对于一个查询SQL而言,通常将其逻辑处理过程分成7个大的阶段
分别是:
1.FROM
2.WHERE
3.GROUP BY
4.HAVING
5.SELECT
6.ORDER BY
7.TOP/OFFSET/FETCH
1、SQL语句执行阶段示例.
(5)select (5-2) distinct(5-3) top(<top_specification>)(5-1)<select_list> (1)from (1-J)<left_table><join_type> join <right_table> on <on_predicate> (1-A)<left_table><apply_type> apply <right_table_expression> as <alias> (1-P)<left_table> pivot (<pivot_specification>) as <alias> (1-U)<left_table> unpivot (<unpivot_specification>) as <alias> (2)where <where_pridicate> (3)group by <group_by_specification> (4)having<having_predicate> (6)order by<order_by_list>
2、流程图
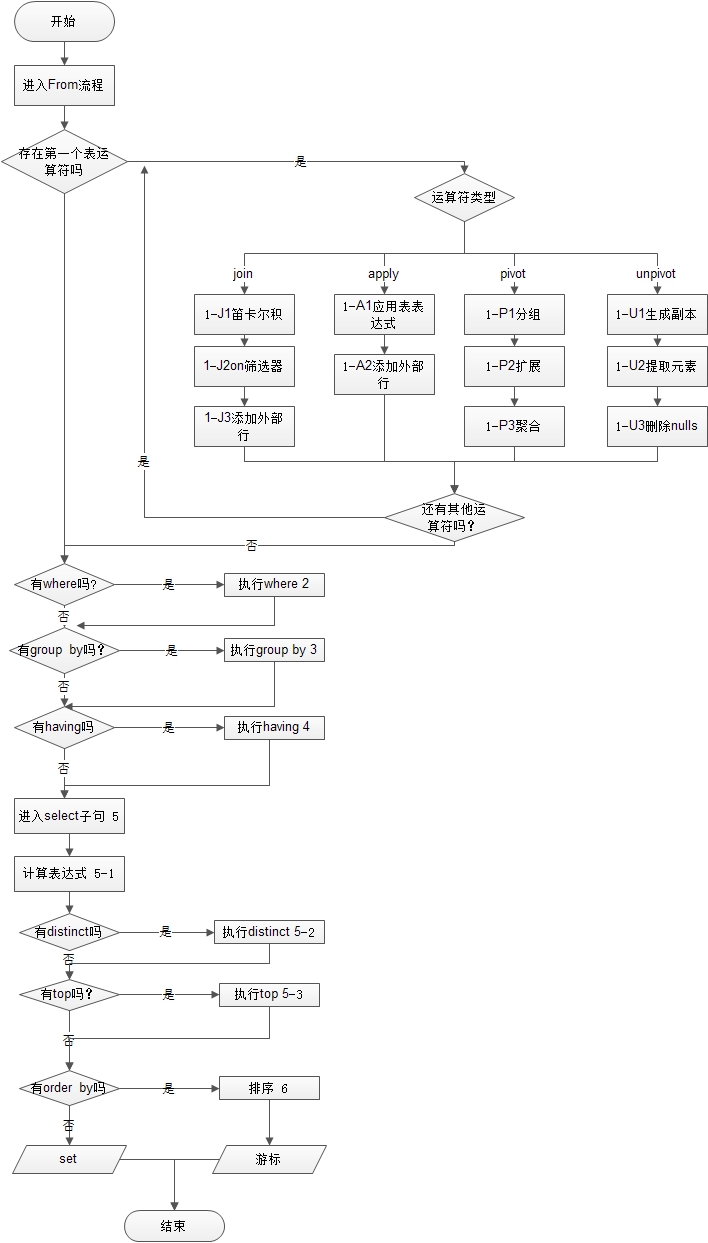
流程:
1.FROM:该步骤用于验证查询的源表,并处理表操作符,生成虚拟表VT1
1-1.如果存在左表和右表的交叉连接(求笛卡尔积),生成一个虚拟表VT1_1.
1-2.对笛卡尔积(VT1)应用ON筛选器,生成虚拟表VT1_2.
1-3.如果是外部连接,1-2中被过滤掉的数据将会被重新添加到虚拟表VT1_2中,生成虚拟表VT1_3.
2.WHERE:对虚拟表VT1应用WHERE筛选器,生成虚拟表VT2
3.GROUP BY:将VT2中的数据进行分组,生成VT3,如果语句包含WITH CUBE 或者WITH ROLLUP语句,则将分组统计结果再次加总后插入VT3,生成VT3_1.
4.HAVING:对VT3虚拟表应用HAVING筛选器,生成虚拟表VT4.
5.SELECT:处理SELECT中的子元素,生成虚拟表VT5.
5-1.计算表达式:处理SELECT列表中的计算表达式,生成VT5_1.
5-2.DISTINCT:处理VT5_1中的重复行,生成VT5_2.
6.ORDER BY:对VT5_2进行排序,生成一个游标VT6
6-1.该步骤中已经可以使用SELECT列表中的列别名
6-2.ORDER BY子句是应用到最终结果集上的,因此当SQL中出现UNION等关键字时,ORDER BY执行顺序在UNION操作之后.
7.TOP:根据ORDER BY子句中指定的排序规则,从VT6中筛选指定数量的行
参考资料:王晓文、张洪举<<锋利的SQL>>