把语音分割为计算发音质量测度所需要的小单元时候,需要进行Viterbi对齐
Viterbi,在htk和sphinx中,也被称作token passing model
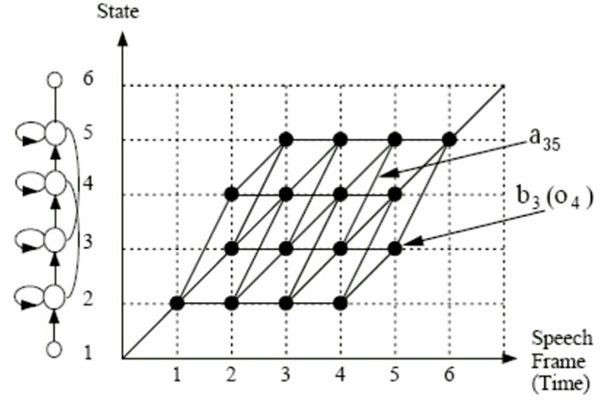
Viterbi解码图是 状态数Sm(所有状态)*时间长度(帧长度)On大小
Viterbi是对一个非常大的HMM(多个音素HMM的组合,可能是所有音素HMM的组合)进行解码
Viterbi解码,输入是On长度的帧,输出是一个状态序列,然后可以对应一个HMM
一个HMM可以代表无数个状态序列,因为其中有自环
Token passing为生成hypotheses(译者注:意为可能的识别结果)的lattice(译者注:网格)提供了可能,lattice比单Best输出更有用。基于这个思想的算法称为lattice N-best。因为每个状态一个token,限制了可能得到的不同token历史记录的数量,所以他们不是最合适的。若每个模型状态对应
多个token,并且如果认为来自不同前序单词的token是不同的,就可以避免上述限制。这类算法称为word N-best 算法,经验表明它的性能可以和最优的N-best算法相当。
δi(1),πi(1)bi(ο1),假设i=5,初始状态为5且输出观察向量为ο1的概率,
ψi(1),0
δj(t),状态路径为<p1,p2,…,i,j>且概率最大时(p1,p2,…,pn未知),j的观察向量为ot的概率.假设j=9,t=15,
ψj(t),使状态路径为<p1,p2,…,i,j>概率最大的i(p1,p2,…,pn未知)