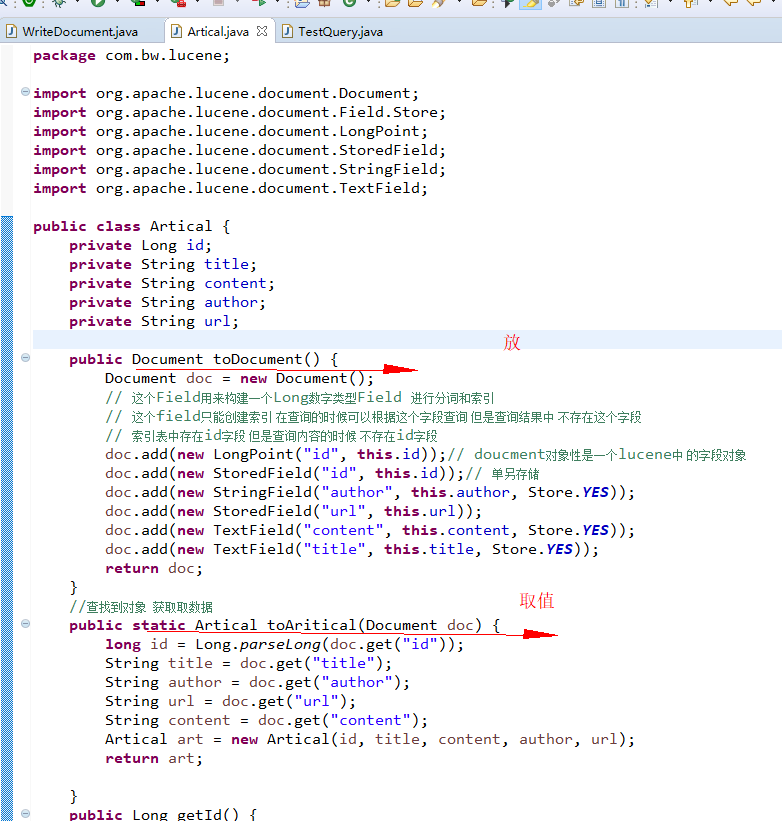
取值的时候 得到的 是document对象 将他转换成自己的对象 , 然后 在读取
取值的类
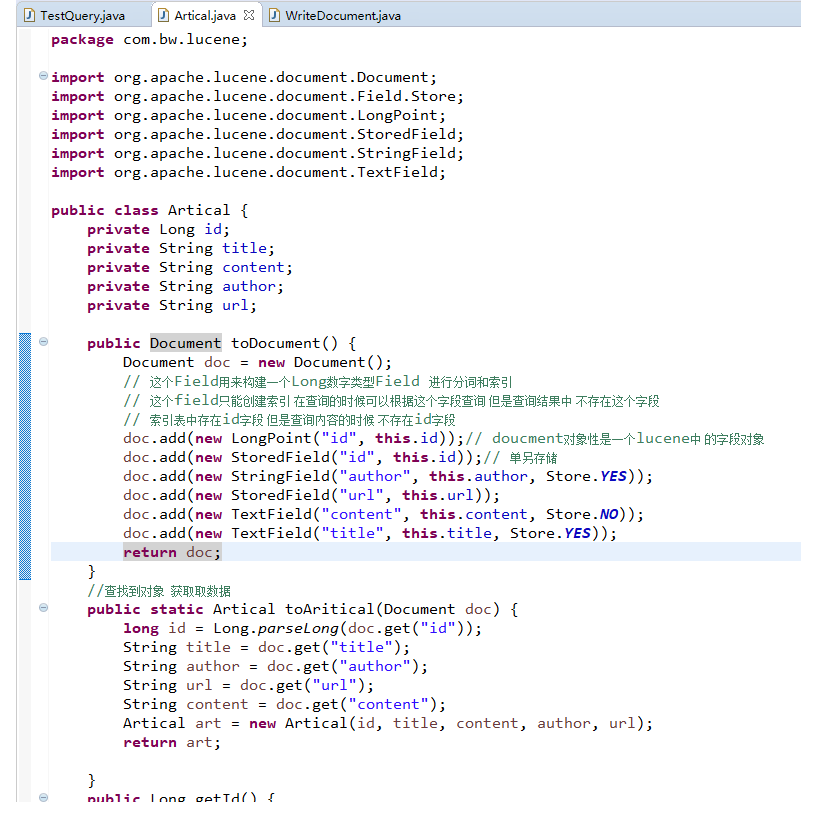
package com.bw.lucene; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.FSDirectory; public class TestQuery { static String path = "E://lucene"; public static void main(String[] args) throws Exception { //路径 FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Analyzer analyzer = new StandardAnalyzer(); //标准分词器 //没有业务逻辑 每个都分词一次 QueryParser parser = new QueryParser("content",analyzer); Query query = parser.parse("hadoop"); TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } }
=================================================================================================================================================================
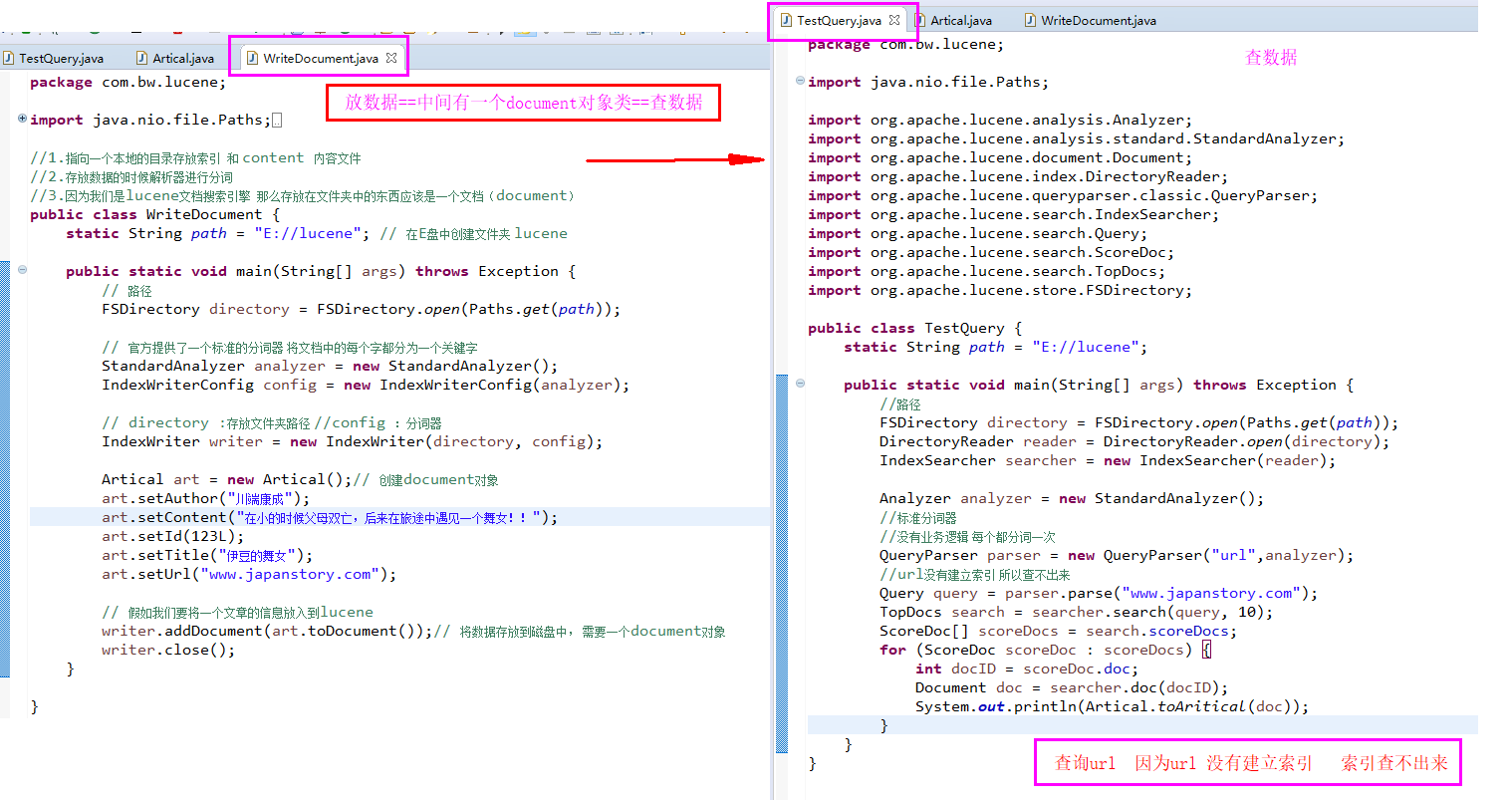
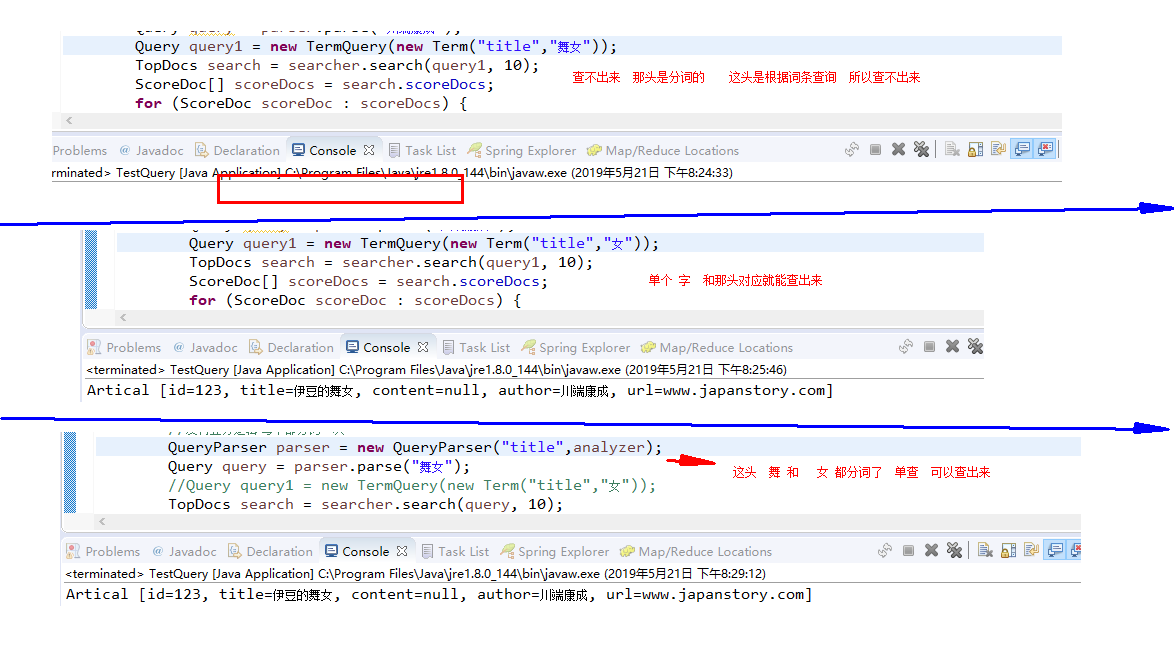
1.按分词查询的


=========================================================================================================================================
2.按范围查询
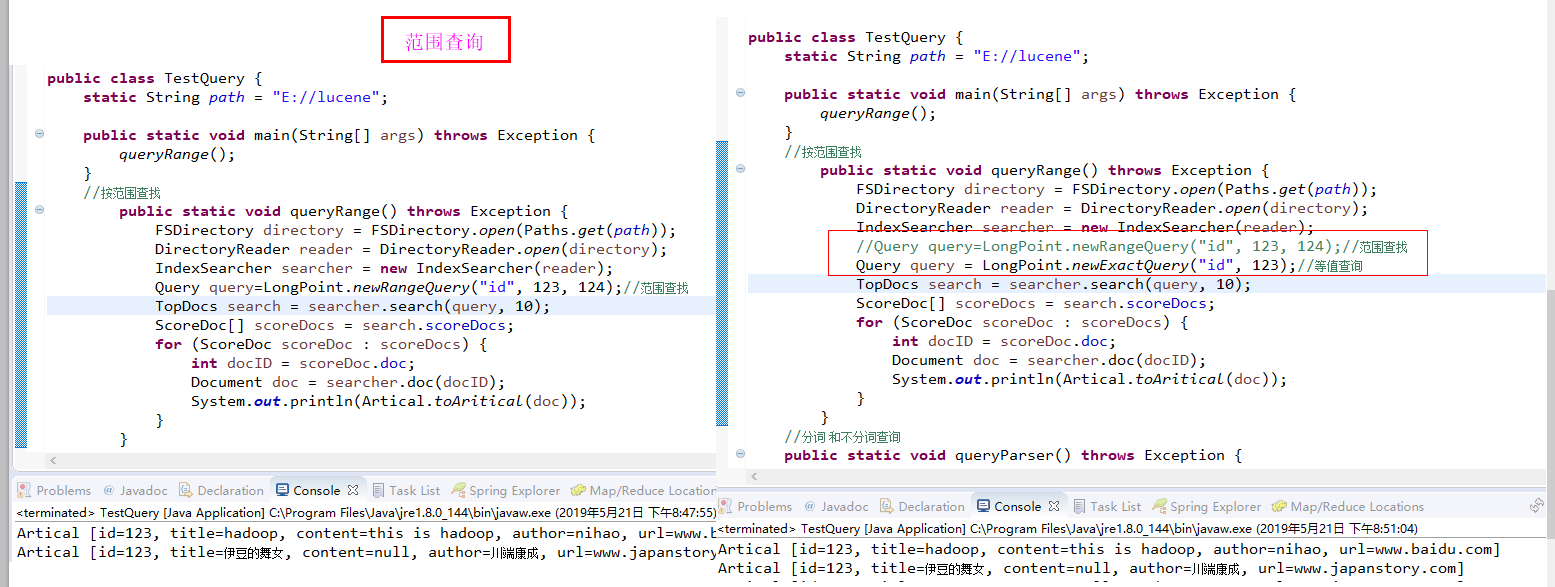
3.查询所有
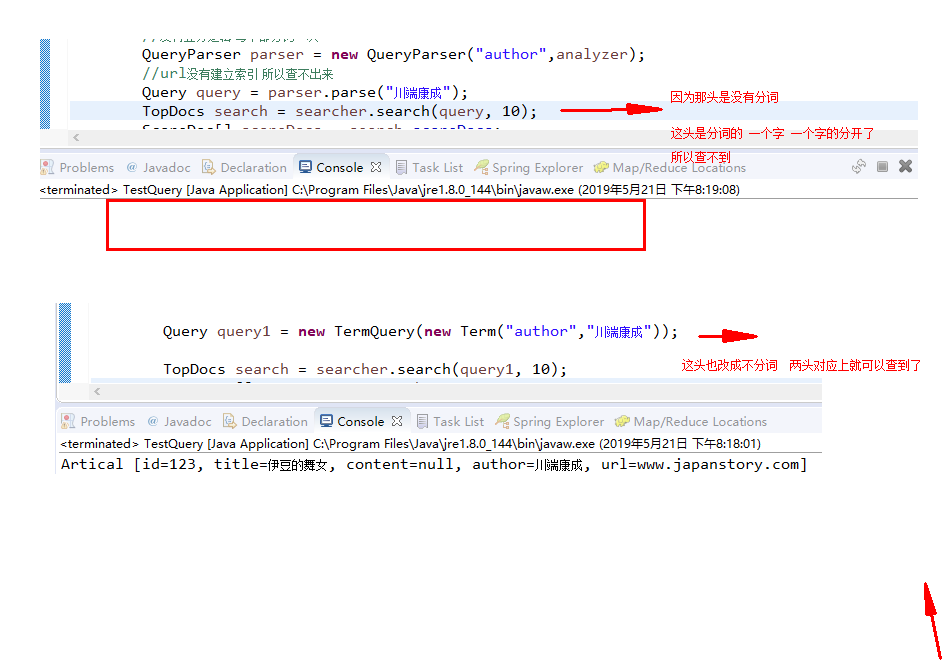
package com.bw.lucene; import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.document.LongPoint; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.Term; import org.apache.lucene.queryparser.classic.MultiFieldQueryParser; import org.apache.lucene.queryparser.classic.QueryParser; import org.apache.lucene.search.BooleanClause; import org.apache.lucene.search.BooleanQuery; import org.apache.lucene.search.IndexSearcher; import org.apache.lucene.search.MatchAllDocsQuery; import org.apache.lucene.search.Query; import org.apache.lucene.search.ScoreDoc; import org.apache.lucene.search.TermQuery; import org.apache.lucene.search.TopDocs; import org.apache.lucene.store.FSDirectory; public class TestQuery { static String path = "E://lucene"; public static void main(String[] args) throws Exception { //booleanQuery(); Query001(); } //条件查询 //多个条件 有hadoop 或者女的 public static void Query001() throws Exception { FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Analyzer analyzer = new StandardAnalyzer(); QueryParser parser = new QueryParser("title", analyzer); Query query = parser.parse("title:hadoop or title:女");//多个条件 有hadoop 或者女的 TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } //多条件查询 booleanQuery public static void booleanQuery() throws Exception { FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Analyzer analyzer = new StandardAnalyzer(); String fields[] = {"title","content"}; QueryParser parser = new MultiFieldQueryParser(fields, analyzer); Query query = parser.parse("hadoop女陆"); TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } //条件查询 multiQuery() public static void multiQuery() throws Exception { FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Query query = new TermQuery(new Term("content","女")); Query query1 = new TermQuery(new Term("content","仙")); BooleanClause clause = new BooleanClause(query,BooleanClause.Occur.MUST); BooleanClause clause1 = new BooleanClause(query1,BooleanClause.Occur.MUST_NOT); BooleanQuery bquery = new BooleanQuery.Builder().add(clause).add(clause1).build(); TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } //查询所有 public static void queryAll() throws Exception { FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Query query = new MatchAllDocsQuery(); TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } //按范围查找 public static void queryRange() throws Exception { FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); //Query query=LongPoint.newRangeQuery("id", 123, 124);//范围查找 Query query = LongPoint.newExactQuery("id", 123);//等值查询 TopDocs search = searcher.search(query, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } //分词 和不分词查询 public static void queryParser() throws Exception { //路径 FSDirectory directory = FSDirectory.open(Paths.get(path)); DirectoryReader reader = DirectoryReader.open(directory); IndexSearcher searcher = new IndexSearcher(reader); Analyzer analyzer = new StandardAnalyzer(); //标准分词器 //没有业务逻辑 每个都分词一次 QueryParser parser = new QueryParser("author",analyzer); //url没有建立索引 所以查不出来 Query query = parser.parse("川端康成"); Query query1 = new TermQuery(new Term("title","舞女")); TopDocs search = searcher.search(query1, 10); ScoreDoc[] scoreDocs = search.scoreDocs; for (ScoreDoc scoreDoc : scoreDocs) { int docID = scoreDoc.doc; Document doc = searcher.doc(docID); System.out.println(Artical.toAritical(doc)); } } }