PS:前面两章已经介绍了ES的基础及REST API,本文主要介绍ES常用的插件安装及使用。
Elasticsearch-Head
Head是一个用于管理Elasticsearch的web前端插件,该插件在es5版本以后采用独立服务的形式进行安装使用(之前的版本可以直接在es安装目录中直接安装),因此需要安装nodejs、npm等前端环境。
yum -y install nodejs
在执行查看版本命令即可查出。
[root@192 bin]# node -v
v6.14.3
[root@192 bin]# npm -v
3.10.10
到这里,npm和nodejs算是安装成功了!
如果没有安装git,还需要先安装git:
yum -y install git
然后安装elasticsearch-head插件:
git clone https://github.com/mobz/elasticsearch-head.git
git下载完成后,进入目录,进行操作:
cd elasticsearch-head/
npm install
插件安装会比较慢,会花费比较长时间,请耐心等待...
配置插件
插件启动前,需要先对插件进行一些相关配置
- 修改elasticsearch.yml,增加跨域的配置(需要重启es才能生效):
#增加跨域配置:
http.cors.enabled: true
http.cors.allow-origin: "*"
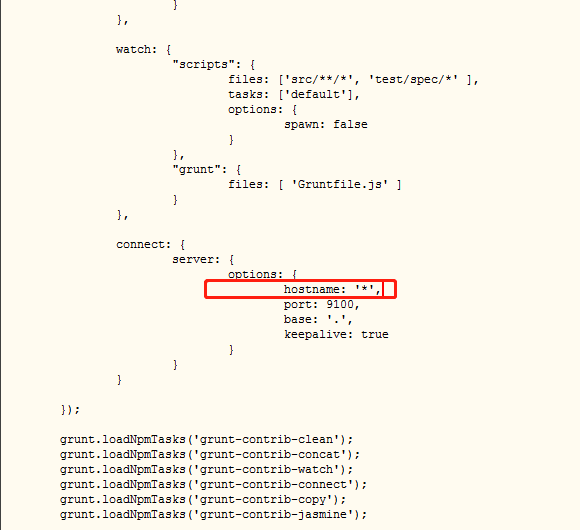
- 修改Gruntfile.js文件,修改服务监听地址(增加hostname属性,将其值设置为*)
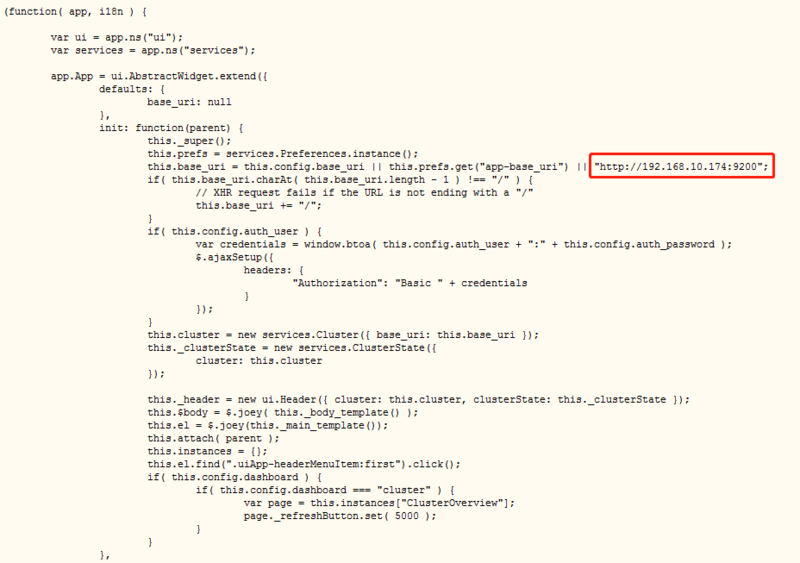
- 修改head/_site/app.js,修改head连接es的地址(修改localhost为本机的IP地址)
启动/停止插件
后台启动
cd /usr/share/elasticsearch-head/node_modules/grunt/bin/
nohup ./grunt server & exit
停止插件
使用命令:netstat -ntlp 查看服务就端口,然后使用 kill -9 pid 杀掉进程
启动成功后,可在浏览器访问插件与ES进行交互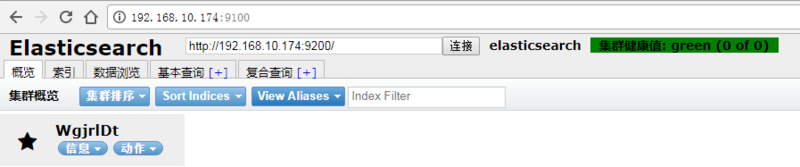
IK分词器
安装中文分词插件,这里使用的是 IK,也可以考虑其他插件(比如 smartcn)。
$ ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.0.1/elasticsearch-analysis-ik-6.0.1.zip
上面代码安装的是6.0.1版的插件,与 ES 6.0.1配合使用。
接着,重新启动 Elastic,就会自动加载这个新安装的插件。
然后,新建一个 Index,指定需要分词的字段。这一步根据数据结构而异,下面的命令只针对本文。基本上,凡是需要搜索的中文字段,都要单独设置一下。
$ curl -X PUT 'localhost:9200/accounts' -d ' { "mappings": { "person": { "properties": { "user": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "desc": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } } }'
上面代码中,首先新建一个名称为accounts的 Index,里面有一个名称为person的 Type。person有三个字段。
- user
- title
- desc
这三个字段都是中文,而且类型都是文本(text),所以需要指定中文分词器,不能使用默认的英文分词器。
Elastic 的分词器称为 analyzer。我们对每个字段指定分词器。
"user": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }
上面代码中,analyzer是字段文本的分词器,search_analyzer是搜索词的分词器。ik_max_word分词器是插件ik提供的,可以对文本进行最大数量的分词