spark集群的启动过程:
1.启动Hadoop:
①初始化:hadoop namenode -format
②启动服务:start-dfs.sh + start-yarn.sh (或者直接start-all.sh)
③查看进程:jps
启动成功的话会显示6条进程,如下图所示:

2.启动spark:
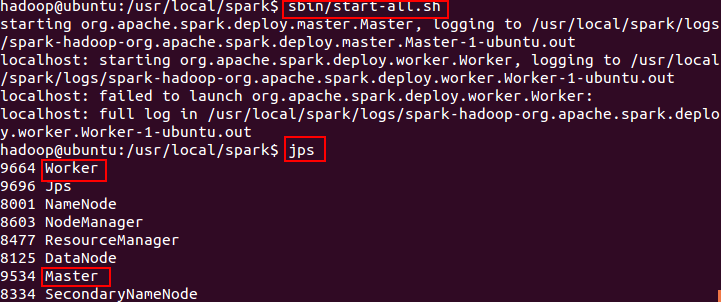
Hadoop启动成功后,cd到spark目录下,执行sbin/start-all.sh,
查看进程会发现多了worker和master
可以通过WEB端进行查看:
namenode端口:50070
yarn端口:8088
spark集群端口:8080
spark-job监控端口:4040
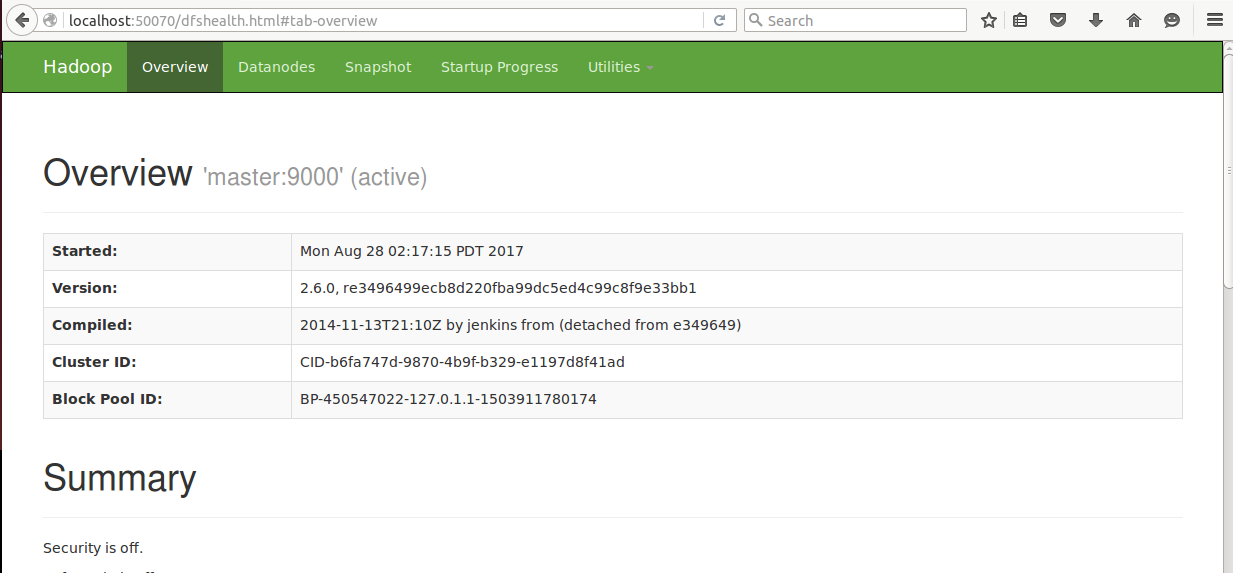

此时spark集群就启动成功了。
不过很多朋友们会经常遇到DataNode启动失败的情况,即进程中缺少DataNode。以下是我个人的解决方案:
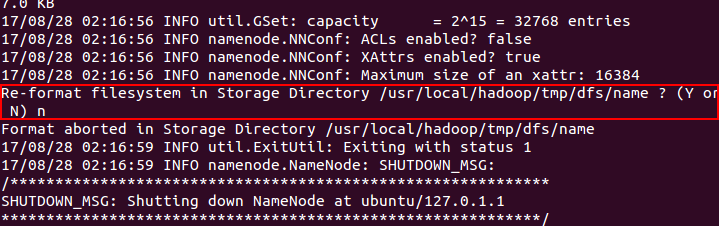
到Hadoop目录下的/tmp/dfs可以看到两个目录:name和data,分别找到该目录下的VERSION文件,查看其clusterID,修改data中的clusterID使其与与name中的clusterID保持相同。如果相同,则datanode可正常启动。

当我们执行初始化:hadoop namenode -format时,会出现个询问,如下图,此处如果选择Y,则/tmp/dfs下name夹子会更新,进而version文件中的clusterID会发生变化,导致data文件的clusterID与name的clusterID不同,此时则无法正常启动datanode,所以提醒大家记得选N,避免不必要的麻烦。