在线自然梯度


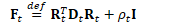
对于任意对称矩阵Σ,存在一个特征值分解(eigenvalue decomposition,EVD):
|


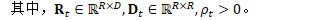

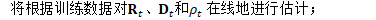
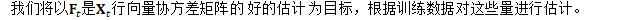
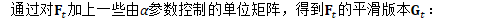
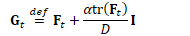
然后,输出将等于:

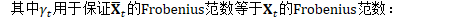
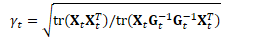

对方差的低秩近似
低秩近似
也可表示为:
|
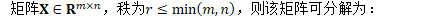
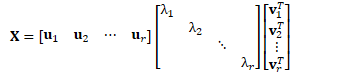
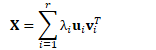

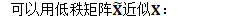
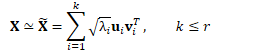
定义:
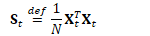
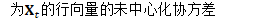
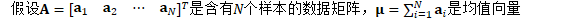

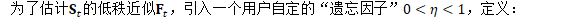
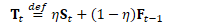

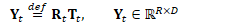


更新细节如下:
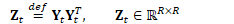
对称特征值分解:
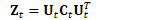
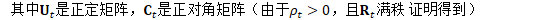

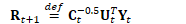
|
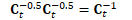
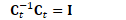
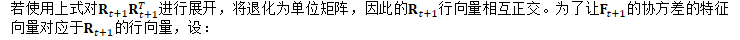
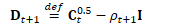

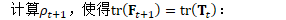
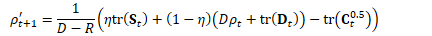
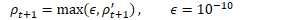
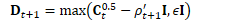
B.3 高效计算
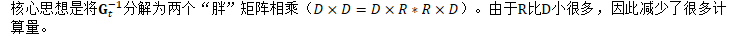
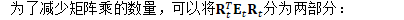
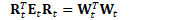

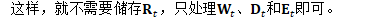
因此,主要的计算可写为:
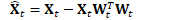
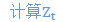
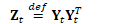
根据:
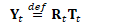
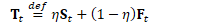
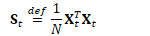

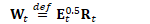
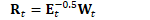


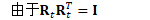
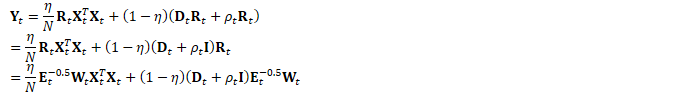
为方便起见,定义:
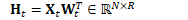
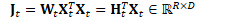


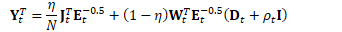
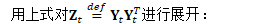
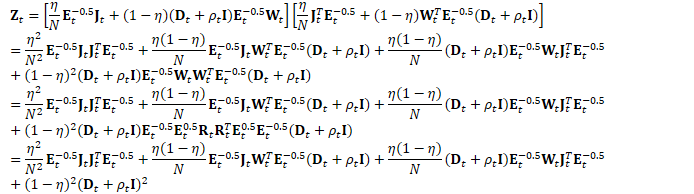
为方便起见,定义:
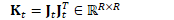
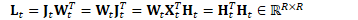
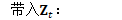
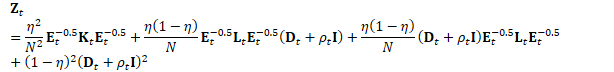
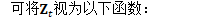
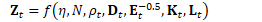

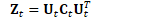

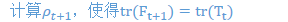
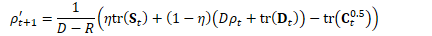
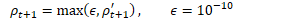
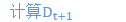
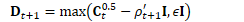


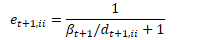
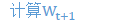
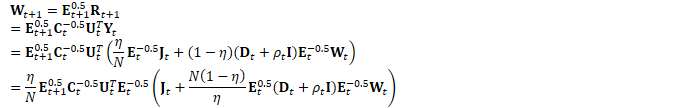
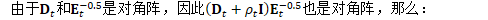
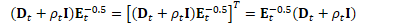
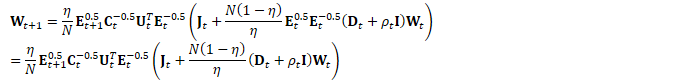
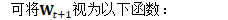
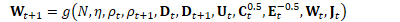
为方便起见,定义:
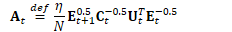
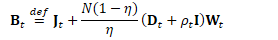
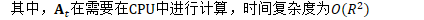
B.3.1 保持正交

检测此问题的方法
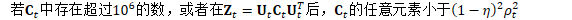
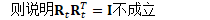
解决此问题的方法
计算对称矩阵:

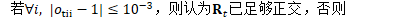
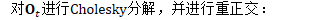
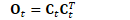
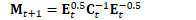
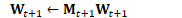
重正交极少发生,通常只发生存在错误时,比如参数发散
B.3.2 初始化

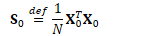
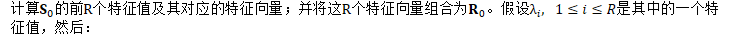
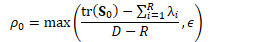
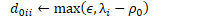
其中:
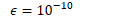
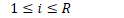
B.5 在线自然梯度方法的总结
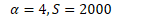

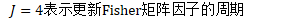

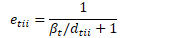
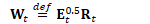
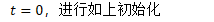
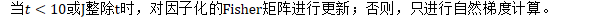
不管怎样,首先计算遗忘因子:
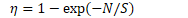
然后计算:
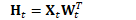
不更新Fisher矩阵
计算:
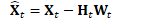
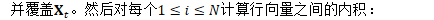


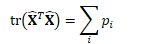
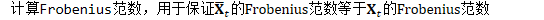
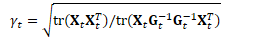
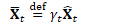
更新Fisher矩阵
计算:
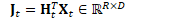

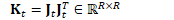
将L、K、W和J合并为一个在内存中相邻的矩阵
参考文献
https://zhuanlan.zhihu.com/p/37609917
https://blog.csdn.net/u013571243/article/details/50867174
Povey, Daniel, Xiaohui Zhang, and Sanjeev Khudanpur. "Parallel training of DNNs with natural gradient and parameter averaging." arXiv preprint arXiv:1410.7455 (2014).