for_awa.py)
使用在源域上预训练好的ResNet-50分类器提取源域特征(extract_127+24_from_1K.py)。
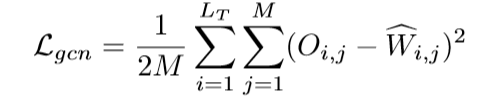
W:从目标域的分类器中的权重
联合训练
总的损失函数:

Lcls:源域的分类损失函数 λb λd λg:语义引导的匹配差异中的权重
最小化语义引导的匹配差异为已知和未知类别提供了可变的特征领域;而且已知类别的分类情况受分类损失的监督以及GCN的监管,未知类别的分类是受有限平衡约束以及GCN的监管⭐。
Experiment
1.Datasets
I2AwA数据集:
源域:作者通过谷歌图像搜索收集了已知类别的源域数据集并去除了有噪声的图像,总共产生了2970幅图像。(大都是3D模型图像)
目标域:使用AWA2数据集,由50个动物类组成,总共有37322张图片,平均每类有746张图片。其中40类被认为是已知的类别,其余10类被认为是未知的类别。(是自然界的真实图像)

I2WebV数据集:
源域:ILSVRC-(6)2012,有1000类,总共包含1279847张图像。
目标域:包含5000个类的WebVision 的验证集,它由294009张图像组成
知识数据库:WordNet
2.评估计量
对整个目标域执行类似于广义零次学习的分类,并报告目标域上已知类别、未知类别和所有类别的最高准确度,以便更好地理解知识转移过程。
3.基准
与zGCN(是建立在图的基础上的,它利用字向量和编码在字网中的类别关系来预测未知类别的类别)、bGCN(带原始平衡约束的GCN)、pmd-bGCN(进一步减少匹配差异,是最先进的域间差异测量方法)做为基线进行比较。
4.实施细节
I2WebV:
使用wordnet构造节点个数为7460的图,中节点的词向量作为GCN的输入,预训练模型为ResNet-50,最后一个全连接层,即分类层,被视是GCN倾向于预测的目标。
以词向量为输入,以预处理后的ResNet-50的分类器为目标对GCN进行训练,得到I2WebV中目标域的初始分类器。
I2AwA:
1.用于训练GCN的监督信息(151+16_cls_from_1K_ft:包括127+24个原分类器以及16个微调后的分类器)是在I2AwA的源域上微调后的分类器,这些初始分类器之后被连接到预处理后的ResNet-50的特征提取器中(去除了原始分类器层)(train_40_cls_with_help_of_1K.py )
2.作者修复了ResNet-50的一些起始卷积层,以加速训练过程。在分类层之前的全局平均池化输出的值即视为特征,基于这些特征,作者构造一个二分图,每个子图代表源域和目标域。
3.使用匈牙利算法获得最小权重匹配对来估计总体匹配差异和我们提出的语义引导匹配差异
使用在域鉴别器中编码的差异度量作为等式中的距离度量
大规模的数据的二分图进行最小权重匹配是比较困难的,作者使用分治方法,在I2AwA中,作者将源域与目标域各自分成5叠,然后每个叠对构造二分图求最小权重匹配。
5.结果与讨论⭐
在I2AwA数据集上的表现:
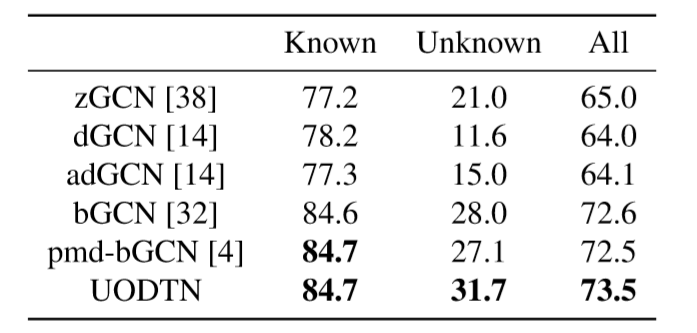
(1)作者的UODTN网络模型在已知类别、未知类别以及所有类别的分类精度都较之前的技术有了明显的提高。
(2)由于源域与目标域之间的差异, zGCN, dGCN and adGCN从源域得到的与知识图谱中得到的与数据并不是很贴切,
而UODTN与bGCN表现较好的原因就在于考虑了未知类别的语义特征。
(3) UODTN与bGCN相比,作者认识到单单引入对分类的平衡约束还是不够的,因为源域与目标域间存在差异,这种差异会导致分类器精度下降,当传播到目标领域的未知类别时,会导致语义嵌入的分散化。
(4)在bGCN与 pmd-bGCN中,仅仅使用传统的方法去减小域间差异会导致负迁移,而通过减小语义引导匹配差异的UODTN则有效的避免了负迁移的出现。
在I2WebV上的表现:

UODTN(普通版)以及对已知类别、未知类别以及所有类别的分类精度有了显著的提升,而 UODTN (未知类别版)对未知类别的分类精度提升效果更明显。
6.消融实验Ablation Study⭐
作者的消融实验考查的主要因素有:平衡约束的限制(lb)、减小语义引导匹配差异(sgmd)、加入GCN的联合训练(gcn)
结果:
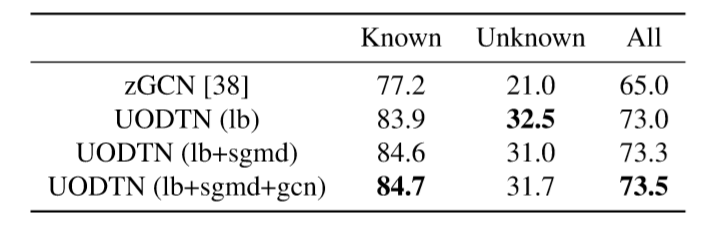
(1)UODTN(lb)与zGCN相比:验证了平衡约束的限制能有效防止未知类别被分类到已知类别。
UODTN(lb)与bGCN相比:验证了平衡约束的限制效果比边缘约束效果更好。
(2)UODTN(lb)与UODTN (lb+sgmd) :验证了减小语义引导匹配差异不仅可以预防负迁移,还可以增强所学特征的领域不变性。
(3)UODTN(lb+sgmd+gcn) 与UODTN (lb+sgmd) :可以看出已知类与未知类的联系在对未知类的语义嵌入是至关重要的,验证了加入GCN后的联合训练保持了词向量与知识图谱中的语义结构。
7.传统的领域自适应
作者在传统的领域自适应的问题中引入语义引导匹配差异,以此来证明语义引导匹配差异在处理领域自适应问题的可行性与一般性。
结果:

8.例证
通过实例来进一步展示UODTN的一些定性结果,表明UODTN能够有效的将源域的语义嵌入转移到目标域中的未知类别,有效的在源域与词向量、知识图谱间传递信息。

Conclusion
作者研究了一个无监督的开放域识别问题,给出了一个未标记的目标域T和一个仅覆盖目标域分类子集的有差异的标记源域S,目标是对目标域的所有实例进行分类。由于源域与目标域之间的语义差异,二者在内容和分布方面上表现出很大的差异,再加上两个领域之间从已知类别到未知类别的语义转移,导致科UODT更具挑战性。作者开发了无监督开放域转移网络(UODTN),该网络通过减少SGMD、实现有限平衡、通过GCN保持语义结构和最小化源域上的分类损失来联合学习主干分类网络和GCN,能够高效地解决无监督的开放域识别问题。
该论文研究了一个无监督的开放域识别问题,无监督即目标域不存在可用标签,开放域即源域与目标域是非对称的,具体讲是一个未标记的目标域T和一个仅覆盖目标域分类子集的有差异的标记源域S,任务是要识别目标域中包括已知类别与未知类别在内的所有类别。
作者的研究出发点
主要方法:从需要解决的任务中入手,在解决任务的过程中,从遇到的问题中入手,在传统的解决方法无效后,分析提出新的方法,并进行实验以及验证。
1.目标域的未知类别较多时,无法直接忽略,而且源域与目标域之间的差异变大(不能只仅仅通过源域与目标域的共享类别进行分类判断),
传统衡量源域和目标域数据的距离的方法大都基于源域与目标域为相同类别,所以需要提出新的衡量域间差异的方法——语义引导匹配差异。
而且未知类别较多,为了防止未知类别错误地分配到已知类别,而且普通的平衡约束会由于未知类别较多的原因偏大,所以引入新的有限平衡约束。
2.不知道已知类别与未知类别之间的联系,无法提炼已知类别到未知类别的分类规则——引入词向量,进行未知类别的语义嵌入。
3.减小语义引导匹配差异无法只靠词向量完成,而且语义的嵌入以及语义结构的保持都需要GCN的参与,所以引入GCN网络。
各个特点步骤的实现方法
1.未知类别的语义嵌入:利用在词向量中编码的辅助信息以及未知类别的知识图谱,生成邻接矩阵与连接图。再通过图卷积网络(GCN)来实现未知类别的语义嵌入。
2.语义引导匹配差异:提取源域以及目标域的各自特征,构造二分图,利用匈牙利算法进行二分图的最小权重匹配。
3.有限平衡约束:在传统的平衡约束的基础上添加一个w参数,w是手动设置的常数,用于控制所有类别中未知类别的分类响应比率。这种约束强制未知类别的分类结果在所有类别中的比率处于适当的范围内。理想情况下,w可以根据所有类别中未知类别的比例来设置。
4.保持语义结构:向GCN输入所有类别的特征损失项,从而在训练中保持语义结构。
5.联合训练:已知类别的分类情况受分类损失的监督以及GCN的监管,未知类别的分类情况是受有限平衡约束以及GCN的监管
实验的验证方法
基本方法:横向验证+纵向验证+一般性验证
横向验证
在实验中设置基线,与zGCN(是建立在图的基础上的,它利用字向量和编码在字网中的类别关系来预测未知类别的类别)、bGCN(带原始平衡约束的GCN)、pmd-bGCN(进一步减少匹配差异,是最先进的域间差异测量方法)做为基线进行比较。
上述的结构都是考虑某一方面,通过文中的UODTN与之比较,能够突出UODTN在对应模型未考虑到的方面的优越性。
纵向验证(消融实验)
本文中的模型的特色在于有限的平衡约束、语义引导差异匹配以及加入GCN进行联合训练几方面,作者通过UODTN(lb)、UODTN (lb+sgmd)与UODTN(lb+sgmd+gcn) 可以知道模型的各个部分的作用是否与自己分析预测的相一致。
一般性验证
针对语义引导差异匹配,作者还在传统的模型中使用了该方法,从而验证自己的语义引导差异匹配确实能够衡量源域与目标域的域间差异而且具有一般性。
实验的创新点
1.在新的问题领域提出了衡量源域与目标域的域间差异的新方法:语义引导差异匹配。
2.由于目标域的未知类别较多,传统的平衡约束不能满足要求,于是设计提出有限平衡约束。
3.并不是将GCN用于语义嵌入后就抛弃,而是将GCN加入后续的联合训练来保持语义结构。
4.数据集使用一大(I2WebV)一小(I2AwA),可以先在小数据集上进行自己思路设定的简单验证,再在大的数据集上测试考查模型的具体精度表现。
5.验证方式多样化,使用横向以及纵向验证,最后又使用一般性验证排除了实验环境的偶然性。
模型框架理解