一、数据访问操作符
1、SCAN操作符:扫描操作主要分为3种
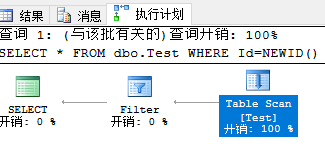
Table Scan:当针对一个表(没有聚集索引、堆表)执行一个查询语句时,
此时将会做全表扫描操作(如果有where子句,则先执行全表扫描操作,然后在针对结果集做Filter操作)
示例:
Cluster Index Scan:聚集索引扫描,表中所有的数据都存在于聚集索引的叶节点中,因此聚集索引扫描相当于将整个表中的数据都取出。

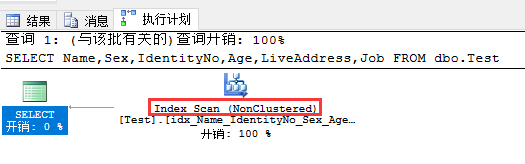
Non-clustered Index Scan:当查询的字段都被包含在一个覆盖索引中的情况下,查询优化器会优先使用Index Scan来查找这些数据,
因为非聚集索引比聚集索引占用的空间小,I/O成本更低。
示例:在Test表上创建一个覆盖索引
Create index idx_Name_IdentityNo_Sex_Age_Job_LiveAddress on Test(Name) INCLUDE(Sex,IdentityNo,Age,LiveAddress,Job)
查询SQL
SELECT Name,Sex,IdentityNo,Age,LiveAddress,Job FROM dbo.Test
执行计划如下
2、SEEK操作符:
根据索引的不同可以分为:聚集索引查询、非聚集索引查找
聚集索引查找发生在对聚集索引字段(一般情况下都是主键字段)进行where过滤的情况下
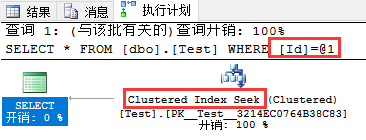
非聚集索引查找发生在对非聚集索引字段进行where过滤的情况下

3、Bookmark Lookup操作符:书签查找发生在非聚集索引的语句中,用于查询不包含在当前索引中的字段
一般优化手段是将额外的字段包含在一个Include索引中

二、连接操作符
1、Nested Loop
一般外表为小表(一般小于10000数据),较大数据表做为内表。循环嵌套连接查找内部循环表的次数等于外部循环的行数,
因此最好对内表的相应的字段上建索引,否则内表将需要做多次的全表扫描,性能有可能会产生影响。

2、Merge Join
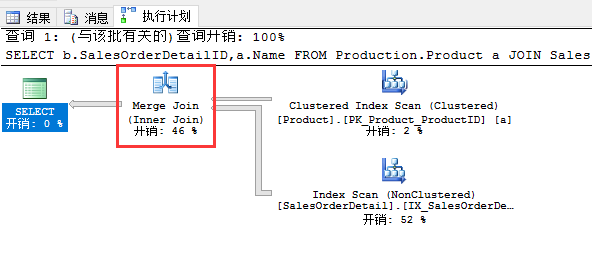
一般而言,当输入两端有序的情况下,适用Merge Join效率会比较高。
示例:b表中的ProductID上有建索引,此时输入两端都处于有序状态
SELECT b.SalesOrderDetailID,a.Name FROM Production.Product a JOIN Sales.SalesOrderDetail b ON a.ProductID=b.ProductID
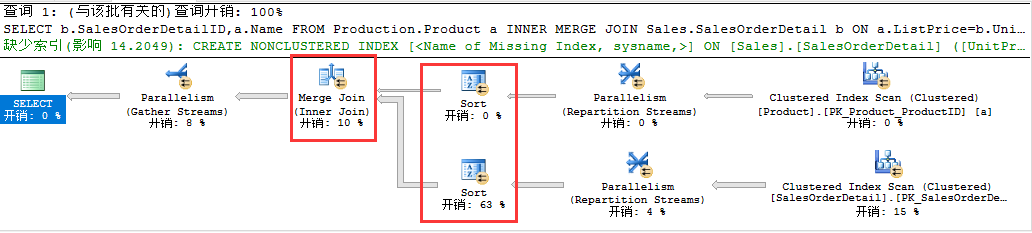
如果输入两端处于无序的情况下,强制使用Merge Join连接,则将会额外多出排序操作以确保输入两端有序
SELECT b.SalesOrderDetailID,a.Name FROM Production.Product a INNER MERGE JOIN Sales.SalesOrderDetail b ON a.ListPrice=b.UnitPrice WHERE a.ListPrice>5
3、Hash Join
当连接表数据量较大,并且输入两端无序(连接列无索引)时,查询优化器将优先使用Hash Join连接方式
SELECT b.SalesOrderDetailID,a.Name FROM Production.Product a INNER JOIN Sales.SalesOrderDetail b ON a.ListPrice=b.UnitPrice

三、聚合操作符
聚合操作分两类:Stream Aggregate(流聚合)和Hash Aggregate(哈希聚合)
1、流聚合:
流聚合中又分两种:一种是不包含GROUP BY子句的也称为标量聚合,另外一种是包含GROUP BY子句聚合
标量聚合示例:

Group By聚合示例:
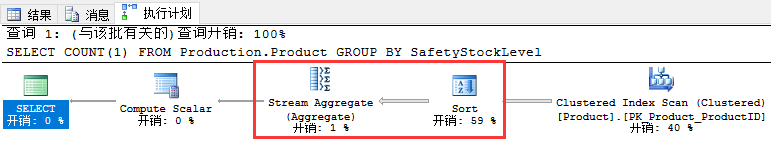
由执行计划可以看出,针对Group By字段上建立合适的索引,将省去额外的Sort操作。
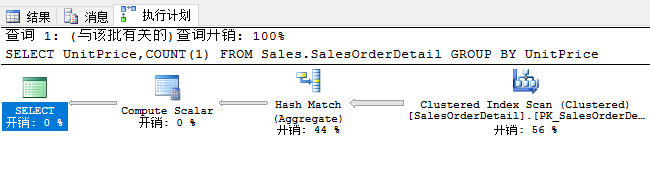
2、哈希聚合:
当数据量较大,且输入端数据无排序的情况下,查询优化器一般会使用哈希聚合(迭代器名称为:Hash Match)
示例:
SELECT UnitPrice,COUNT(1) FROM Sales.SalesOrderDetail GROUP BY UnitPrice